
What is it?
A web-based tool that attempts to infer your preferred settings for Prettier + ESLint and generate your config files for you.
⚠️ It is very much a work in progress
Example: https://mattkenefick.github.io/format-parser/
Github: https://github.com/mattkenefick/format-parser
How does it work?
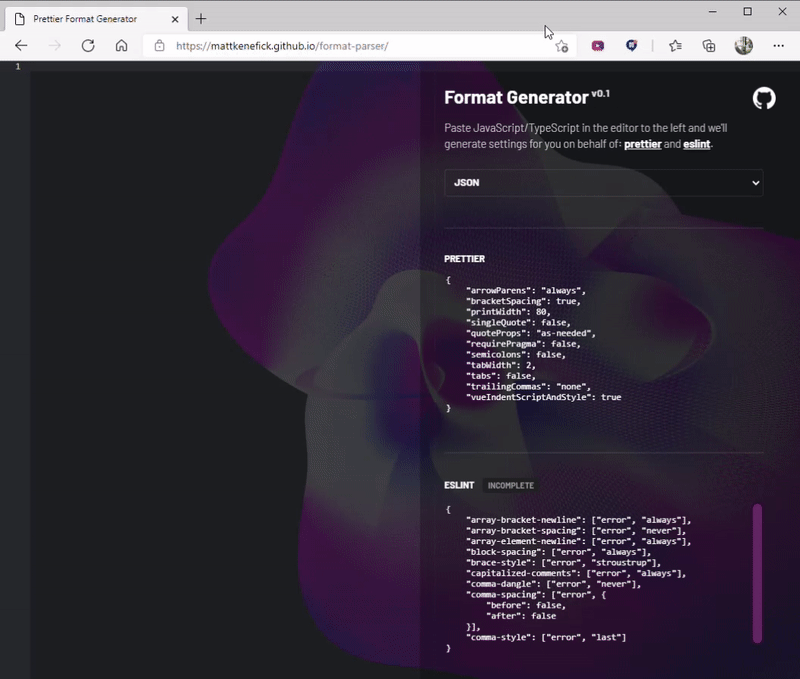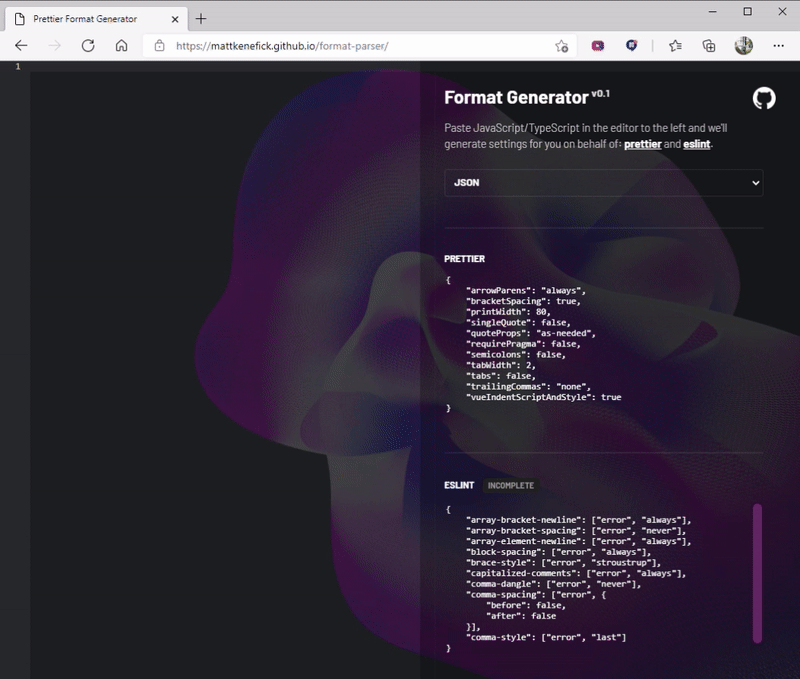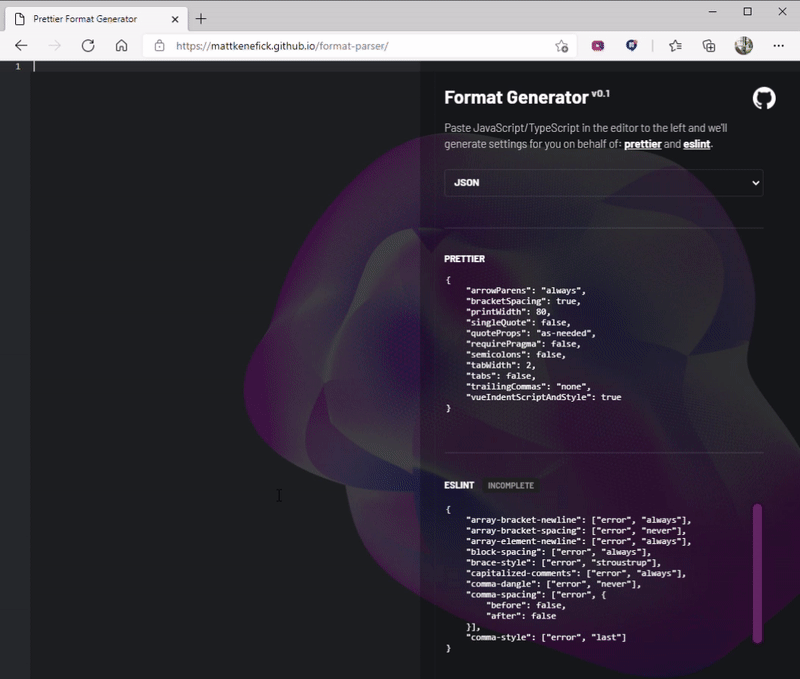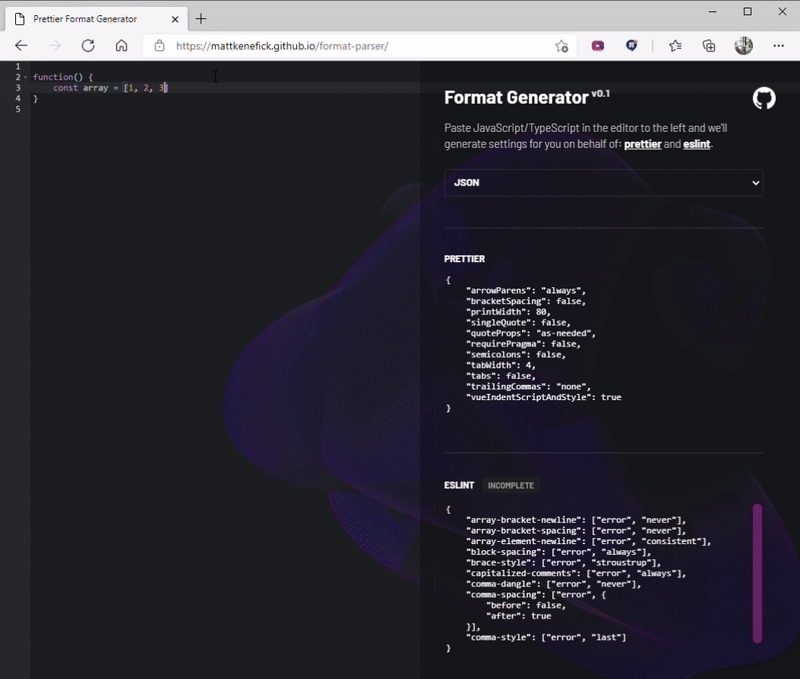
Assumptions are made using a series of regular expressions. Each rule per library (e.g. Prettier/QuoteProps) has its own class associated with it. When we change our input, it runs all of our filters to retrieve an output.
Example
import CoreRule from '../../core/rule.js';
/**
* Semicolons
*
* Print semicolons at the ends of statements
*
* @see https://prettier.io/docs/en/options.html#semicolons
*/
export default class RuleSemiColons extends CoreRule
{
/**
* @var boolean
*/
get default() {
return true;
}
/**
* @var string
*/
get property() {
return 'semicolons';
}
/**
* Mandatory entry function to create a decision
*
* @return boolean
*/
identify() {
let output = this.default;
// Find all of our semi colon line endings
const semicolons = [...this.input.matchAll(/;\s*$/gm)];
// Determine if they make up a valuable percentage of the file (5%)
output = semicolons.length / this.lines.length > 0.05;
return output;
}
}
The above class is for Pretter's SemiColon rule. It has a default value of true. The property represented in Prettier's config is semicolons. The identify function is where we attempt to make a determination about the output.
In the case above, we attempt to find all instances where a semi-colon precedes a line ending. If we at least 5% of the file uses semi-colons at the end of the line, we assume that's the preferred way to go.
The mentioned percentage is an arbitrary value and could be changed (remember "assumptions are made" from above). The assumption here is that wants to write without semi-colons will likely have next to none in their code.
More complex determinations
Some determinations are too difficult to solve with a singular regular expression. So far, I've found that a decent assumption can be made by evaluating one of three things:
A singular regular expression for the entire file (as seen above)
Iterating through individual lines of code
Iterating through braces/blocks of code
Finding the difference between function blocks vs object blocks vs array blocks can be valuable for an overall determination, like determining use of trailing commas.
Some assumptions are made by comparing two or more values, like with quotations: are there more double quotes or single quotes?
Wrapping up
I've only put about one Saturday's afternoon into this so far, but it's coming along pretty well. Some assumptions may need tweaking and there are a fair amount of ESLint rules to finish.
If you have feedback or want to contribute, checkout the Github.





Top comments (0)