Note: This was originally posted at martinheinz.dev
There are lots of great Python libraries, but most of them don't come close to what built-in itertools and also more-itertools provide. These two libraries are really the whole kitchen sink when it comes to processing/iterating over some data in Python. At first glance however, functions in those libraries might not seem that useful, so let's make little tour of (in my opinion) the most interesting ones, including examples how to get the most out of them!
Compress
Before we get to functions from more_itertools library, let's first look into few of the more obscure ones from built-in itertools module - first of them being itertools.compress:
dates = [
"2020-01-01",
"2020-02-04",
"2020-02-01",
"2020-01-24",
"2020-01-08",
"2020-02-10",
"2020-02-15",
"2020-02-11",
]
counts = [1, 4, 3, 8, 0, 7, 9, 2]
from itertools import compress
bools = [n > 3 for n in counts]
print(list(compress(dates, bools))) # Compress returns iterator!
# ['2020-02-04', '2020-01-24', '2020-02-10', '2020-02-15']
You have quite a few option when it comes to filtering sequences, one of them is also compress, which takes iterable and boolean selector and outputs items of the iterable where the corresponding element in the selector is True.
We can use this to apply result of filtering of one sequence to another like in above example, where we create list of dates where the corresponding count is greater than 3.
Accumulate
As name suggests - we will use this function to accumulate results of some (binary) function. Example of this can be running maximum or factorial:
from itertools import accumulate
import operator
data = [3, 4, 1, 3, 5, 6, 9, 0, 1]
list(accumulate(data, max)) # running maximum
# [3, 4, 4, 4, 5, 6, 9, 9, 9]
list(accumulate(range(1, 11), operator.mul)) # Factorial
# [1, 2, 6, 24, 120, 720, 5040, 40320, 362880, 3628800]
If you don't care about intermediate results, you could use functools.reduce (called fold in other languages), which keeps only final value and is also more memory efficient.
Cycle
This function takes iterable and creates infinite cycle from it. This can be useful for example in a game, where players take turns. Another cool thing you can do with cycle is to create simple infinite spinner:
# Cycling through players
from itertools import cycle
players = ["John", "Ben", "Martin", "Peter"]
next_player = cycle(players).__next__
player = next_player()
# "John"
player = next_player()
# "Ben"
# ...
# Infinite Spinner
import time
for c in cycle('/-\|'):
print(c, end = '\r')
time.sleep(0.2)
One thing you might need to do when using cycle is skipping few elements of iterable (in other words - starting at different element). You can do that with itertools.islice, so to start at third player from example above you could do: islice(cycle(players), 2, None).
Tee
Final one from itertools module is tee, this function creates multiple iterators from one, which allows us to remember what happened. Example of that is pairwise function from itertools recipes (and also more_itertools), which returns pairs of values from input iterable (current value and previous one):
from itertools import tee
def pairwise(iterable):
"""
s -> (s0, s1), (s1, s2), (s2, s3), ...
"""
a, b = tee(iterable, 2)
next(b, None)
return zip(a, b)
This function is handy every time you need multiple separate pointers to same stream of data. Be careful when using it though, as it can be pretty costly when it comes to memory. Also important to note is that you should not use original iterable after you use tee on it as it will mess up (unintentionally advance) those new tee objects.
more_itertools
Now, let's have a closer look at what more_itertools library offers, as there are many interesting functions, that you might not have heard about.
divide
First up from more_itertools is divide. As the name suggests, it divides iterable into number of sub-iterables. As you can see in example below, the length of the sub-iterables might not be the same, as it depends on number of elements being divided and number of sub-iterables.
from more_itertools import divide
data = ["first", "second", "third", "fourth", "fifth", "sixth", "seventh"]
[list(l) for l in divide(3, data)]
# [['first', 'second', 'third'], ['fourth', 'fifth'], ['sixth', 'seventh']]
There is one more similar function in more_itertools called distribute, it however doesn't maintain order. If you don't care about order you should use distribute as it needs less memory.
