- Part 1: Read Aside Caching
- Part 2: Enhanced Approaches (expected to be released on 7/11)
Today we are going to talk about consistency, especially the consistency of data between cache and database. This is actually an important topic, particularly as the size of an organization increases, the requirements for consistency will grow and so will the implementation of consistency.
For example, a startup service will not have a higher Service Level Agreement, aka SLA, than a mature service. For a startup service, a data consistency SLA of four nines (99.99%) might be considered high, but for a mature service like AWS S3, the data SLA is as high as 11 nines.
We all know that for every nine, the difficulty and complexity of the implementation will increase in an exponential way, so for a startup service, there are basically no resources to maintain a very high SLA.
Thus, how can we use the resources as effectively as possible to improve consistency? That's what this article will introduce. Again, the consistency mentioned here refers specifically to the consistency between cache and database data.
Why Caching?
I believe we all agree that inconsistencies are inevitable when we put data in two different storages. So what makes us put data into cache rather than risking inconsistency?
- The price of databases is high. In order to provide data persistence and as high availability as possible, even the relational database provides ACID guarantee, which makes the database implementation complex and also consumes hardware resources. Regardless of hard drives, memory or CPU, the database must be supported by good hardware specifications in order to work well, which also leads to the high price of the database itself.
- The performance of the database is limited. In order to persist the data, the data written to the database must be written to the hard drives, which also causes the performance bottleneck of the database, after all, the read and write efficiency of hard drives is much worse than memory.
- The database is far away from the user. Here, the far means the physical distance. As mentioned in the first point, because of the high cost of databases and the need to centralize data as much as possible for further analysis and utilization, a global service database is not placed in all over the world. The most common practice is to choose a fixed location. In Asia, for example, because AWS's Singapore data center is lower priced, it is often chosen for Asian users, but for Japanese users, the network distance increases and the transfer rate decreases.
For the above three reasons, the need for caching arises.
Because a cache does not need to be persistent, it can use memory as the storage medium, so it is inexpensive and has excellent performance. Because of the low price, caches can be placed as close to the user as possible, for instance, caches can be placed in Tokyo so that users in Japan can use them nearby.
Caching Patterns
It seems that caching is necessary, so how do we use caching for the consistency as much as possible?
To keep this article from losing focus, the caches mentioned are all based on Redis and the database is MySQL, and our goal is to improve consistency as much as possible with limited resources, both hardware and manpower, so the complex architectures of many large organizations are out of our scope, such as Meta's TAO.
TAO is a distributed cache and has a very high SLA (10 nines). However, to operate such a service, there is a very complex architecture behind it, and even the monitoring of caching is extremely large, which is not affordable for an ordinary organization.
Therefore, we will focus on the following patterns, highlighting their problems and how to avoid them as much as possible.
- Cache Expiry
- Read Aside
- Read Through
- Write Through
- Write Ahead (Write Behind)
- Double Delete
The following sections will follow the below procedure.
- read path
- write path
- potential problems
- how to improve
Cache Expiry
Read Path
- Reading data from cache
- If the cache data does not exist
- Read from the database instead
- and write back to the cache
We add a TTL to each data when writing back to the cache.
EXPIRE key seconds [ NX | XX | GT | LT]
Write Path
- Write data to the database only
Potential Problems
When updating data, inconsistencies occur because the data is only written back to the database. The inconsistency time depends on the TTL settings, nevertheless, it is difficult to choose a suitable value for the TTL.
If the TTL is set too long, the inconsistency time will be increased and, on the contrary, the cache will not be effective.
It is worth mentioning that caching is built to reduce the load on the database and to provide performance, and a very short TTL will make caching useless. For example, if the TTL of a certain data is set to 1 second, but no one reads it within 1 second, then the cached data will be no value at all.
How to Improve
The read path seems to be the usual practice, but when the database is updated, there should also be a mechanism for updating the cached data. And this is also the concept of Read Aside.
Read Aside
Read Path
- Reading data from cache
- If the cache data does not exist
- Read from the database instead
- and write back to the cache
This process is the same as Cache Expiry, but the TTL can be set long enough. This allows the cache to have as much play time as possible.
Write Path
- Write the data into the database first
- Then clean cache.
Potential Problems
Such read and write paths look fine, but there are a few corner cases that can't be avoided.
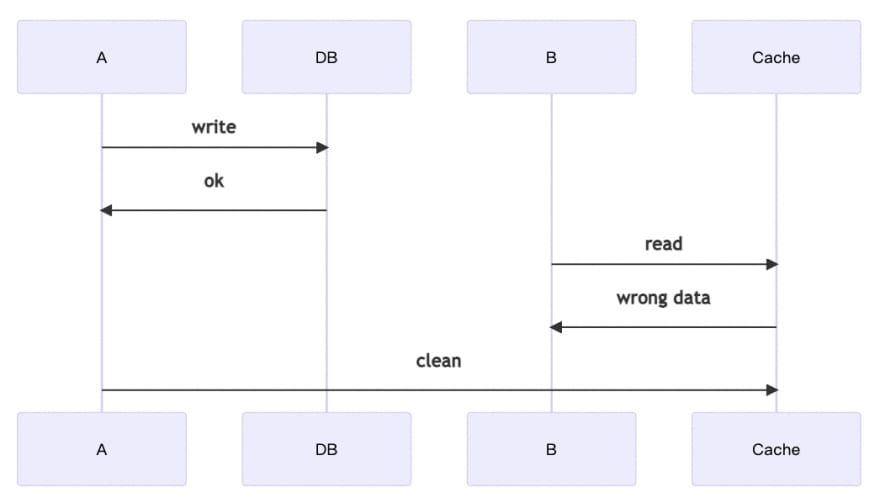
A wants to update the data, but B wants to read the data at the same time. Individually, both A and B have the right process, but when both of them happen together, there may be a problem. In the above example, B has already read the data from the cache before A clears the cache, so the data that B gets at that moment will be old.
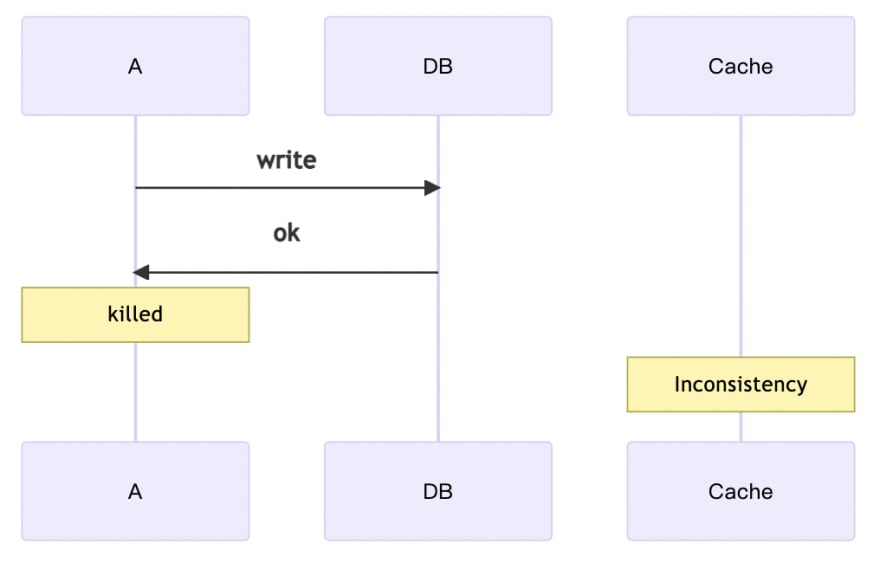
When A is updating the data, the database is already finished updating, but it is killed due to "some reason". At this moment, the data in the cache will remain inconsistent for a while until the next time the database is updated or a TTL occurs.
Getting killed may sound serious and rare, but it's actually more likely to happen than you might think. There are several scenarios where a kill can occur.
- When changing versions, either through containers or VMs, the old version of the application must be replaced with the new version, and the old version will be killed.
- When scale-in, the redundant application will be recycled and will also be killed.
- Lastly, it is the most common, when the application crashes, it will inevitably be killed.

