Here a quick summary of what happened last month. I will try to write a recap every month.
February Summary
We poured lots of work on improving the encoding speed, you may read some details of the journey:
- Analyze our memory access patterns and improve the layout and the update strategy of a structure accessed a lot in our hottest code-path.
- parallelize one of the remaining bottleneck so we improve the average thread usage and improve both speed and latency.
- add the temporal rdo lookahead to our speed levels, measure its quality-vs-speed impact and retune them accordingly.
The benchmarks are prepared using speed-levels-rs.
The encoder is using the following settings:
--threads 16 --tiles 16 -l 100 <file> -o <encoded> -s <level>The source file is Bosphorus from the ultravideo test sequences, the 1080p 10bit version is the 4k 10bit version scaled down, since it is not available on the website.
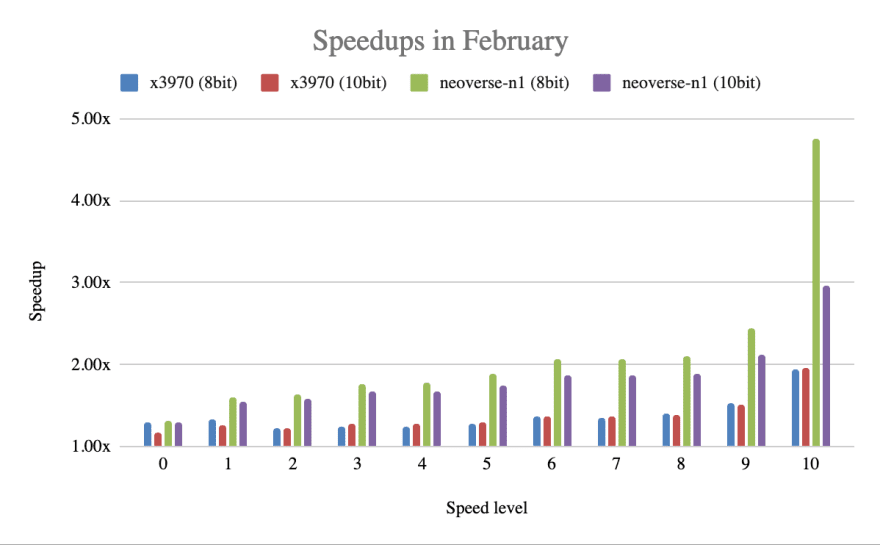
Overall our aarch64 support is getting fairly good, but there is still a lot of room for improvement on 8bit.
