If VS code had a data-centric sibling, what would it look like?
Introduction
We’re just about to launch our software as open-source software, and with that want to show why we built that software.
After reading this blog, you’ll have seen some new perspectives about building training data (mainly for NLP, but the concepts are also somewhat agnostic).
Training data will become a software artifact
We talked extensively about software 1.0 and software 2.0 in the last few years. In a nutshell, it is about how AI-backed software contains training data next to the algorithms to make predictions. We love this saying because it defines that the data is part of the software. This has some profound implications:
There are two ways to build AI software: model-centric and data-centric. You can focus not only on the algorithms to implement the software but also on the data itself.
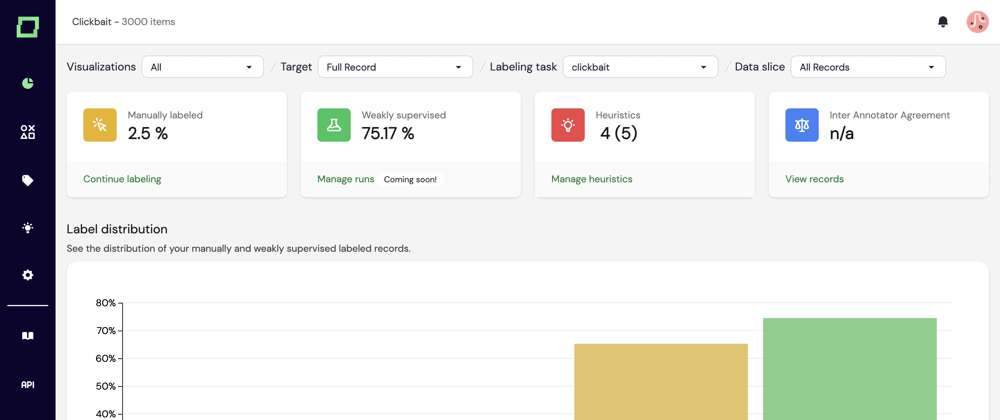
Software needs to be documented. If data is part of the software, it can’t be treated poorly. And this starts with label definitions, known inter-annotator agreements, versions, and some documentation about how labels have been set (i.e., turning the labeling procedure black box into some explainable instrument).
Labeling is not a one-time job. If it is part of the software, you’ll work on it daily. And for that, you need some excellent tooling.
We’re betting that such tasks require a data-centric development environment. To make things like labeling or cleansing data (especially in NLP) much more straightforward. That is why we’ve built Kern AI. In more detail, we constantly have the following two questions in mind:
What is needed so developers and data scientists can create something from scratch much faster?
What is required, such that developers and data scientists can improve some features continuously in a maintainable way?
In the following, we’ll go into more detail and showcase some of the features we’ve built for Version 1.0, our open-source release.
How can I prototype in a data-centric approach?
Picture this: You’ve got a brand new idea for a feature. You want to differentiate clickbait from regular titles in your content moderation. But: you only have unlabeled records and clearly don’t want to spend too much time on data labeling.
This is where our data-centric prototyping comes into play. It looks as follows:
First, you label some reference data. It can be as little as 50 records, not too much effort.
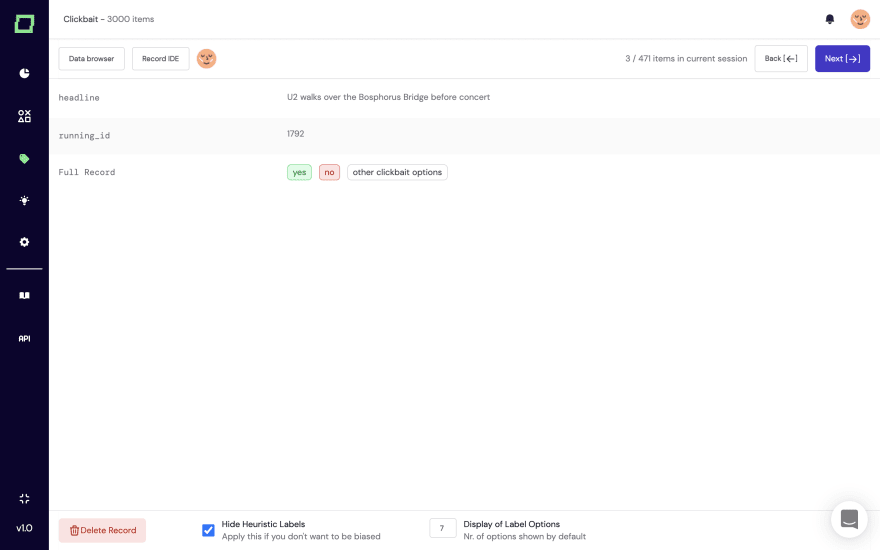
Second, with our weak supervision core (we’re explaining that technology in another post in more detail), you can build and combine both explicit heuristics such as labeling functions, as well as active transfer learning and zero-shot modules. Our application comes with an integration to the Hugging Face Hub, such that you can just easily integrate large-scale language models for your heuristics.
