
In this blog post, we will cover what SEO is, what are some of the best practices with SEO, provide you with real world SEO code examples in Next.js, screenshots of how your site will look like in a popular search engine like Google and you will take away some SEO tools with you towards the end of this article.
A lot of these techniques can be applied in react apps or for SEO in general but the examples here would be more focused on Next.js. 🚀
What is SEO? 🤠

SEO is search engine optimization. Just like you and I are communicating in English, SEO using HTML is a language used between a bot and your site 💜. The techniques used in SEO lets the bot know what your site consists of.
It is our responsibility to make it as easy as possible for the bot to read our content.
I recently revamped my entire site: https://kulkarniankita.com/ so we will be using that as an example.
Before we dive in, let's first understand how Mr. Bot works first,
Who is Mr.Bot? 🤖

We will be calling the bot that crawls our sites and search engines use Mr.bot throughout this post.
Mr.Bot performs 3 operations 🥉:
Crawling 🐊
it will discover pages and try to find them. If a website has referenced a URL to a blog post i.e. linking, then that is one way of discovering it. If your home page links to other internal pages, that is another way of crawling all the pages on your website.Indexing 🔎
Once discovered, Mr.bot will try to understand what's on the page and this is why we need to speak the same language that the browser understands. We will talk about those techniques in a bit.Ranking 🥇
Finally, it now has a handful of discovered pages and tried to understand what's on them. Now, it ranks and stores those based on that in a database. This ranking also varies based on your location, language, device etc.
When we try to search 🔎 for a term on a search engine like Google, it will look into the database where Mr. Bot 🤖 has stored all the pages and return the ones that are ranked higher. Mr. Bot does do a lot more but the above is a simplified version.
Now that we understand a bit more about, let's review some of the techniques we can implement to rank higher on Google:
Meta tags

The above is the title and description of my page kulkarniankita.com/newsletter. You might be wondering how I show up on Google on the first page on top.🤔
Well, I hope I get this popular in the future 🥰 but for now, I’m using a tool called SEO minion 🔗 that shows you how your site or a page will look like on Google. You can use this to test and make sure everything is okay.💯
📣 Call to Action: One thing I need to work on is reducing my description length as you can see the ellipsis which makes it difficult for my reader to know everything I have to say. The optimal length is between 50 to 160 characters and mine is 177 characters which is no beuno.
Next.js provides a component 🔗 that you can add to every page so the details of every page can be easily tweaked. This makes applying these SEO techniques a lot easier. 🙌 Here is an Example code 👩💻:
//pages/newsletter.js
import Head from 'next/head';
const Newsletter = () => {
return (
<>
<Head>
<title>This is Ankita Kulkarni's newsletter</title>
<meta charSet="utf-8" />
<meta name="description" content={"A newsletter related to front-end development, leadership, career development, my journey into content creation, and lots more behind the scenes that I don't share anywhere else"} />
</Head>
<div>rest of the content...</div>
</>
);
}
export default Newsletter;
Socials: Facebook and Twitter 🐧
When we share a link to a post like a newsletter, for example, https://kulkarniankita.com/newsletter once that’s shared on social media like Twitter or Facebook, here is what we see:
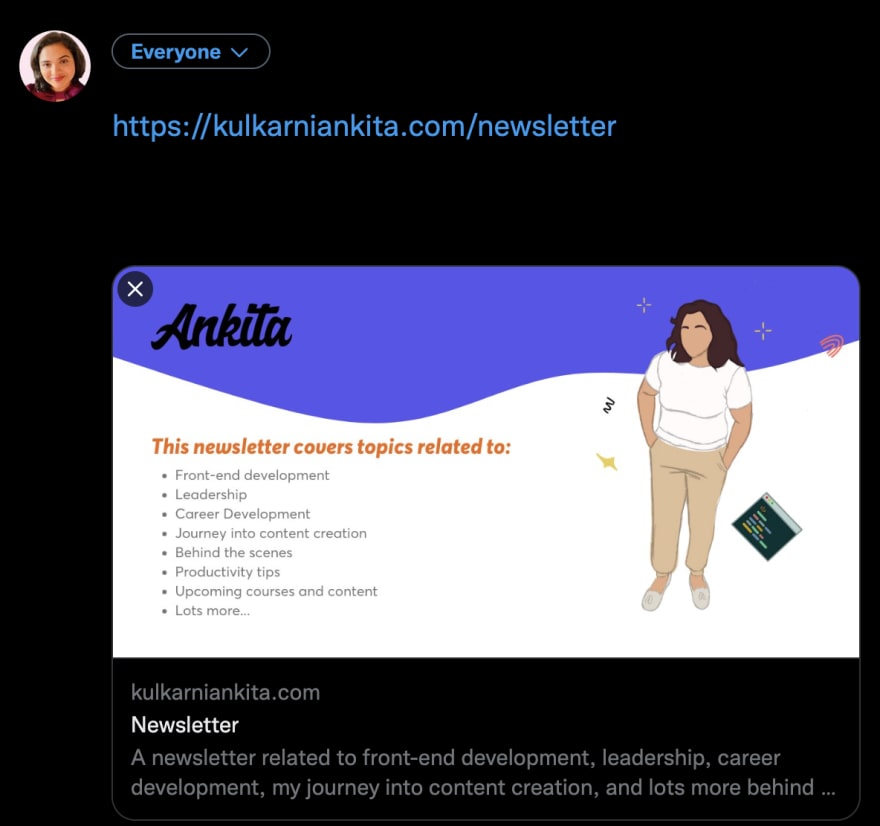
Notice how the title is a newsletter, it has a description of what this page is all about and also has an image. This is a good example of how meta tags for socials work. They do have a name and are known as Open Graph tags.📉
What is Open Graph?**
Open Graph 🔗 is a protocol that enables web pages to become a right fit for social media. Notice the name “graph” in its name. That’s because it creates a graph object of your metadata. Its goal is to provide simplicity for developers and one protocol for all social media.✨
Here is an example for those og meta tags 👩💻:
<meta property="og:title" content={'Newsletter'} />
<meta property="og:type" content="website" />
<meta property="og:description" content={"A newsletter related to front-end development, leadership, career development, my journey into content creation, and lots more behind the scenes that I don't share anywhere else"} />
<meta property="og:image" content={'/images/ogImage.png'} /> // for example: https://kulkarniankita.com/images/newsletter.png
<meta property="og:image:alt" content={ogImageAlt} />
<meta property="og:image:width" content="1200" />
<meta property="og:image:height" content="627" />
<meta property="og:url" content={ogUrl} />
There are 2 tools you can use to test your site for SEO:
They will give you a visual of what your crawled website looks like on social.
The other tags shown in the example are a bit more obvious as the title refers to the title of the page, the description refers to the description, image is the image of the page when your site page is shared. But what are canonical URLs?
Canonical URLs ♾

