
Why I need that?
I'm responsible for all the technical stuff at the ScrapingAnt. We're providing a highly scalable web scraping API. One of the recent tasks was to discover possible variants of covering high demand for headless Chrome instances for a short time (handle burstable workload). And AWS Lambda looks like a great tool for this task.
At the end of 2020, AWS introduced Container Image Support for Lambda service. You can build your image based on any Linux distribution or using base images provided by Amazon. Previously there were no options for custom runtime in AWS Lambda, and additional binaries had to be added using Lambda layers. It was hard to develop, test, and deploy. Container support solves all these problems, and I decided to give it a try.
What are we going to do in this article
We will create and deploy a simple Lambda function based on a custom docker image and investigate the performance of this solution.
Our Lambda function will get an URL as an input and return text from the rendered webpage as output. You can use it for web scraping, testing, and monitoring websites, especially when content is rendered via javascript.
The code part
Basically, it does the following steps:
- launch browser
- create a new tab
- open URL (provided as input) in this tab, and wait for load
- extract text from page
- close tab and browser
- return the extracted text
const puppeteer = require('puppeteer');
async function lambdaHandler(event, context) {
const browser = await puppeteer.launch({
executablePath: '/usr/bin/chromium',
headless: true,
dumpio: true, // pass chrome logs to output, helps a lot if launch fails
args: [
'...some args passed to chrome'
],
});
const page = await browser.newPage();
let extractedText = '';
try {
await page.goto(event.url, {
waitUntil: 'networkidle0',
timeout: 10 * 1000,
});
extractedText = await page.$eval('*', (el) => el.innerText);
} finally {
await page.close();
await browser.close();
}
return extractedText;
}
module.exports = { handler: lambdaHandler };
You can check the full code in the git repo. It contains all flags needed to launch the browser and AWS X-Ray integration to measure performance.
Building custom docker image for Lambda
Let's build a custom Docker image to fully control the runtime environment, dependencies, and browser version.
This dockerfile is based on Google recommendations on how to pack puppeteer in docker. Also, we need to install aws-lambda-ric to make our image compatible with AWS Lambda.
FROM node:14-buster
# Install Chromium
RUN apt-get update \
&& apt-get install -y chromium fonts-ipafont-gothic fonts-wqy-zenhei fonts-thai-tlwg fonts-kacst fonts-freefont-ttf libxss1 \
--no-install-recommends \
&& rm -rf /var/lib/apt/lists/*
# Install aws-lambda-ric build dependencies
RUN apt-get update && \
apt-get install -y \
g++ \
make \
cmake \
unzip \
libcurl4-openssl-dev
WORKDIR /code-and-deps
# Install nodejs dependencies, and create user (to run chromium from non-root user)
ENV PUPPETEER_SKIP_CHROMIUM_DOWNLOAD true
RUN npm install aws-lambda-ric puppeteer@8.0.0 \
&& groupadd -r pptruser && useradd -r -g pptruser -G audio,video pptruser \
&& mkdir -p /home/pptruser/Downloads \
&& chown -R pptruser:pptruser /home/pptruser \
&& chown -R pptruser:pptruser /code-and-deps
COPY src/app.js /code-and-deps/app.js
USER pptruser
ENTRYPOINT ["/usr/local/bin/npx", "aws-lambda-ric"]
CMD ["app.handler"]
Checking on the local environment
There is a special tool to test AWS Lambda images locally. It's called AWS Lambda Runtime Interface Emulator (RIE). You have two options: include RIE in your image or install it locally. We don't need it in the production image, so let's choose the second option. We will download binary locally and mount it to our image if we need to test it.
mkdir -p ~/.aws-lambda-rie
curl -Lo ~/.aws-lambda-rie/aws-lambda-rie https://github.com/aws/aws-lambda-runtime-interface-emulator/releases/latest/download/aws-lambda-rie
chmod +x ~/.aws-lambda-rie/aws-lambda-rie
Launching container:
docker run --rm \
-v ~/.aws-lambda-rie:/aws-lambda \
-p 9000:8080 \
--entrypoint /aws-lambda/aws-lambda-rie \
lambda-custom \
/usr/local/bin/npx aws-lambda-ric app.handler
And testing that everything works fine:
➜ ~ curl -XPOST "http://localhost:9000/2015-03-31/functions/function/invocations" -d '{"url": "https://example.com"}'
"Example Domain\n\nThis domain is for use in illustrative examples in documents. You may use this domain in literature without prior coordination or asking for permission.\n\nMore information..."%
Deploy
First, we have to upload our production image to ECR (Docker Registry managed by AWS).