The heuristics are automatically validated by the reference samples you’ve labeled (of course, we’re making reasonable splits for the active learning, such that you don’t have to worry about the applicability of the statistics).
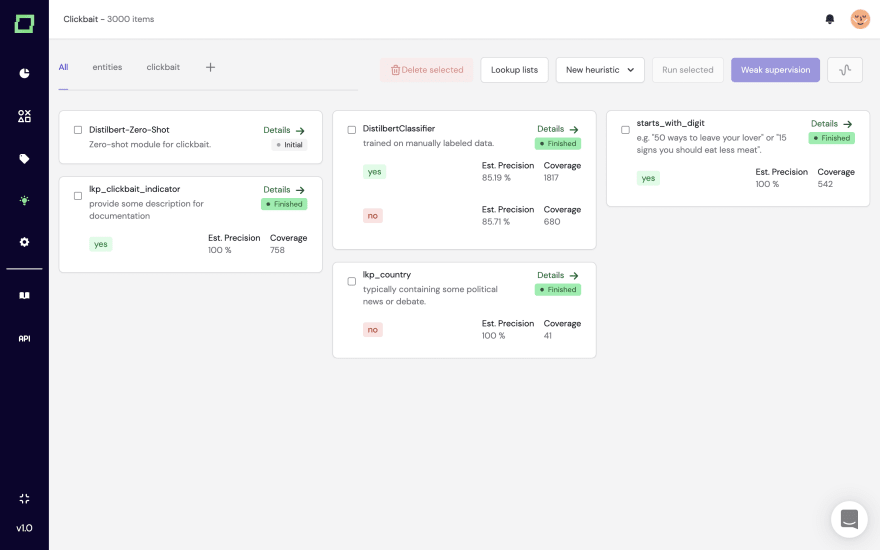
Third, you are computing weakly supervised labels. Those are continuous, i.e., have some confidence attached. Doing so typically requires seconds, so you can do this as often as you’d like.
Now, we have the first batch of weakly supervised labels. But the prototyping doesn’t stop here. We can go further. For instance, we’re seeing on the monitoring page that there are too few weakly supervised labels for clickbait data. With our integrated neural search powered by large-scale language models, we can just search for similar records of existing data we’ve labeled and find new patterns.
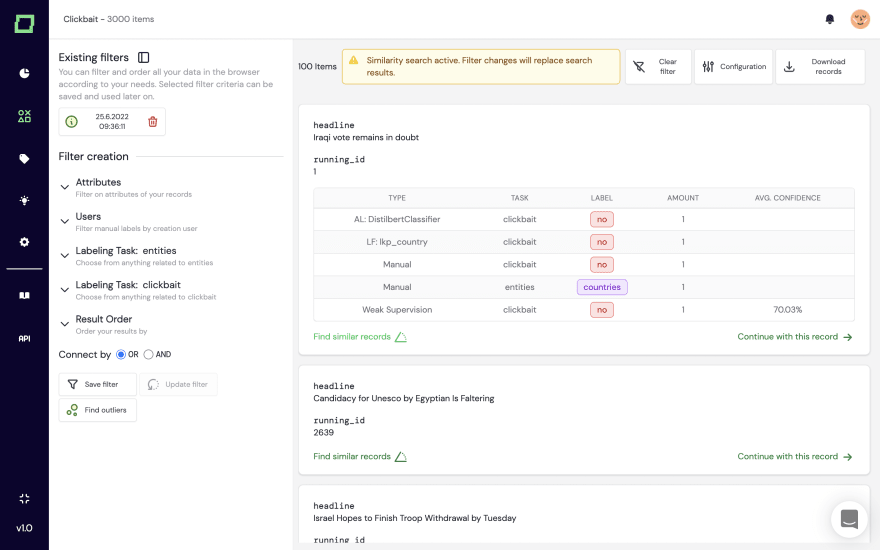
Alternatively, we can also use that data to find outliers to see where we might face issues later in the model development.
