This is the second post about optimization, in the first one I tried to give you the big picture of my ideal workflow and what are the tools I like best when I'm trying to figure out where to start.
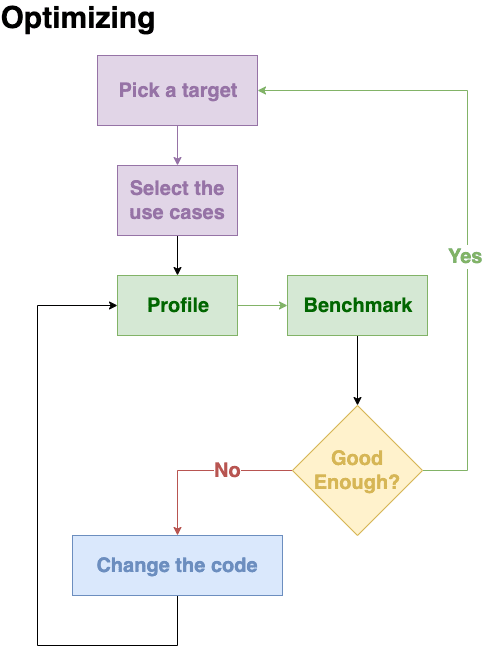
Let's assume we already decided what we want to optimize for, we have our testcases ready and we managed to profile and prepare the benchmarks.
Now we know which are our top 5 codepaths that are using the largest amount of resources or taking the largest amount of time within our program.
What to do now?
To keep things simple we focus again only on two subsets among the possible optimization targets: single execution time and total number of allocations.
Execution time
In order to speed up something we have a number of strategies, here I'm giving you a list in order of expected gains.
Check your algorithm
Sometimes you start with a naive implementation that works but has a cubic complexity or worse, sometimes you picked a refined O(ln(n)) algorithm and you forgot to make sure it doesn't have constant overheads that dwarf the rest of it for your specific workload.
Thinking again about what you are solving can lead to surprising gains, the best algorithm on paper might not be the right one for you sometimes.
Sometimes having better cache locality and more compact code has more impact than using a theoretically optimal algorithm.
Find and exploit data parallelism
Most architectures support SIMD in a way or another.
- rustc in itself does a fairly decent job if you give it enough context (e.g. using Iterators instead of bare loops), but it can help only up to a point. You may build specialized binaries leveraging
target-cpuortarget-featurese.g.:
$ RUSTFLAGS="-C target-feature=+avx2" cargo build --release
- packed_simd may help you do more while staying portable.
- stdarch gives you access to the arch-specific intrinsics and the cpu-features detection making fairly straightforward building optimized variants.
- if you want to drop down to assembly, nasm-rs and cc-rs let you build everything with some ease. Sadly inline-assembly is nightly-only, so there is still some work to be done here to have a great support.
When you are going through this path cargo-asm helps a lot seeing what is going on and you should look for cache-misses and branch-misprediction statistics in your profiler if you aren't getting the performance you expect.
Last but not least you should be careful on which instruction sets you are using. Modern x86_64 provides extremely powerful instructions in the avx512f set, but either you use them extensively or you might hit significant slowdowns due the cpu-state change.
Find and exploit workload parallelism
Most CPUs come with at least 2 cores and/or 2 or more hardware threads nowadays.
Using threads is the first clear example of throwing in more resources to get more performance: using additional threads usually means you end up using more memory and spend some cpu cycles on synchronization, the Amdahl's_law usually models well the theoretical optimum you can reach.
The rust standard library comes with a good set of built-ins you can use, but there is an ecosystem of external crates to help further, among those my favorites are:
- rayon makes really easy to split the workload to a pool of workers if you are using Iterators.
- crossbeam provides a rich set of tools if you want to be more creative.
If your application is doing a good amount of I/O, you might want to explore asynchronous programming patterns. Under the hood you might deal with coroutines or threadpools, the API you are facing is still the arguably easy one based around futures, the best runtimes I know are:
- tokio is a well established runtime to build your applications and comes with everything you need and some more.
- async-std is a newer implementation of similar concepts, you might want to try it if you do not like what tokio offers or the other way round.
The asynchronous programming features provided by rust try to be nearly zero-cost abstractions, yet you have to deal with an additional cognitive burden when using it, so I suggest to not jump on it without considering all the other options.
Remove slowdowns from the critical path
Once you managed to use the optimal algorithms, simdify lots of code and split the workload over a pool of threads, you will start seeing unexpected impact of your changes:
Halving time spent in an hot path that comes in the top 5 from
perf reportor equivalent, does not map to the expected reduction of the overall execution time.
This happens when we split the workload over multiple threads, once you start doing this you need to pay additional care when profiling on what is going to run in parallel and what is painfully serial.
- hawktracer provides a fairly fast way to collect the information and visualize it in an effective way.
- cargo instruments can also provide good hints on this, but I find it less clear.
Memory usage
I decided to not focus much on how to reduce the resident set or the peak memory usage since there isn't much to say:
- allocate only what you need
- use
with_capacity()instead ofnew()whenever you know already the maximum size of your container. - use the smallest datatypes in arrays/tables as long this choice does not have other side effects on performance.
Total number of allocations
The number of allocations is a more interesting problem:
- Using the heap has an inherent cost compared to using the stack
- Every time you allocate and deallocate you increase the risk of fragmenting the memory, do that often enough and the allocator cannot satisfy your next request.
Within reason you might want to have stack-allocated buffers to use instead of having Vecs and Boxes around, rust makes fairly easy pass around references, even across threads (as shown by crossbeam scope)
-
ArrayVec is often a boon when you want to convert
Vecs of known (maximum) size by using a stack-allocated array as storage. - SmallVec is another crate offering similar features.
What next
I provided some pointers on how to optimize, and, as for the previous post, I intentionally avoided making examples to keep the whole thing reasonably compact.
During the next posts I'll start to focus on specific situations that happened while developing rav1e and provide some example usage of some of the tools.





Latest comments (0)