Certain automated attack discovery tools, such as 🎹KORG, 🐍SNAKE, or 🧰TCPwn, are designed specifically to ensure that network protocols operate correctly and securely. Such tools generally require a formal representation of the protocol, e.g., a finite state machine (FSM), as well as a formal description of message formats and correctness properties.
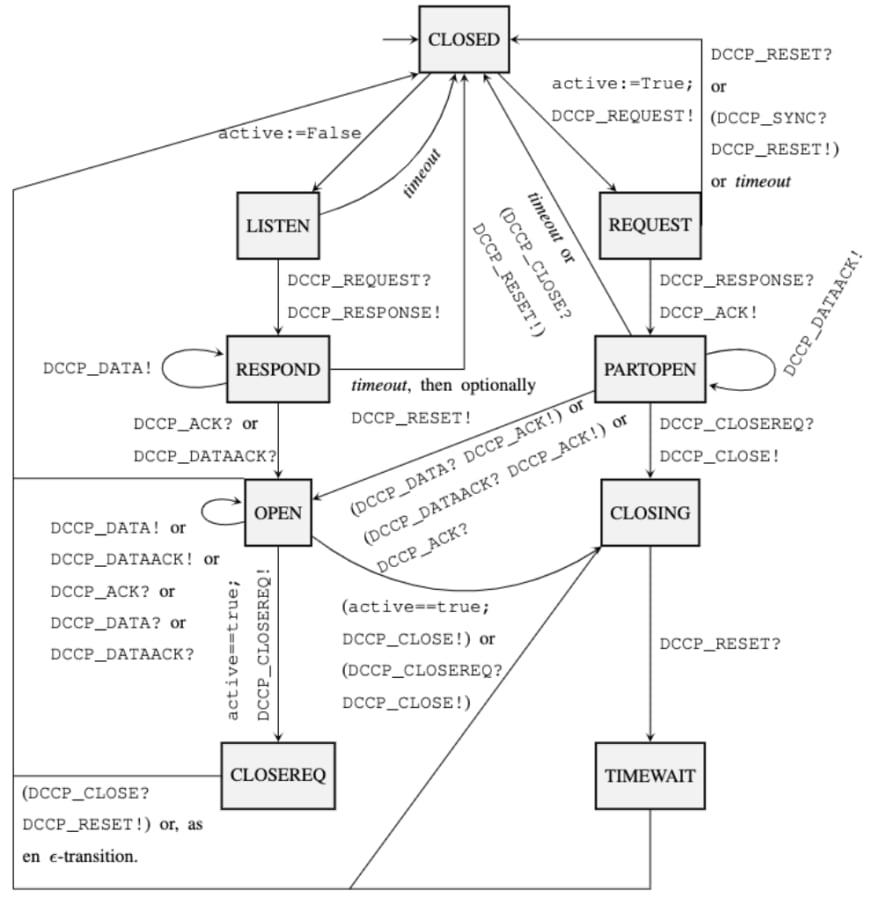
| TCP FSM | DCCP FSM |
|---|---|
 |
 |
Formal protocol specifications can be extracted from two sources: implementations or textual descriptions.


Many prior works extracted FSMs, message formats, or correctness properties from protocol implementations. For example, 🤖Prospex extracted state machines from implementations by running them and examining their network traces. We are interested in the alternative approach of extracting protocol specifications from textual descriptions.
Network protocols are usually described prosaically in plain-text English-language documents, such as the IETF "Request For Comments" documents, or RFCs. In prior work, we showed how to extract protocol message formats from RFC documents, with grammar-based fuzzing as our motivating use-case. However, implementing an RFC FSM also requires significant human labor and expertise.
In this work, we try to alleviate this human burden by partially automating the process of FSM extraction, with attacker synthesis as our motivating use-case. Our paper will appear in the 2022 IEEE S&P, and our code is open-source and reproducible.
Challenges
In order to extract an FSM from a protocol RFC, we need to first read the protocol RFC. But what does reading the RFC mean, exactly, in an automated context? In our work, it meant analyzing the RFC document using natural language processing, a sub-field of AI concerned with interpreting human language. This approach came with some built-in challenges.
- Defining the Problem. Traditional NLP semantic parsing studies methods for translating natural language into a complete formal representation. However, RFCs do not contain "canonical" or "reference" FSMs. They have mistakes, omissions, and ambiguities which are solved as-needed by human experts. Even in theory, there is no complete one-to-one mapping from RFCs to FSMs.