partition
With this function, we will be also dividing our iterable, this time however, using a predicate:
# Split based on age
from datetime import datetime, timedelta
from more_itertools import partition
dates = [
datetime(2015, 1, 15),
datetime(2020, 1, 16),
datetime(2020, 1, 17),
datetime(2019, 2, 1),
datetime(2020, 2, 2),
datetime(2018, 2, 4)
]
is_old = lambda x: datetime.now() - x < timedelta(days=30)
old, recent = partition(is_old, dates)
list(old)
# [datetime.datetime(2015, 1, 15, 0, 0), datetime.datetime(2019, 2, 1, 0, 0), datetime.datetime(2018, 2, 4, 0, 0)]
list(recent)
# [datetime.datetime(2020, 1, 16, 0, 0), datetime.datetime(2020, 1, 17, 0, 0), datetime.datetime(2020, 2, 2, 0, 0)]
# Split based on file extension
files = [
"foo.jpg",
"bar.exe",
"baz.gif",
"text.txt",
"data.bin",
]
ALLOWED_EXTENSIONS = ('jpg','jpeg','gif','bmp','png')
is_allowed = lambda x: x.split(".")[1] in ALLOWED_EXTENSIONS
allowed, forbidden = partition(is_allowed, files)
list(allowed)
# ['bar.exe', 'text.txt', 'data.bin']
list(forbidden)
# ['foo.jpg', 'baz.gif']
In the first example above, we are splitting list of dates into recent ones and old ones, using simple lambda function. For the second example we are partitioning files based on their extension, again using lambda function which splits file name into name and extension and checks whether the extension is in list of allowed ones.
consecutive_groups
If you need to find runs of consecutive numbers, dates, letters, booleans or any other orderable objects, then you might find consecutive_groups handy:
# Consecutive Groups of dates
import datetime
import more_itertools
dates = [
datetime.datetime(2020, 1, 15),
datetime.datetime(2020, 1, 16),
datetime.datetime(2020, 1, 17),
datetime.datetime(2020, 2, 1),
datetime.datetime(2020, 2, 2),
datetime.datetime(2020, 2, 4)
]
ordinal_dates = []
for d in dates:
ordinal_dates.append(d.toordinal())
groups = [list(map(datetime.datetime.fromordinal, group)) for group in more_itertools.consecutive_groups(ordinal_dates)]
In this example, we have list of dates, where some of them are consecutive. To be able to pass these dates to consecutive_groups function, we first have to convert them to ordinal numbers. Then using list comprehension we iterate over groups of consecutive ordinal dates created by consecutive_groups and convert them back to datetime.datetime using map and fromordinal functions.
side_effect
Let's say you need to cause side-effect when iterating over list of items. This side-effect could be e.g. writing logs, writing to file or like in example below counting number of events that occurred:
import more_itertools
num_events = 0
def _increment_num_events(_):
nonlocal num_events
num_events += 1
# Iterator that will be consumed
event_iterator = more_itertools.side_effect(_increment_num_events, events)
more_itertools.consume(event_iterator)
print(num_events)
We declare simple function that will increment counter every time it's invoked. This function is then passed to side_effect along with non-specific iterable called events. Later when the event iterator is consumed, it will call _increment_num_events for each item, giving us final events count.
collapse
This is a more powerful version of another more_itertools function called flatten. collapse allows you to flatten multiple levels of nesting. It also allows you to specify base type, so that you can stop flattening with one layer of lists/tuples remaining. One use-case for this function would be flattenning of Pandas DataFrame. Here are little more general purpose examples:
import more_itertools
import os
# Get flat list of all files and directories
list(more_itertools.collapse(list(os.walk("/home/martin/Downloads"))))
# Get all nodes of tree into flat list
tree = [40, [25, [10, 3, 17], [32, 30, 38]], [78, 50, 93]] # [Root, SUB_TREE_1, SUB_TREE_2, ..., SUB_TREE_n]
list(more_itertools.collapse(tree))
First one generates list of files and directory paths by collapsing iterables returned by os.walk. In the second one we take tree data structure in a form of nested lists and collapse it to get flat list of all nodes of said tree.
split_at
Back to splitting data. split_at function splits iterable into lists based on predicate. This works like basic split for strings, but here we have iterable instead of string and predicate function instead of delimiter:
import more_itertools
lines = [
"erhgedrgh",
"erhgedrghed",
"esdrhesdresr",
"ktguygkyuk",
"-------------",
"srdthsrdt",
"waefawef",
"ryjrtyfj",
"-------------",
"edthedt",
"awefawe",
]
list(more_itertools.split_at(lines, lambda x: '-------------' in x))
# [['erhgedrgh', 'erhgedrghed', 'esdrhesdresr', 'ktguygkyuk'], ['srdthsrdt', 'waefawef', 'ryjrtyfj'], ['edthedt', 'awefawe']]
Above, we simulate text file using list of lines. This "text file" contains lines with -------------, which is used as delimiter. So, that's what we use as our predicate for splitting these lines into separate lists.
