This is a little step-by-step tutorial meant to help our bootcamp students during their project weeks. It covers two things:
- Web Browser Automation - During your project weeks, we would like you to spend as much time as possible shipping features, and little time doing manual testing. Our first case in the tutorial covers Foot Traffic, a gem developed by Le Wagon that will help you automate user interaction with your web app with ruby code.
- Scraping - Your project might need better data that what the Faker Gem can provide, which means you need to scrape data from somewhere (legally of course). The second part covers how to use Vessel, a gem optimized for scraping.
If you are the reader type, follow along! If you prefer to see it live before diving into the code, check out the videos recorded by our lead teacher Prima Aulia Gusta (Web Browser Automation Video and Scraping Video).
For the curious
Both Foot Traffic and Vessel are built on top of Ferrum, a gem that gives you a high-level API to interact with Chrome. It's easy to use, super fast, thread safe and feature rich.
Foot Traffic is a wrapper for Ferrum that extends its API to manipulate different tabs at the same time. While it's no substitute to integration tests, using Foot Traffic is awesome to simulate how your application behaves when multiple users access it at the same time.
Vessel is a web crawling framework built on top of Ferrum. It gives you an easy way to extract information from websites. Perfect if the data you need for your project is not provided by an API.
You can learn more here:
Enough with the intro, let's dive into it.
1. Web Browser Automation with Foot Traffic
We are going to get started with Foot Traffic, we'll be using scrapethissite for the example, which allows for automated browsing without restrictions.
1.1 Install Foot Traffic
On your terminal, run the following
mkdir foot-traffic
cd foot-traffic
bundle init
This will create a Gemfile. Open it in your code editor and add
gem 'foot_traffic'
Proceed to install the gem with
bundle install
1.1 Simulating a Login
We'll try to login to this website automatically with Foot Traffic.
Let's create the file that will hold our script on the terminal
touch foot_traffic.rb
After that, we need to require the gem, declare that we are using FootTraffic on the global namespace, and start a session.
The session will give us access to a window object, and that window object can instantiate tabs that work in parallel. For now, we'll just work with one tab and we'll go to the website
require 'foot_traffic'
using FootTraffic
FootTraffic::Session.start do |window|
window.tab_thread { |tab| tab.goto "https://scrapethissite.com/pages/advanced/?gotcha=login"}
end
When you run this script on ruby, an instance of chrome on autopilot will display something like this.

On the login page, we can inspect its css to understand which elements we need to interact with. If you check it out with your dev tools, we have two inputs with '[name="user"]' and '[name="password]' . Ferrum gives us the #at_css method to target an element, and we can then subsequently user #focus and #type to enter an input.
#type takes multiple parameters, and you can enter key actions like enter or tab. We'll use :enter after writing the password to submit the form.
require 'foot_traffic'
using FootTraffic
FootTraffic::Session.start do |window|
window.tab_thread do |tab| tab.goto "https://scrapethissite.com/pages/advanced/?gotcha=login"
tab.at_css('[name="user"]').focus.type('primaulia')
tab.at_css('[name="pass"]').focus.type('secret', :enter)
end
When you do this, it might be that Chrome perform the actions before all resources are loaded, resulting in errors and unexpected behavior. You can add options to throttle the speed of your actions and customize timouts.
require 'foot_traffic'
using FootTraffic
opts = {
process_timeout: 10, # How long to wait for Chrome to respond on startup
timeout: 10, # How long to wait for a response
slowmo: 0.3, # pace of the actions
window_size: [1024, 768]
}
FootTraffic::Session.start(options: opts) do |window|
window.tab_thread do |tab| tab.goto "https://scrapethissite.com/pages/advanced/?gotcha=login"
tab.at_css('[name="user"]').focus.type('primaulia', :tab)
tab.at_css('[name="pass"]').focus.type('secret', :enter)
end
end
If you run the script from your terminal with ruby foot_traffic.rb , you should be able to login successfully and see something like this.