After that, we will use AWS SAM to deploy the function. The configuration of our deployment is described in the YAML file:
AWSTemplateFormatVersion: '2010-09-09'
Transform: AWS::Serverless-2016-10-31
Description: lambda_chrome_in_docker_research
Globals:
Function:
Timeout: 60
Resources:
LambdaExecutorFunction:
Type: AWS::Serverless::Function
Properties:
PackageType: Image
FunctionName: lambda-custom
ImageUri: paste_your_ecr_image_uri_here
MemorySize: 2048
Tracing: Active
To deploy our Lambda function, we have to perform few steps:
- Create an S3 bucket to store our application template
- Create an ECR repository to store docker image
- Log in to and push the image to the ECR repository
- Deploy our Lambda using AWS SAM
You can find the full deploy bash script in the git repo containing all code and automation from this article.
Performance
Let's test our Lambda. We can trigger it in the AWS console. Here are performance results for the first cold start run:

Wow, that's unexpectedly slow! Let's trigger it one more time to check how warmed-up lambda works:
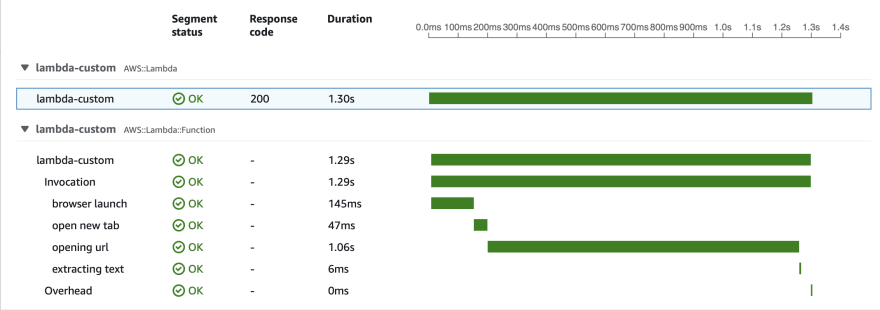
We can see that the first time our function starts in a few seconds, but then it launches the browser and opens a new tab. And it takes about 20 seconds. Second-time browser launch is so much faster! But why?
The answer is hidden in the specifics of the Lambda filesystem. When Lambda launches, it doesn't load the whole docker image to the instance it's running on. AWS engineers decided to load only needed chunks of data from the image when it's needed. So the container starts fast, but if you need to access big files from your image, they will be loaded over the network, probably from ECR.
They are multiple layers of file system cache, but it won't help us for the first run. Also, the cache gets invalidated after some time, and the story repeats. If we need to handle burst load, hundreds of Lambdas will be launched simultaneously, and all of them will perform poorly.
You can find more details about Lambda filesystem architecture and cache in AWS re:Invent video dedicated to Lambda security and internal arrangement.
How to improve first start response time
We have to decrease the amount of data loaded from ECR on the first call. First, we will use the base image provided by AWS, as it's already cached on their file system. Secondly, if the size of chrome binary and dependencies decrease, they will be loaded faster from disk.
For example, we can use chrome-aws-lambda binaries. They were built to fit Lambda layers, so the size is much smaller than regular chrome installation.