On the other hand there are 10bit optimizations it that aren't yet available for x86_64. Help in improving our SIMD coverage is very welcome :)
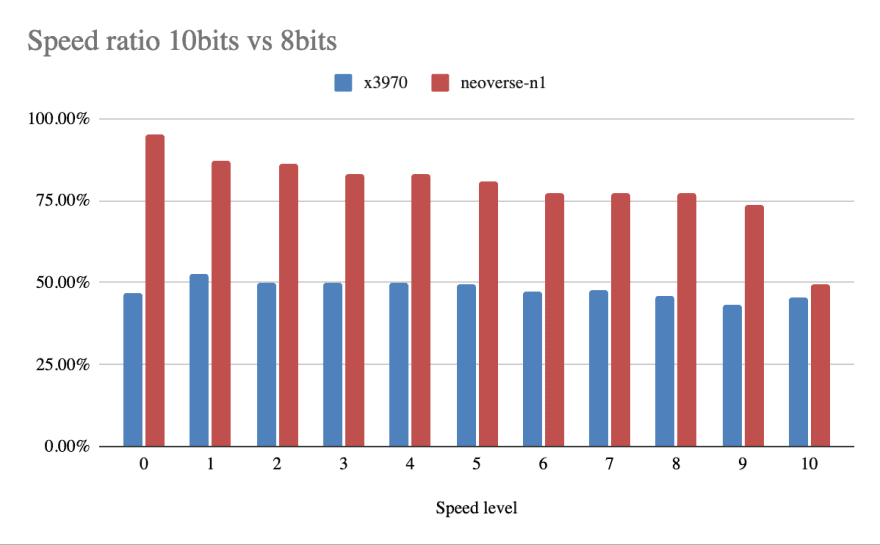
Digging deeper
x86_64
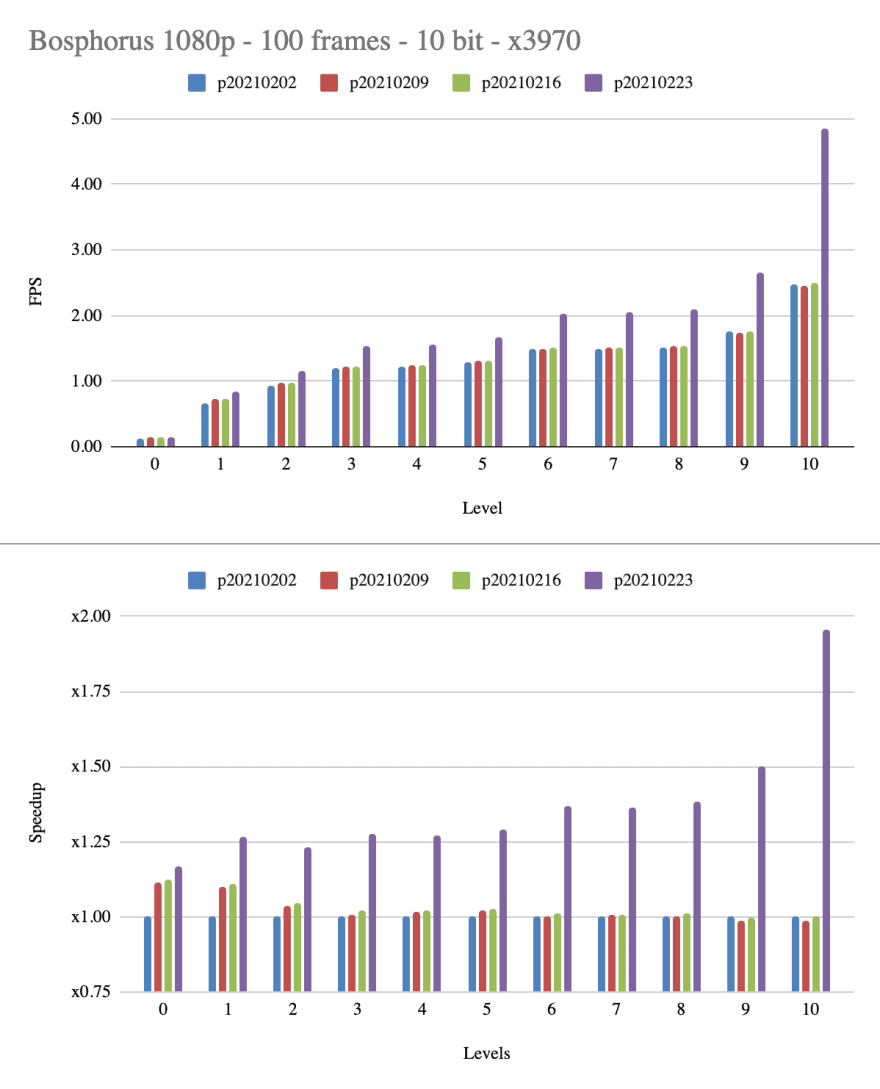
As expected the memory layout optimization that happened between p20210209 and p20210216 had the largest impact on the speed 0 and 1, while optimizing and tuning the temporal rdo lookahead computation has the largest impact on speed level 9 and 10.
| Speed Level | p20210209 | p20210216 | p20210223 |
|---|---|---|---|
| 0 | x1.23 | x1.29 | x1.30 |
| 1 | x1.20 | x1.24 | x1.33 |
| 2 | x1.08 | x1.11 | x1.22 |
| 3 | x1.04 | x1.07 | x1.25 |
| 4 | x1.04 | x1.06 | x1.24 |
| 5 | x1.05 | x1.07 | x1.27 |
| 6 | x1.04 | x1.05 | x1.37 |
| 7 | x1.03 | x1.06 | x1.36 |
| 8 | x1.04 | x1.06 | x1.39 |
| 9 | x1.00 | x1.02 | x1.52 |
| 10 | x1.00 | x1.01 | x1.94 |

The x86_64 10bit encoding is behaving similarly. Our SIMD support for it received a large boost in January and there is an ongoing effort to improve it even further in March.