1.2 Navigating
Now, let's imagine we just want to browse through this site and make sure all the data on the tables display correctly. Let's open a new tab that goes to the site
require 'foot_traffic'
require 'pry-byebug'
using FootTraffic
opts = {
process_timeout: 10,
timeout: 100,
slowmo: 0.1,
window_size: [1024, 768]
}
FootTraffic::Session.start(options: opts) do |window|
window.tab_thread do |tab| tab.goto "https://scrapethissite.com/pages/advanced/?gotcha=login"}
tab.at_css('[name="user"]').focus.type('primaulia', :tab)
tab.at_css('[name="pass"]').focus.type('secret', :enter)
end
window.tab_thread do |tab| tab.goto "https://scrapethissite.com/pages/ajax-javascript/"
end
end
This should take you to a database of Oscar Award winning movies.
As the url indicates, all the lists are loaded via AJAX requests. All our elements have ids that go from 2010 to 2015. We can iterate through the elements at a slower pace to make sure the ajax request comes back.
Using css selectors with numbers is tricky, so we'll use xpath this time to stay safe when going through the different years.
require 'foot_traffic'
using FootTraffic
opts = {
process_timeout: 10,
timeout: 100,
slowmo: 0.2,
window_size: [1024, 768]
}
FootTraffic::Session.start(options: opts) do |window|
window.tab_thread do |tab| tab.goto "https://scrapethissite.com/pages/advanced/?gotcha=login"}
tab.at_css('[name="user"]').focus.type('primaulia', :tab)
end
window.tab_thread do |tab| tab.goto "https://scrapethissite.com/pages/ajax-javascript/"
2010.downto(2005) do |year|
tab.at_xpath("//*[@id=#{year}]").click
sleep 2
end
end
end
Now we should be able to browse through the tables programmatically, while at the same time the login happens on a separate tab.

And that's it! Feel free to take it from here to automate interactions with your own project 🚀. A great thing about Foot Traffic is that the browser will remain open after finding an error, so you can go back to manual mode to see what happened and explore logs.
Scraping with Vessel
Foot Traffic is fantastic for automating user interaction, but it gets cumbersome if you want to extract data from a website. For that, you might want a tool like Vessel.
Let's imagine that you want to build an aggregator that assesses all the food delivery platforms, and rates them according to a number of dimensions.
For such purpose, you might want to get some data from deliveroo.sg . As of time of writing, they provide an API for their partners so they can manage their orders, but they don't expose their restaurant data. Time to scrape.
Important note:
Make sure that when you scrape a website, you are actually allowed to do it. You can check the website's robots.txt to see permissions. Always make sure you understand the legal constraints of scraping. This article makes a great summary of what to bear in mind. When this article was written, deliveroo.sg did not hold any scraping restrictions. Make sure you check before scraping their website, or any other website.
2.1 Install Vessel
Go to your Gemfile and add the following
gem 'vessel'
In your terminal, create a new file that will hold the Vessel scraper and install the gem
touch scraper.rb
bundle install
To scrape with Vessel, you need a class that:
- Inherits from Vessel
- Has a parse method
- Has a domain
- Has
start_urlsto go and scrape
require 'vessel'
class DeliverooScraper < Vessel
domain 'deliveroo.sg'
start_urls # need some urls to scrape
def parse
# need code that does magic data extraction
end
end
2.2 Finding some URLs to Scrape
Now, we need to check what is the url structure of the pages we want to scrape. When we arrive at delilveroo, we are asked for a postal code number. After submitting, we'll be shown a collection of restaurants that we can scrape. The url looks like this:
https://deliveroo.com.sg/restaurants/singapore/kallang-lavender?fulfillment_method=DELIVERY&postcode=339696
So we can go an assume that there are two dynamic variables involved, the district name and the postal code. Let's try these on our browser
https://deliveroo.com.sg/restaurants/singapore/katong?fulfillment_method=DELIVERY&postcode=424876
https://deliveroo.com.sg/restaurants/singapore/novena?fulfillment_method=DELIVERY&postcode=308215
They work! To figure out the postal code names, you can enter a valid Singaporean postal code, and you will get how the district is named on the url.
2.3 Setting up our Scraper
First, let's add the urls we got to the Scraper class
require 'vessel'
class DeliverooScraper < Vessel
domain 'deliveroo.sg'
start_urls ["https://deliveroo.com.sg/restaurants/singapore/katong?fulfillment_method=DELIVERY&postcode=424876",
"https://deliveroo.com.sg/restaurants/singapore/novena?fulfillment_method=DELIVERY&postcode=308215"]
def parse
# need code that does magic data extraction
end
end
This is the job of our parse method. We can use xpath and css selectors. All css attributes are stamped on deliveroo, which makes the structure of the website harder to parse. We'll go with xpath to extract the data within the cards.