- Choosing an NLP Approach. Many off-the-shelf NLP tools exist, typically trained on newswire text. But when such tools are applied to technical domains their performance degrades substantially. Meanwhile, training rule-based systems from scratch requires significant human effort to label the data, and will yield poor results on RFCs because different RFC documents define variables, constraints, and temporal behaviors totally differently.
Our Approach
First, we learn a large-scale word representation for technical language using off-the-shelf tools. Second, we define and learn protocol-independent information from RFCs, using focused zero-shot learning to adapt to new, unobserved protocol documents without re-training. Third, we use a rule-based mapping from the protocol-independent information to FSMs. Fourth, we show how the resulting FSMs can then be used for attacker synthesis - although notice that these FSMs could alternatively be used for other applications, such as grammar-based fuzzing. Let's go over each of these steps in detail below.

1. Learning a Large-Scale Word Representation
We collect a corpus of RFC-related documents such as technical forums, blogs, research papers, and specification documents. We exploit these documents to learn a distributed word representation, also known as an embedding model, for technical language. In particular, we use a BERT embedding model, pre-trained using the masked language model and the next sentence prediction objective using networking data. This process does not require any manual annotation!
2. Zero-Shot Protocol Extraction
Once we have this representation, we turn our attention to learning a model to extract information regarding an FSM from its RFC. Specifically, we want to structurally annotate the protocol RFC, so that we know precisely which parts of the text describe different states, transitions, variables, errors, etc. in the protocol logic. To do this, we define a grammar that describes a higher-level abstraction of the structure of a general FSM for network protocols, as well as the structure of the RFC document describing the FSM.
bool ::= true | false
type ::= send | receive | issue
def-tag ::= def_state | def_var | def_event
ref-state ::= ref_state id="##"
ref-event ::= ref_event id="##" type="type"
ref-tag ::= ref-event | ref-state
def-atom ::= <def-tag>engl</def-tag>
sm-atom ::= <ref-tag>engl</ref-tag> | engl
sm-tag ::= trigger | variable | error | timer
act-atom ::= <arg>sm-atom</arg> | sm-atom
act-struct::= act-struct | act-struct act-atom
trn-arg ::= arg_source | arg_target | arg_inter
trn-atom ::= <trn-arg>sm-atom<trn-arg> | sm-atom
trn-struct::= trn-struct | trn-struct trn-atom
ctl-atom ::= <sm-tag>sm-atom</sm-tag>
| <action type="type">act-struct</action>
| <transition>trn-struct</transition>
| sm-atom
ctl-struct::= ctl-atom | ctl-struct ctl-atom
ctl-rel ::= relevant=bool
control ::= <control ctl-rel>ctl-struct</control>
e ::= control | ctl-atom | def-atom | e_0 e_1
The grammar is general-purpose and intended to support any network protocol. At a high level, it consists of:
- Definition tags, used to define states, transitions, etc.;
- Reference tags, used to observe mentions of previously defined data;
- State Machine tags, used to track states and transitions; and
- Control flow tags, used to record the syntactic structure of the RFC document.
For example, consider the following snippet from the Datagram Congestion Control Protocol RFC:
The client leaves the REQUEST state for PARTOPEN when it receives a DCCP-Response from the server.
We can annotate this snippet like so:
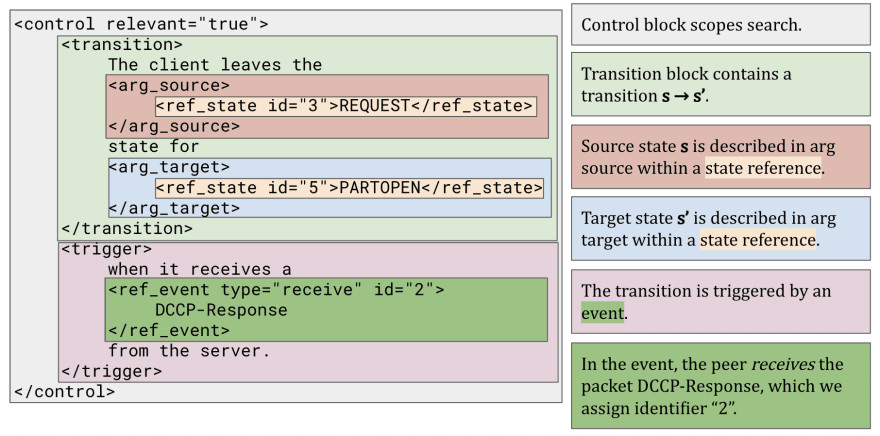
Now we know where to look in the RFC in order to find certain information (states, transitions, events, etc.). We call this annotated version of the RFC an "intermediate representation". For full details refer to Section III in our paper.