When A wants to read the data and B wants to update the data, again, both of them have the right individual process, but the error occurs.
First A is trying to read data because no corresponding result is found in the cache, so he reads from the database; at the same time, B is trying to update the data so he clears the cache after the database operation. Then, A writes the data to the cache, and the inconsistency occurs, and the inconsistency will remain for a while.
How to Improve
Case 1 and Case 3 can be minimized when the application manipulates data correctly. Take Case 1 as an example, don't do anything extra after updating the database and clean up the cache right away, while in Case 3, after reading data from the database, don't do too much format conversion and write the result to the cache as soon as possible. In this way, the chance of occurrence can be reduced, but even so, there are still some unavoidable situations, such as the stop-the-world generated by garbage collection.
Case 2, on the other hand, can reduce the chance of artificial occurrences by implementing an graceful shutdown, but there is nothing that can be done for an application crash.
Read Aside Variant 1
In order to solve Case 1 and Case 2, some people will try to modify the original process.
Read Path
- Reading data from cache
- If the cache data does not exist
- Read from the database instead
- and write back to the cache
This process is exactly the same as the original Read Aside.
Write Path
- Clean cache first
- Then write the data into the database cache.
This process is the opposite of the original Read Aside.
Potential Problems

Although the original Case 1 and Case 2 are solved, a new problem is created.
When A tries to update the data, and B wants to read the data, A clears the cache first; then B cannot read the data, so it reads from the database instead, and A continues to update the database. Finally, B writes the read data back to the cache. The inconsistency is occurred.
How to Improve
In fact, Case 1 and Case 2 are much less likely to occur than the corner cases of this variant, especially when the correct implementation of Read Aside has significantly reduced the occurrence of Case 1 and Case 2. On the other hand, the corner cases of the variant cannot be effectively improved.
Therefore, it is not recommended to use such a variant.
Conclusion
In general, a relatively high level of consistency can be achieved by Read Aside, even if it is only a simple implementation, but it can also have a very good reliability.
Nevertheless, if you would like to improve consistency further, Read Aside alone is not enough, and a more complex approach is required, but also at a higher cost. Therefore, I will leave these approaches for the next article. In the next article, I will describe how to make the best use of the resources at hand to achieve as much consistency as possible.
To emphasize again, although Read Aside is very simple, it is reliable enough as long as it is implemented correctly.





Latest comments (0)