bucket
If you need to split your iterable into multiple buckets based on some condition, then bucket is what you are looking for. It creates child iterables by splitting input iterable using key function:
# Split based on Object Type
import more_itertools
class Cube:
pass
class Circle:
pass
class Triangle:
pass
shapes = [Circle(), Cube(), Circle(), Circle(), Cube(), Triangle(), Triangle()]
s = more_itertools.bucket(shapes, key=lambda x: type(x))
# s -> <more_itertools.more.bucket object at 0x7fa65323f210>
list(s[Cube])
# [<__main__.Cube object at 0x7f394a0633c8>, <__main__.Cube object at 0x7f394a063278>]
list(s[Circle])
# [<__main__.Circle object at 0x7f394a063160>, <__main__.Circle object at 0x7f394a063198>, <__main__.Circle object at 0x7f394a063320>]
Here we show how to bucket iterable based on items type. We first declare a few types of shapes and create a list of them. When we call bucket on this list with above key function, we create bucket object. This object supports lookup like built-in Python dict. Also, as you can see, each item in the whole bucket object is a generator, therefore we need to call list on it to actually get the values out of it.
map_reduce
Probably the most interesting function in this library for all the data science people out there - the map_reduce. I'm not going to go into detail on how MapReduce works as that is not purpose of this article and there's lots of articles about that already. What I'm gonna show you though, is how to use it:
from more_itertools import map_reduce
data = 'This sentence has words of various lengths in it, both short ones and long ones'.split()
keyfunc = lambda x: len(x)
result = map_reduce(data, keyfunc)
# defaultdict(None, {
# 4: ['This', 'both', 'ones', 'long', 'ones'],
# 8: ['sentence'],
# 3: ['has', 'it,', 'and'],
# 5: ['words', 'short'],
# 2: ['of', 'in'],
# 7: ['various', 'lengths']})
valuefunc = lambda x: 1
result = map_reduce(data, keyfunc, valuefunc)
# defaultdict(None, {
# 4: [1, 1, 1, 1, 1],
# 8: [1],
# 3: [1, 1, 1],
# 5: [1, 1],
# 2: [1, 1],
# 7: [1, 1]})
reducefunc = sum
result = map_reduce(data, keyfunc, valuefunc, reducefunc)
# defaultdict(None, {
# 4: 5,
# 8: 1,
# 3: 3,
# 5: 2,
# 2: 2,
# 7: 2})
This MapReduce implementation allows us to specify 3 functions: key function (for categorizing), value function (for transforming) and finally reduce function (for reducing). Some of these function can be omitted to produce intermediate steps in MapReduce process, as shown above.
sort_together
If you work with spreadsheets of data, chances are, that you need to sort it by some column. This is simple task for sort_together. It allows us to specify by which column(s) to sort the data:
# Table
"""
Name | Address | Date of Birth | Updated At
----------------------------------------------------------------
John | | 1994-02-06 | 2020-01-06
Ben | | 1985-04-01 | 2019-03-07
Andy | | 2000-06-25 | 2020-01-08
Mary | | 1998-03-14 | 2018-08-15
"""
from more_itertools import sort_together
cols = [
("John", "Ben", "Andy", "Mary"),
("1994-02-06", "1985-04-01", "2000-06-25", "1998-03-14"),
("2020-01-06", "2019-03-07", "2020-01-08", "2018-08-15")
]
sort_together(cols, key_list=(1, 2))
# [('Ben', 'John', 'Mary', 'Andy'), ('1985-04-01', '1994-02-06', '1998-03-14', '2000-06-25'), ('2019-03-07', '2020-01-06', '2018-08-15', '2020-01-08')]
Input to the function is list of iterables (columns) and key_list which is tells sort_together which of the iterables to use for sorting and with what priority. In case of the above example with first sort the "table" by Date of Birth and then by Updated At column.
seekable
We all love iterators, but you should always be careful with them in Python as one of their features is that they consume the supplied iterable. They don't have to though, thanks to seekable:
from more_itertools import seekable
data = "This is example sentence for seeking back and forth".split()
it = seekable(data)
for word in it:
...