| Speed Level | p20210209 | p20210216 | p20210223 |
|---|---|---|---|
| 0 | x1.12 | x1.12 | x1.17 |
| 1 | x1.10 | x1.11 | x1.26 |
| 2 | x1.04 | x1.04 | x1.23 |
| 3 | x1.00 | x1.02 | x1.28 |
| 4 | x1.01 | x1.02 | x1.27 |
| 5 | x1.02 | x1.02 | x1.29 |
| 6 | x1.00 | x1.01 | x1.37 |
| 7 | x1.01 | x1.01 | x1.37 |
| 8 | x1.00 | x1.01 | x1.38 |
| 9 | x0.99 | x1.00 | x1.50 |
| 10 | x0.99 | x1.00 | x1.95 |
Aarch64
The impact of the optimizations on aarch64 had been more radical with a fairly large relative improvement on speed 10.
| Speed Level | p20210209 | p20210216 | p20210223 |
|---|---|---|---|
| 0 | x1.14 | x1.15 | x1.31 |
| 1 | x1.11 | x1.10 | x1.59 |
| 2 | x1.03 | x1.03 | x1.63 |
| 3 | x1.03 | x1.01 | x1.76 |
| 4 | x1.01 | x1.01 | x1.77 |
| 5 | x1.02 | x1.01 | x1.88 |
| 6 | x1.02 | x1.00 | x2.07 |
| 7 | x1.01 | x1.00 | x2.07 |
| 8 | x1.02 | x1.00 | x2.10 |
| 9 | x1.00 | x0.99 | x2.45 |
| 10 | x1.01 | x0.98 | x4.75 |

The 10bit boost is not as extreme, but still substantial.
| Speed Level | p20210209 | p20210216 | p20210223 |
