Abstract
In this blog, we demonstrate multi-deep-learning models that can complement together to form a speech-to-image solution. We have built over Stable Diffusion Model and utilized Amazon Transcribe and Amazon Translate to shape our solution. Once an mp3 recording is uploaded into S3, a lambda function will call Amazon Transcribe to transcribe the recording (speech-to-text), then it will call Amazon Translate to translate the transcribed text (text-to-text), and finally, it will invoke the HuggingFace model deployed on SageMaker to generate an image from the translated text (text-to-image) that is also uploaded to the specific sub-bucket.
Some Results




Overview
Text to image in artificial intelligence is the generation of images based on a given prompt. It requires a prominent level of natural language processing and image generation. Text deciphering to generate images is a major field in AI and still a work in progress as real image collection and processing is expensive.
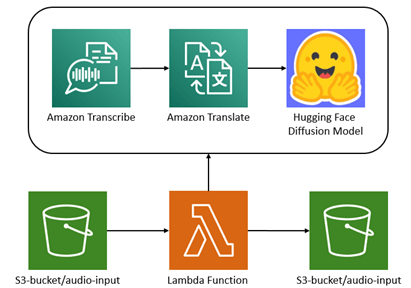
Once an mp3 recording is uploaded into the S3 a lambda function will call Amazon Transcribe to transcribe the recording (speech-to-text), then it will call Amazon Translate to translate the transcribed text (text-to-text), and finally, it will invoke the HuggingFace model deployed on SageMaker to generate an image from the translated text (text-to-image) that is also uploaded to the specific sub-bucket.
Stable Diffusion
The algorithm used is Stable Diffusion by hugging face, a data science platform that provides tools that enable users to build, train, and deploy ML models based on open-source code and technologies. Stable Diffusion is a latent diffusion model, a variety of generative neural network that was developed by Stability AI. It was trained on pairs of images and captions taken from LAION-5B (a dataset of 5.85 billion CLIP-filtered image-text pairs). Stable Diffusion is a latent text-to-image diffusion model capable of generating photo-realistic images given any text input, cultivates autonomous freedom to produce incredible imagery, empowers billions of people to create stunning art within seconds.
The Lambda Function
The Lambda function is developed to call the deep learning models and complement their responses. There are three main models executed in this lambda. Each model execution code will be shown in detail after this section.
The Lambda function code is as follows:
import json
import boto3
from transcribe import transcribe_mp3
from translate import translate_text
from hf_model import generate_images
from upload2s3 import upload_file
client = boto3.client ( 's3' )
def lambda_handler(event, context):
#parse out the bucket & file name from the event handler
for record in event['Records']:
file_bucket = record['s3']['bucket']['name']
file_name = record['s3']['object']['key']
object_url = 'https://s3.amazonaws.com/{0}/{1}'.format(file_bucket, file_name)
transcribed_text = transcribe_mp3(file_name, object_url)
translated_text = translate_text(transcribed_text)
generated_images = generate_images(translated_text, 2)
for i, img in enumerate(generated_images):
img_name = f'{translated_text.replace(" ", "_").replace(".","")}-{i}.jpeg'
img_path = "/tmp/" + img_name
img.save(img_path)
upload_file(
file_name=img_path,
bucket='', # enter the s3 bucket name
object_name='result/' + img_name
)
return "lambda handled Successfully!"
Transcribe Model
For this purpose, Amazon Transcribe was used. It is an automatic speech recognition service that uses deep learning models to convert audio to text.
The code includes boto3 library which allows us to access AWS services, it is as follows:
import json, boto3
from urllib.request import urlopen
import time
transcribe = boto3.client('transcribe')
def transcribe_mp3(file_name, object_url):
response = transcribe.start_transcription_job(
TranscriptionJobName=file_name.replace('/','')[:10],
LanguageCode='ar-AE',
MediaFormat='mp3',
Media={
'MediaFileUri': object_url
})
while True :
status = transcribe.get_transcription_job(TranscriptionJobName='audio-rawV')
if status['TranscriptionJob']['TranscriptionJobStatus'] in ['COMPLETED','FAILED']:
break
print('In Progress')
time.sleep(5)
load_url = urlopen(status['TranscriptionJob']['Transcript']['TranscriptFileUri'])
load_json = json.dumps(json.load(load_url))
text = str(json.loads(load_json)['results']['transcripts'][0]['transcript'])
return text
Translate Model
In order to make the application more diverse for users around the world, Amazon Translate was used. It’s a neural machine translation service that uses deep learning models to deliver fast and high-quality language translation. After integration, the user can enter the prompt in any language, and AWS Translate will transform it to English language as the algorithm requires. The implementation uses Boto3 library, that connects the code written on SageMaker to AWS Translate service. Then, an input is required and translated to English, and finally saved as the prompt variable.
The code used is as following:
import boto3, json
translate = boto3.client ('translate')
def translate_text(text):
result = translate.translate_text(
Text = text,
SourceLanguageCode = "auto",
TargetLanguageCode = "en")
prompt = result["TranslatedText"]
return prompt
Hugging Face Model
To deploy the HuggingFace Model, you can easily just follow the steps provided by Phil Schmid in his blog entitled “Stable Diffusion on Amazon SageMaker”. Once the model is deployed, you can note the SageMaker Endpoint name that we are going to invoke through our lambda code.
The code to invoke the SageMaker Endpoint is as follows:
import os, io, boto3, json, csv
from io import BytesIO
import base64
from PIL import Image
ENDPOINT_NAME = '' # enter your ENDPOINT_NAME
runtime= boto3.client('sagemaker-runtime')
# helper decoder
def decode_base64_image(image_string):
base64_image = base64.b64decode(image_string)
buffer = BytesIO(base64_image)
return Image.open(buffer)
def generate_images(prompt, num_images_per_prompt):
data = {
"inputs": prompt,
"num_images_per_prompt" : num_images_per_prompt
}
payload = json.dumps(data, indent=2).encode('utf-8')
response = runtime.invoke_endpoint(EndpointName=ENDPOINT_NAME,
ContentType='application/json',
Body=payload)
response_decoded = json.loads(response['Body'].read().decode())
decoded_images = [decode_base64_image(image) for image in response_decoded["generated_images"]]
return decoded_images





Top comments (2)
Hello ! Don't hesitate to put colors on your
codeblocklike this example for have to have a better understanding of your code 😎Thank youu !!