Criei um projeto pessoal com o intuito de aprender mais sobre typescript e nextjs no frontend, foi quando me deparei com o seguinte problema, eu teria que exibir aproximadamente 18 dados de 118 elementos da tabela periódica, coletar esses dados seria humanamente inviável, foi assim que tive a ideia de criar esse script.

Configurando o driver
As informações dos elementos serão extraídas do site PubChen, como os dados estão dentro de uma pop-up, utilizarei o selenium para abrir o navegador e extrair as informações, o navegador escolhido foi o chorme, para utilizá-lo é necessário instalar o chormedriver correspondente com a versão do seu navegador.

Instale a biblioteca webdriver e coloque o caminho de instalação do chormedriver;
pip install webdriver
from selenium import webdriver
driver = webdriver.Chrome( executable_path='C:/Users/{user}/Downloads/chromedriver_win32/chromedriver.exe')
Configurando a leitura da página
Para abrir o navegador é necessário configurar a url e passa-lá como parâmetro para o driver.get, para extrair os dados da página será usado a biblioteca BeautifulSoup.
pip install beautifulsoup4
from bs4 import BeautifulSoup
url = "https://pubchem.ncbi.nlm.nih.gov/periodic-table/#popup=1"
driver.get(url)
content = driver.page_source
soup = BeautifulSoup(content)
Pegando os dados da página
Para extrair os dados da página é necessário inspecionar os elementos da página e pegar os identificadores únicos dos campos de onde texto será extraído.
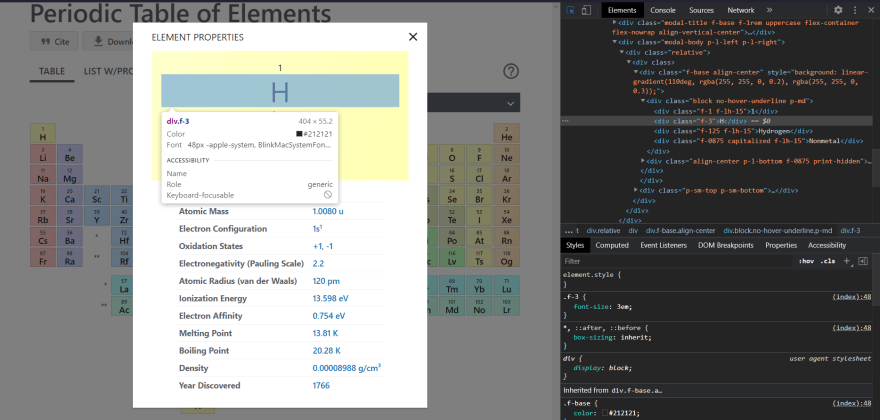
Como essa parte era repetitiva criei 2 funções uma que extrai o texto da span e outra que extrai o texto da div, no caso da span a class muda de acordo com o elemento selecionado na pop-up então enviei o símbolo químico como parâmetro.
def find_span(data_label, symbol):
formatted_string = data_label.format(symbol)
href = soup.find(
"a", {"data-label": formated_string})
if href:
span = href.find("span", {"class": "capitalized"})
if span:
return span.text
else:
return "N/A"
else:
return "N/A"
def find_div(class_name):
div = soup.find(
"div", {"class": class_name})
if div:
return div.text
else:
return "N/A"
symbol = find_div("f-3")
name = find_div("f-125 f-lh-15")
type_element = find_div("f-0875 capitalized f-lh-15")
standard_state = find_span(
'Content Link (List View): {}; Standard State Property Value', symbol)
atomic_mass = find_span(
"Content Link (List View): {}; Atomic Mass Property Value", symbol)
electron_configuration = find_span(
"Content Link (List View): {}; Electron Configuration Property Value", symbol)
oxidation_states = find_span(
"Content Link (List View): {}; Oxidation States Property Value", symbol)
electronegativity = find_span(
"Content Link (List View): {}; Electronegativity (Pauling Scale) Property Value", symbol)
atomic_radius = find_span(
"Content Link (List View): {}; Atomic Radius (van der Waals) Property Value", symbol)
ionization_energy = find_span(
"Content Link (List View): {}; Ionization Energy Property Value", symbol)
electron_affinity = find_span(
"Content Link (List View): {}; Electron Affinity Property Value", symbol)
melting_point = find_span(
"Content Link (List View): {}; Melting Point Property Value", symbol)
boiling_point = find_span(
"Content Link (List View): {}; Boiling Point Property Value", symbol)
density = find_span(
"Content Link (List View): {}; Density Property Value", symbol)
year_discovered = find_span(
"Content Link (List View): {}; Year Discovered Property Value", symbol)
Gravando dados no arquivo
Para gravar os dados no arquivo json é necessário montar o objeto que será enviado para o arquivo.
data = {"id": id, "symbol": symbol,
"name": name,
"type": type_element,
"standardState": standard_state,
"atomicMass": atomic_mass,
"electronConfiguration": electron_configuration,
