What is a Lambda on AWS?
If you are a developer or have some programming background, you may be familiar with Lambda functions.
They are a useful feature in many of the most popular modern languages, and they basically are functions that lack an identifier, which is why they are also called anonymous functions. This last name may not be appropriate for certain languages, where not all anonymous functions are necessary Lambda functions, but that’s a discussion for another day.
Aws Lambda takes inspiration from this concept, but it’s fundamentally different. For starters, AWS Lambda is a service that lets you run code without having to provision servers, or even EC2 instances. As such, it is one of the cornerstones of Amazon’s serverless services, alongside Api-Gateway, DynamoDB and S3, to name a few.
Aws Lambda functions are event-driven architecture, and as such they can be triggered and executed by a wide variety of events. On this article, we will create a Lambda function and configure it to trigger based whenever an object is put inside of an S3 bucket. Then we’ll use it to update a DynamoDB table.

Getting Started
We’ll start on the AWS console. For this little project, we’ll need an S3 bucket, so let’s go ahead and create it.
In case you haven’t heard of it, S3 stands for Simple Storage Service, and allows us to store data as objects inside of structures named “Buckets”.
So we’ll search for S3 on the AWS console and create a bucket.

Today we don’t need anything fancy so let’s just give it a unique name.
We will also need a DynamoDB table. DynamoDB is Amazon’s serverless no-SQL database solution, and it we will use it to keep track of the files uploaded in our bucket.
We’ll go into “Create Table”, then give it a name and a partition key.

We could also give it a sort key, like the bucket where the file is stored. That way we could receive a list ordered by bucket when we do a query or scan. However, that is not our focus today. And since we are using just the one bucket, we’ll leave it unchecked.
Next, we’ll search for Lambda on the console.

Here we can choose to make a lambda from scratch, or build it using one of the many great templates provided by Amazon. We can also source it from a container or a repository. This time we’ll start from scratch and make with the latest version of Node.js.
We will be greeted by a function similar to this one
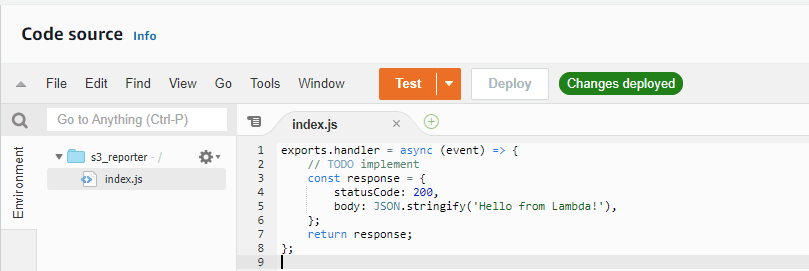
It’s just a simple function that returns an “OK” whenever it’s triggered. Those of you familiar with Node may be wondering about that “handler” on the first line.
Anatomy of a Lambda function.
The handler is sort of an entry point for your Lambda. When the function is invoked, the handler method will be executed. The handler function also receives two parameters: event and context.
Event is JSON object which provides event-related information, which your Lambda can use to perform tasks. Context, on the other hand, contains methods and properties that allow you to get more information about your function and its invocation.
If at any point you want to test what your Lambda function is doing, you can press on the “Test” button, and try its functionality with parameters of your choosing.
We know we want our Lambda to be triggered each time somebody uploads an object to a specific S3 buckets. We could configure the bucket, then upload a file to see kind of data that our function receives. Fortunately, AWS already has a test even that mimics an s3 PUT operation trigger.
We just need to select the dropdown on the “Test” button, and select the “Amazon S3 Put” template”.
var AWS = require("aws-sdk");
exports.handler = async (event) => {
//Get event info.
let bucket = event.Records[0].s3
let obj = bucket.object
let params = {
TableName: "files",
Item : {
file_name : obj.key,
bucket_name: bucket.bucket.name,
bucket_arn: bucket.bucket.arn
}
}
//Define our target DB.
let newDoc = new AWS.DynamoDB.DocumentClient(
{
region: "us-east-1"});
//Send the request and return the response.
try {
let result = await newDoc.put(params).promise()
let res = {
statusCode : result.statusCode,
body : JSON.stringify(result)
}
return res
}
catch (error) {
let res = {
statusCode : error.statusCode,
body : JSON.stringify(error)
}
return res
}
}
This simple code will capture event info and enter it into our DynamoDB table.
However, if you go ahead and execute it, you will probably receive an error stating that our Lambda function doesn’t have the required permission to run this operation.
So we’ll just head to IAM. Hopefully we’ll be security-conscious and create a role with the minimum needed permissions for our Lambda.
Just kidding, for this tutorial full DynamoDB access will do!

Now everything should work. Let’s publish our Lambda and upload a file to our S3 bucket and test it out!
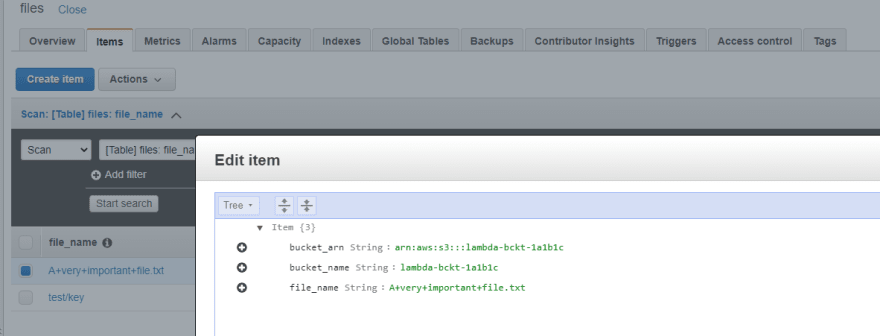
Everything is working as it should!
Now, what we did was pretty basic, but this basic workflow (probably backed by Api Gateway or orchestrated with Step Functions) can make the basis of a pretty complex serverless app.
Thanks for reading!





Top comments (0)