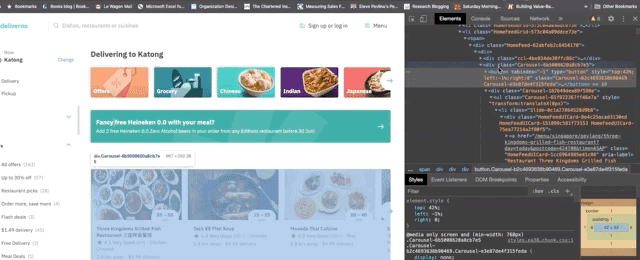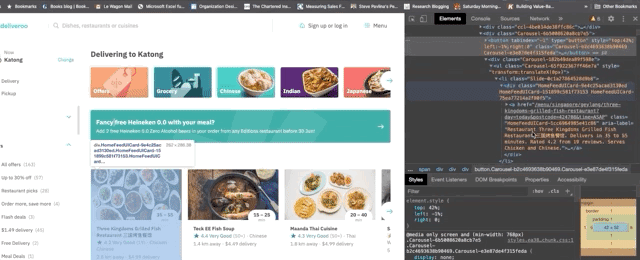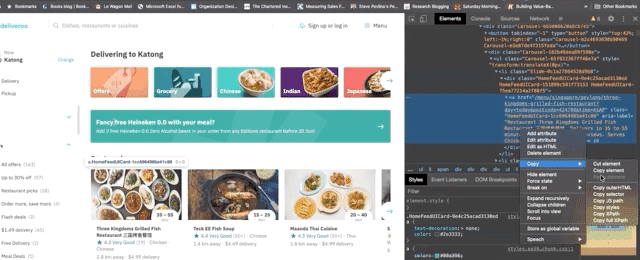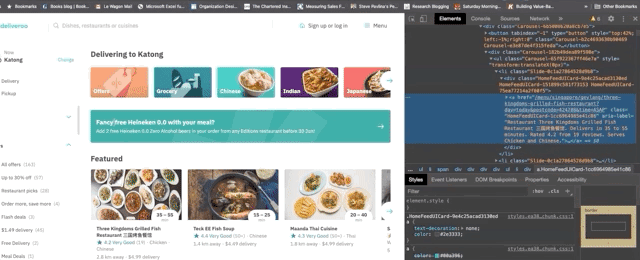
Now that we have the xpath, let's add the code that will collect the data for us automatically.
require 'vessel'
class DeliverooScraper < Vessel
domain 'deliveroo.sg'
start_urls "http://deliveroo.sg/"
def parse
restos = xpath('/html/body/div[1]/div/div/div[2]/div/div[2]/div/ul/li[3]/span/div/div/div[2]/div/ul/li')
restos.each do |resto|
(name, distance, rating, category) = resto.at_css('a').attribute("aria-label".to_sym).split('. ')
yield({
name: name,
rating: rating,
distance: distance,
category: category
})
rescue
next
end
end
end
xpath selects all the elements that respond to our xpath, which we call restos. For each resto, we can fetch the name, distance, rating and category by manipulating the info stored in the aria-label attribute.
After that, we use yield the data we got into a hash. We add a rescue to prevent the scraper from crashing in case one element does not respond exactly to the pattern we identified.
2.4 Running our Scraper
To fetch the data, we just need to call run on the Scraper and make sure we have a place where we can store the data.
require 'vessel'
class DeliverooScraper < Vessel
# ....
end
restaurant_data = []
DeliverooScraper.run { |resto| restaurant_data << resto.to_json }
puts restaurant_data
Now, in the terminal you can do something like this.
ruby scraper.rb >> restaurant_data.json
And the restaurant will be waiting for you in a json file that you can use for your project seeds. Thanks deliveroo! 🤗🦘
Thanks for Reading!
This tutorial has been brought to you by Prima Aulia Gusta and Miguel Jimenez. We are part of Le Wagon in Singapore 🇸🇬. Our immersive coding bootcamps build the tech skills and product mindset you need to kick-start your tech career, upskill in your current job, or launch your own startup.
If you want to exchange thoughts on how to create outstanding learning experiences in tech feel free to contact me at miguel.jimenez@lewagon.org.





Top comments (0)