"oxidationStates": oxidation_states,
"electronegativity": electronegativity,
"atomicRadius": atomic_radius,
"ionizationEnergy": ionization_energy,
"electronAffinity": electron_affinity,
"meltingPoint": melting_point,
"boilingPoint": boiling_point,
"density": density,
"yearDiscovered": year_discovered}
Depois não esqueça de fechar o navegador;
driver.close()
O último passo é instalar a biblioteca json para que ela salve os dados;
pip install json
Já com a biblioteca instalada, agora é só passar o json formatado para ela;
with open('data.json', 'w') as f:
json.dump(data, f)
Pegando os dados de todos os elementos
Agora que o script já está funcionando é preciso fazer ele chamar automaticamente todas às 118 pop-up, será utilizado o while para a repetição da chamada, a cada chamada o id da pop-up vai mudar e todos os dados extraídos serão salvos em um array, para no fim do loop serem salvos no arquivo json.
import json
from selenium import webdriver
from bs4 import BeautifulSoup
driver = webdriver.Chrome(
executable_path='C:/Users/{user}/Downloads/chromedriver_win32/chromedriver.exe')
array_elements = []
id = 1
while (id <= 118):
url = "https://pubchem.ncbi.nlm.nih.gov/periodic-table/#popup={}".format(
id)
driver.get(url)
content = driver.page_source
soup = BeautifulSoup(content)
def find_span(data_label, symbol):
formated_string = data_label.format(symbol)
href = soup.find(
"a", {"data-label": formated_string})
if href:
span = href.find("span", {"class": "capitalized"})
if span:
return span.text
else:
return "N/A"
else:
return "N/A"
def find_div(class_name):
div = soup.find(
"div", {"class": class_name})
if div:
return div.text
else:
return "N/A"
symbol = find_div("f-3")
name = find_div("f-125 f-lh-15")
type_element = find_div("f-0875 capitalized f-lh-15")
standard_state = find_span(
'Content Link (List View): {}; Standard State Property Value', symbol)
atomic_mass = find_span(
"Content Link (List View): {}; Atomic Mass Property Value", symbol)
electron_configuration = find_span(
"Content Link (List View): {}; Electron Configuration Property Value", symbol)
oxidation_states = find_span(
"Content Link (List View): {}; Oxidation States Property Value", symbol)
electronegativity = find_span(
"Content Link (List View): {}; Electronegativity (Pauling Scale) Property Value", symbol)
atomic_radius = find_span(
"Content Link (List View): {}; Atomic Radius (van der Waals) Property Value", symbol)
ionization_energy = find_span(
"Content Link (List View): {}; Ionization Energy Property Value", symbol)
electron_affinity = find_span(
"Content Link (List View): {}; Electron Affinity Property Value", symbol)
melting_point = find_span(
"Content Link (List View): {}; Melting Point Property Value", symbol)
boiling_point = find_span(
"Content Link (List View): {}; Boiling Point Property Value", symbol)
density = find_span(
"Content Link (List View): {}; Density Property Value", symbol)
year_discovered = find_span(
"Content Link (List View): {}; Year Discovered Property Value", symbol)
data = {"id": id, "symbol": symbol,
"name": name,
"type": type_element,
"standardState": standard_state,
"atomicMass": atomic_mass,
"electronConfiguration": electron_configuration,
"oxidationStates": oxidation_states,
"electronegativity": electronegativity,
"atomicRadius": atomic_radius,
"ionizationEnergy": ionization_energy,
"electronAffinity": electron_affinity,
"meltingPoint": melting_point,
"boilingPoint": boiling_point,
"density": density,
"yearDiscovered": year_discovered}
array_elements.append(data)
id = id + 1
driver.close()
with open('data.json', 'w') as f:
json.dump(array_elements, f)
Rodando script
Comando
python script.py
Dados exportados

Resultado

Repositórios
Tabela períodica 👩🏿💻
Web Scraping 👩🏿💻




Top comments (0)