Annotating the RFC document by hand is almost as time-intensive as manually deriving the protocol FSM. Clearly, annotation should be automated! We experimented with several state-of-the-art NLP algorithms for this task:
-
LinearCRF- a linear-chain conditional random fields model; -
NeuralCRF- a BERT encoder enhanced with a Bidirectional LSTM CRF layer; -
LinearCRF+R- likeLinearCRFbut with some heuristic post-processing rules; and -
NeuralCRF+R- likeNeuralCRFbut with those same heuristic post-processing rules.
LinearCRF |
NeuralCRF |
|---|---|
 |
 |
We evaluate the algorithms on the BGPv4, DCCP, LTP, PPTP, SCTP, and TCP RFCs, in Section VIII (a) of our paper. Generally, we find that the neural models outperform the linear ones.
3. Protocol State Machine Extraction
Suppose we're studying the DCCP RFC, and we've produced its intermediary representation either by hand or using LinearCRF, NeuralCRF, LinearCRF+R, or NeuralCRF+R. Now that we know where to look in order to read the RFC, it's time to extract an FSM. Recall that an FSM consists of states s ∈ S, some kind of events e ∈ E, and transitions t ∈ S x E x S. We take the stance that there are four kinds of events: timeouts, epsilon-transitions (like noops), send-events, and receive-events.
Luckily, all of this data is explicitly labeled in the intermediary representation! We just need to assemble it all into an extracted FSM. Our algorithm to do exactly that is described in (a) Section VI and (b) Algorithm ExtractTran in the Appendix of our paper. You can also read the actual open-source code here. At a high level, we do the following:
- use
def_states to determine the FSM states - use
transitions to determine the transitions; for each one, search the closestcontrolblock forref_states to determine where the transition begins and ends, andref_events to determine what exactly occurs during the transition. In the example from before, the correct extracted transition would be:
REQUEST --- rcv(DCCP-Response) --> PARTOPEN
You can see the TCP and DCCP FSMs extracted by the LinearCRF+R and NeuralCRF+R NLP algorithms in the Appendix of our paper. In that same Appendix, we also give "Gold FSMs", which are extracted from RFCs that are annotated by hand. Mistakes in the Gold FSMs stem from issues in our extraction algorithm, or intrinsic ambiguities in the RFC text. We give a detailed case-by-case analysis of such mistakes for the NLP-extracted TCP and DCCP FSMs here.
4. Attacker Synthesis
Finally, we get to the attacker synthesis. Note that attacker synthesis is just one representative protocol analysis technique that uses a protocol FSM. We used the attacker synthesis tool 🎹KORG. Since KORG was designed for perfect, hand-written FSMs, we had to modify it slightly to support imperfect FSMs like those we can extract from RFCs. Our modified version is available here.
Case Studies
We use TCP and DCCP as case studies. For each protocol, we craft four hand-written correctness properties, which we feed to KORG in conjunction with the FSM. Our results are given in TABLE V and discussed in Section VIII. B of our paper. The TL;DR is that using the NLP-derived FSMs, we find one attack against TCP, which we confirm using a hand-written TCP FSM, and we find numerous attacks against DCCP, of which we confirm some but not all using a hand-written DCCP FSM. Here are some of those confirmed attacks:
- Attack #32 discovered using TCP property 1 and the
LinearCRF+RTCP FSM injects a singleACKto peer 2, causing a desynchronization between the peers which can eventually lead to a half-open connection, which should be impossible. - Attack #96 discovered using DCCP property 2 and the
NeuralCRF+RDCCP FSM performs various useless network operations before spoofing each peer in order to guide the other intoCLOSE_REQ. The two peers should never both be inCLOSE_REQat once.
Conclusion
Our work is exciting, because we take a first step toward automatically extracting FSMs (i.e. code) from RFCs (i.e. text). But it's also limited: the FSMs are imperfect, with missing or incorrect transitions, and we still have to write the correctness properties by hand. We have ideas for how to improve on our technique, which we discuss in Section X (Limitations) of our paper. In the mean time, our code is open source and reproducible. We also provide a detailed tutorial on how to use our software.





Oldest comments (2)
That's... simply awesome. Great work!
Thank you! Really appreciate it! Please let us know if you have any questions. Also, if you have time, try running the code! We think it's pretty cool and we are happy to answer questions here or on Github Issues. Thanks!