Here is the new Dockerfile:
FROM public.ecr.aws/lambda/nodejs:14
RUN npm install chrome-aws-lambda@8.0.2 puppeteer-core@8.0.0
COPY src/* ${LAMBDA_TASK_ROOT}
CMD [ "app.handler" ]
Also, we have to change a few lines of code to use chrome provided by the chrome-aws-lambda library:
const chromium = require('chrome-aws-lambda');
const browser = await chromium.puppeteer.launch({
args: chromium.args,
defaultViewport: chromium.defaultViewport,
executablePath: await chromium.executablePath,
headless: chromium.headless,
});
Deploy steps are the same as for the custom image.
The image size decreased from 1.48GB to 580MB. Also, we used the base image provided by AWS, so most of our image is always pre-cached on servers that will run our Lambda.
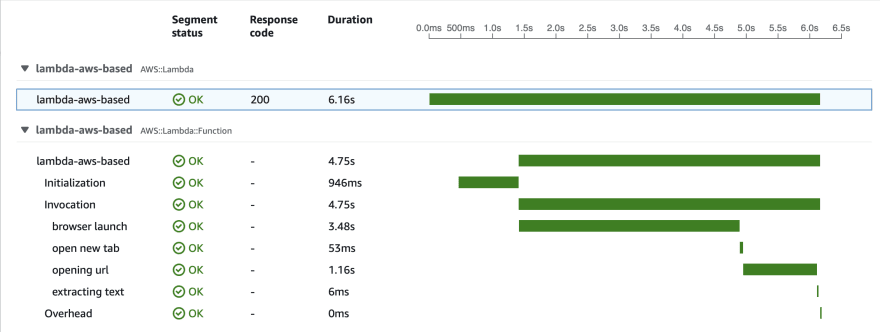
Let's test performance.
Cold start:
Warmed up:
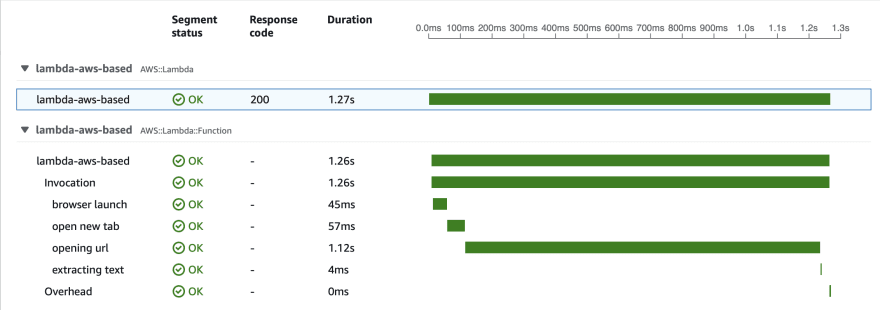
As we can see, the cold start run is much faster, and consequent runs are the same as for the custom image.
Conclusion
AWS Lambda currently supports images up to 10GB size, but you can have performance problems if you actually use huge images. The only scenario I see for big images is if you don't need a lot of data from the docker image on each call. Or if you don't care about response latency(but you pay for every second Lambda is blocked by slow disk io). So, keep your image sizes low.
If cold start performance is not a problem for your architecture, the custom images are perfect. You can control all dependencies and libraries and easily reproduce the service locally or in any environment supporting docker (Kubernetes cluster, docker swarm, etc.). So the vendor lock is minimized, and the flexibility is great.
I used aws-xray-sdk node.js library for tracing purposes, and it was excruciating. I've spent a lot of time making it work on production and not to fail locally. Avoid this library if you have any alternatives.
Links
- Full source code used in this article https://github.com/ScrapingAnt/aws-lambda-docker-research
- AWS re:Invent explanation how Lambda filesystem works https://youtu.be/FTwsMYXWGB0?t=1086
- Google Developers tips on how to run puppeteer in Docker https://developers.google.com/web/tools/puppeteer/troubleshooting#running_puppeteer_in_docker
- Example of Puppeteer on Lambda with a Docker Container https://github.com/VikashLoomba/AWS-Lambda-Docker





Top comments (3)
This is awesome. Thank you
Nice job!
stackoverflow.com/questions/696975...
I am stuck at this issue while following this guide