|---|---|---|---|
| 0 | x1.13 | x1.17 | x1.30 |
| 1 | x1.08 | x1.11 | x1.54 |
| 2 | x1.02 | x1.05 | x1.57 |
| 3 | x1.00 | x1.03 | x1.66 |
| 4 | x1.00 | x1.02 | x1.67 |
| 5 | x1.00 | x1.03 | x1.74 |
| 6 | x1.00 | x1.02 | x1.87 |
| 7 | x1.00 | x1.03 | x1.87 |
| 8 | x1.00 | x1.02 | x1.89 |
| 9 | x0.99 | x1.01 | x2.12 |
| 10 | x0.98 | x1.02 | x2.96 |
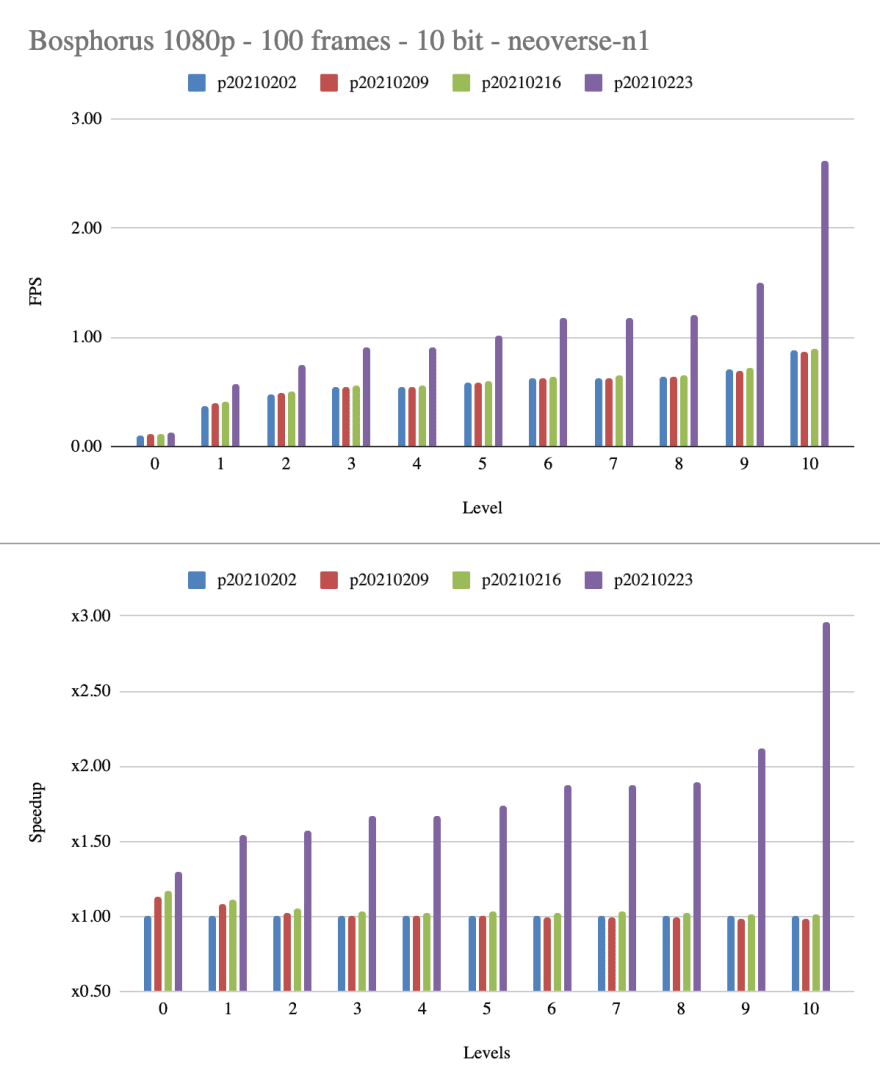
I tested on some different aarch64 systems to see if there is a large difference in its behavior.
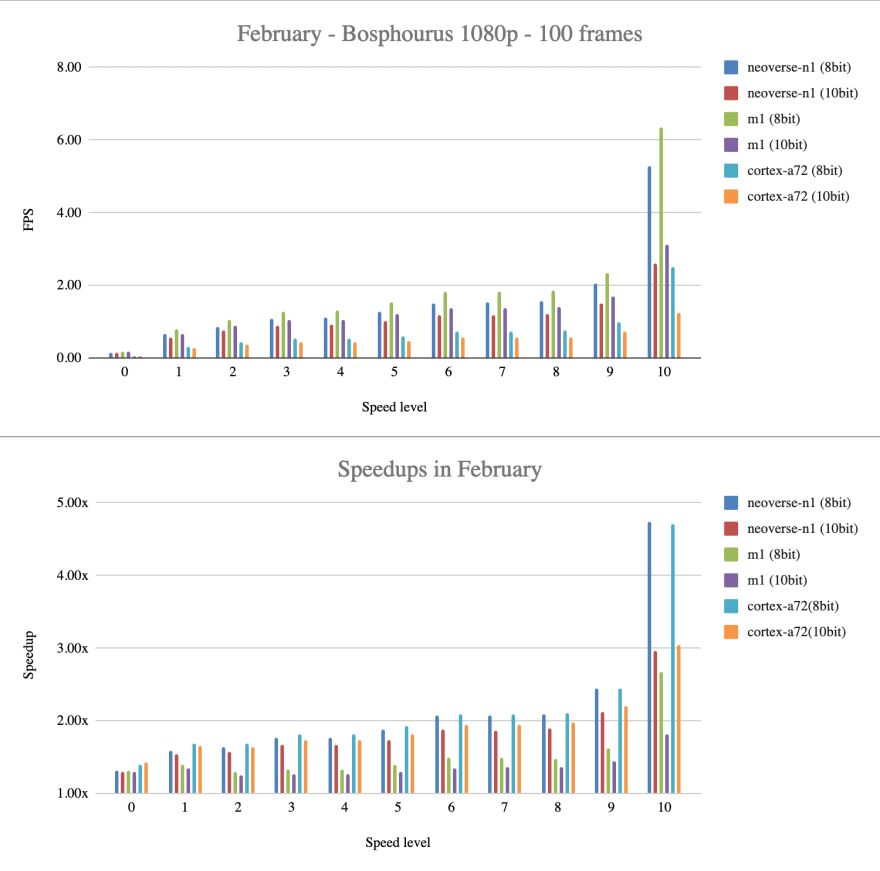
The Apple M1 is fairly different, but that's something I would expect. I will talk a bit more about it in other blogposts probably.
Coming next
We already landed additional SIMD for both x86_64 and aarch64, David Barr started working on improving the segment selection and I have eventually came up with the internals architecture that would give us a better thread pool usage while not impacting a lot the overall latency.
March is going to be exciting.





Latest comments (0)