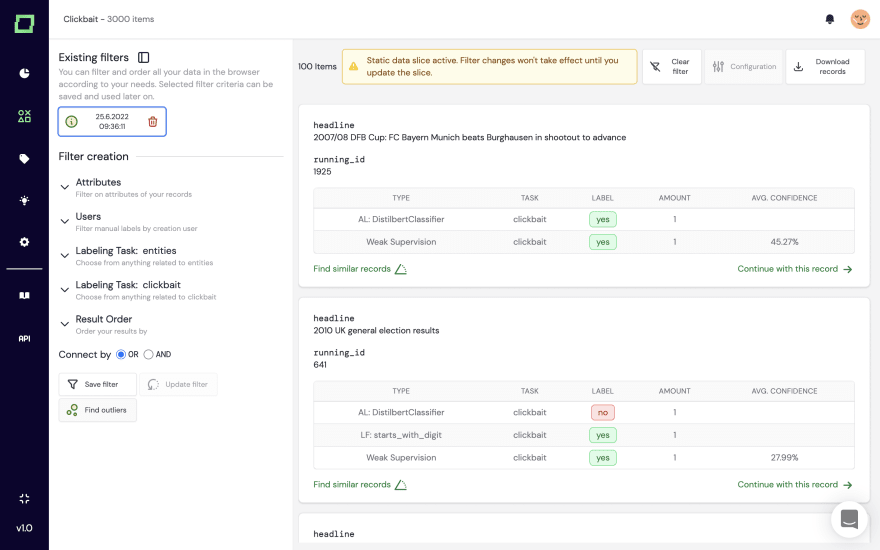
In general, this gives us a great estimation of our data, where it’s easy to make predictions, and how our data baseline looks. You can from here build a prototype using Sklearn and FastAPI within minutes.
But we don’t want to stop there, right? We want to be able to improve and maintain our AI software. So now comes the question: how can we do so?
How can I continuously improve in a data-centric approach?
You’ll quickly find that it is time to improve your model and let it learn some new patterns - and refine existing ones. The good news is that you can just continue your data project from the prototyping phase!
First, let’s look at how weak supervision comes into play for this. It comes in handy for many reasons:
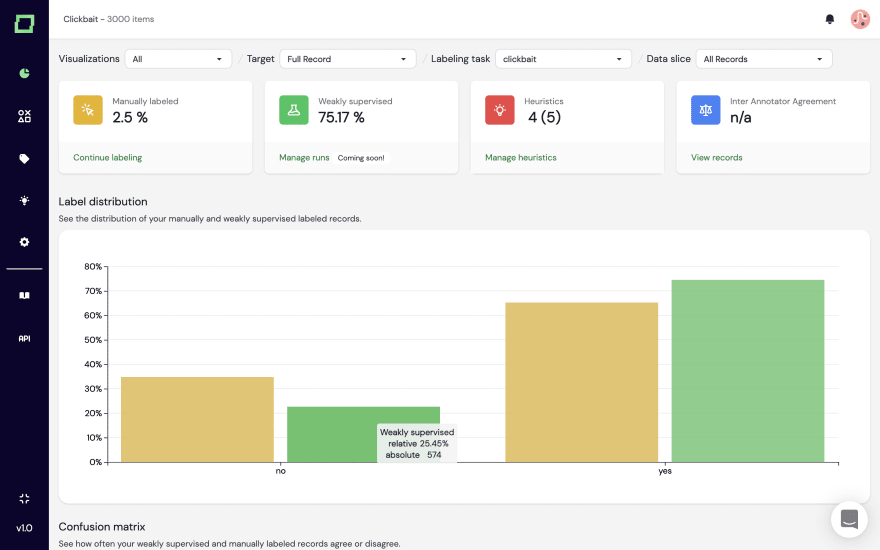
You can apply any kind of heuristic as a filter for your data and thus slice your records accordingly. Remember, this is so helpful for debugging and, in general, documentation - your raw records are enriched through the weakly supervised labels and the heuristic data in general. Use this to find weak spots in your data quality.
The weakly supervised labels are continuous, i.e., soft labels. You can sort them according to your needs. If you want to find potential manual labeling errors, you can sort by the label confidence descending and filter for mismatches in manual and weakly supervised labels. Voilá, those are most likely manual labeling errors. Alternatively, you can sort ascending and thus find potential weak spots of your weak supervision, helping you debug your data.