next(it)
# StopIteration
it.seek(3)
next(it)
# "sentence"
seekable is function that wraps iterable in object that makes it possible to go back and forth through iterator, even after some elements were consumed. In the example you can see that we've got StopIteration exception after going through whole iterator, but we can seek back and keep working with it.
filter_except
Let's look at following scenario: You received mixed data, that contains both text and numbers and all of it is in string form. You however, want to work only with numbers (floats/ints):
from more_itertools import filter_except
data = ['1.5', '6', 'not-important', '11', '1.23E-7', 'remove-me', '25', 'trash']
list(map(float, filter_except(float, data, TypeError, ValueError)))
# [1.5, 6.0, 11.0, 1.23e-07, 25.0]
filter_except filters items of input iterable, by passing elements of iterable to provided function (float) and checking whether it throws error (TypeError, ValueError) or not, keeping only elements that passed the check.
unique_to_each
unique_to_each is one of the more obscure functions in more_itertools library. It takes bunch of iterables and returns elements from each of them, that aren't in the other ones. It's better to look at example:
from more_itertools import unique_to_each
# Graph (adjacency list)
graph = {'A': {'B', 'E'}, 'B': {'A', 'C'}, 'C': {'B'}, 'D': {'E'}, 'E': {'A', 'D'}}
unique_to_each({'B', 'E'}, {'A', 'C'}, {'B'}, {'E'}, {'A', 'D'})
# [[], ['C'], [], [], ['D']]
# If we discard B node, then C gets isolated and if we discard E node, then D gets isolated
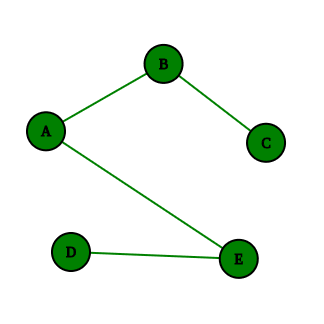
Here, we define graph data structure using adjacency list (actually dict). We then pass neighbours of each node as a set to unique_to_each. What it outputs is a list of nodes that would get isolated if respective node was to be removed.
numeric_range
This one has a lot of use cases, as it's quite common that you would need to iterate over range of some non-integer values:
from more_itertools import numeric_range
import datetime
from decimal import Decimal
list(numeric_range(Decimal('1.7'), Decimal('3.5'), Decimal('0.3')))
# [Decimal('1.7'), Decimal('2.0'), Decimal('2.3'), Decimal('2.6'), Decimal('2.9'), Decimal('3.2')]
start = datetime.datetime(2020, 2, 10)
stop = datetime.datetime(2020, 2, 15)
step = datetime.timedelta(days=2)
list(numeric_range(start, stop, step))
# [datetime.datetime(2020, 2, 10, 0, 0), datetime.datetime(2020, 2, 12, 0, 0), datetime.datetime(2020, 2, 14, 0, 0)]
What is nice about numeric_range is that it behaves the same way as basic range. You can specify start ,stop and step arguments as in examples above, where we first use decimals between 1.7 and 3.5 with step of 0.3 and then dates between 2020/2/10 and 2020/2/15 with step of 2 days.
make_decorator
Last but not least, make_decorator enables us to use other itertools as decorators and therefore modify outputs of other functions, producing iterators:
from more_itertools import make_decorator
from more_itertools import map_except
mapper_except = make_decorator(map_except, result_index=1)
@mapper_except(float, ValueError, TypeError)
def read_file(f):
... # Read mix of text and numbers from file
return ['1.5', '6', 'not-important', '11', '1.23E-7', 'remove-me', '25', 'trash']
list(read_file("file.txt"))
# [1.5, 6.0, 11.0, 1.23e-07, 25.0]
This example takes map_except function and creates decorator out of it. This decorator will consume result of decorated function as its second argument (result_index=1). In our case, the decorated function is read_file, which simulates reading data of some file and outputs list of strings that might or might not be floats. The output however, is first passed to decorator, which maps and filters all the undesirable items, leaving us with only floats.
Conclusion
I hope that you learned something new in this article, as itertools and more_itertools can make your life a whole lot easier if you are processing lots of data frequently. Using these libraries and functions however, requires some practice to be efficient with. So, if you think that you can make use of some of the things shown in this article, then go ahead and checkout itertools recipes or just force yourself to use these as much as possible to get comfortable with it. 😉





Top comments (1)
Hi Martin, thanks for this article I found on your blog. I work with python 2.7 so I'm very happy to see concrete example of py3 code :)