We have also built certain quality-of-life features to make it as easy for you to extend your heuristics with ease. For instance, if you label spans in your data, we can automatically generate lookup lists that you can use, for example, in labeling functions. This way, you only write your labeling function once but can extend it continuously.
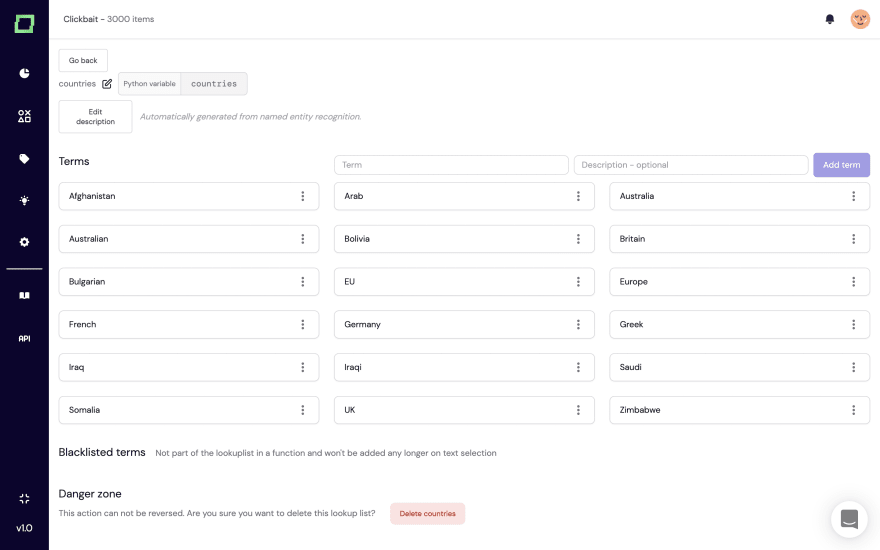
Also, as you continue to label data manually, your active transfer learning modules will improve over time, making it even easier for you to find potential mislabeled data or weak spots.
Lastly, the whole application comes with three graphs for quality monitoring. We’ll showcase one, the inter-annotator agreement, which is automatically generated when you label data with multiple annotators. It shows users' potential disagreement, which we’ll also integrate into the heuristics. Ultimately, this helps you understand what human performance you can measure against and where potential bias is.

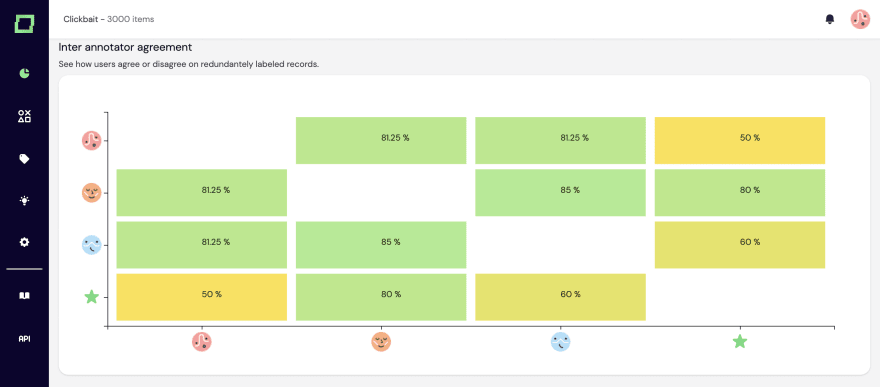
There is so much more to come
This is our version 1.0. What we built is the result of many months of closed beta, hundreds of discussions with data scientists, and lots of coffee (as usual ;-)). We’re super excited but can already tell you that there is much more to come. Following features will include, for instance, feature programming or extensive prompt engineering in the zero-shot modules, as well as no-code templates for recurring labeling functions. Stay tuned, and let us know what you think of the application. We couldn’t be more excited!
We’re going open-source, try it out yourself
Ultimately, it is best to just play around with some data yourself, right? Well, we’re launching our system soon that we’ve built for more than the past year, so feel free to install it locally and play with it. It comes with a rich set of features, such as integrated transformer models, neural search and flexible labeling tasks.
Subscribe to our newsletter 👉🏼 https://www.kern.ai/pages/open-source, stay up to date with the release so you don’t miss out on the chance to win a GeForce RTX 3090 Ti for our launch! :-)





Latest comments (0)