They are permanent IDs in the graph that we talked about earlier.
How you can represent a canonical URL:
<link rel="canonical" href={PROD_URL + canonicalUrl} />
og:url is how canonical URLs are represented for socials and rel="canonical" is how your individual pages are treated as canonical pages. As Mr. Bot reviews these meta tags, canonical URL's become the id in the graph which are sort of permanent.
They should represent your page in a human-readable way. The name id might confuse you as you might assume that it needs to be some auto-generated id like asdswpp but instead, it’s the opposite ╳, it should indicate what kind of content is in that URL 🔗 when a user navigates to it.
For example 👇,
good canonical URL ✅:
https://kulkarniankita.com/next.js/lets-get-data-rich-with-nextjs-visualization
bad Canonical URL ❌:
https://kulkarniankita.com/next.js/l
Behind the scenes, your blog posts or products might use a URL like this:
/products/lip-gloss?variant=123 ❌
but you should format it and set the canonical URL as:
/products/lip-gloss/pink ✅
Shopify wrote a great article which further elaborates canonical URLs, check it out here.
SEO React Component 🍱

Imagine you have a site that has a list of blog posts, newsletter, about-me image and more, you will be copy pasting more or less similar tags with variations in title, description, image etc. on every page. Now, this is not clean code and you might miss some important tags that would have a huge impact on SEO.😮
Instead, I would recommend creating a React component. For example, I have a component called SEO. This component accepts props such as title, description, og tags names, and more. I also provide default values too just in case I forget to provide those. This helps me stay organized and the existence of SEO component assures me and puts me at ease that I'm consistently taking care of SEO.😌
Here is an example 👩💻:
import Head from 'next/head';
const SEO = ({ title, description = '', canonicalUrl, ogImage, ogDescription, ogTitle, ogUrl }) => {
const metaDesc = 'Articles for developers and leaders focused on Next.js, GraphQL, leadership and more;
<Head>
<title>{title}</title>
<meta charSet="utf-8" />
<meta name="description" content={description || metaDesc} />
<meta property="og:title" content={'Newsletter'} />
<meta property="og:type" content="website" />
<meta property="og:description" content={ogDescription || description} />
<meta property="og:image" content={'/images/ogImage.png'} /> // for example: https://kulkarniankita.com/images/newsletter.png
<meta property="og:image:alt" content={'image for page featured with title'} />
<meta property="og:image:width" content="1280" />
<meta property="og:image:height" content="675" />
<meta property="og:url" content={ogUrl || canonicalUrl} />
<Head>
}
export default SEO;
You can customize the above SEO component based on your needs but the above code will give you a rough idea. It also helps you avoid any mistakes. I promise you I have caught many SEO mistakes because of this. 🤠
What are Sitemaps? 📍

A sitemap is an XML or a text file where you can provide information about all the pages and files in your web app. Mr. Bot 🤖 will look for this file and read it while crawling the site. You can tell which pages are important ✅ and which ones should not be crawled. ❌
You might need a sitemap if your site is large but might not if it’s small. You can read more here 🔗 although I would recommend creating it as we are trying to make our communication with Mr. Bot as smooth as possible.
The important piece I implemented on my website was to only include canonical URLs that I preferred to be indexed by Mr. Bot 🤖 i.e. if your site has 2 ways of reaching the same content, add the URL you want people to discover to your sitemap. You can read more on how to build one here for specifics. Although here is how I built it in Next.js.
If your site only has non-dynamic content i.e. no blog but only a few static pages, you can create a very simple sitemap that looks like this: 👩💻
const PROD_URL = 'https://www.kulkarniankita.com';
const generateSitemap = `<?xml version="1.0" encoding="UTF-8"?>
<urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9">
<url>
<loc>${`${PROD_URL}/aboutme`}</loc>
</url>
<url>
<loc>${`${PROD_URL}/newsletter`}</loc>
</url>
</urlset>
`;
But the chances are that your site does contain dynamic pages therefore the above sitemap needs to be created dynamically for example, if you have a list of blog posts like I do. For that, I would recommend creating a page in Next.js that returns XML data. You can do that by creating a file called sitemap.xml.js inside the pages directory.👩💻
sitemap.xml.js
const PROD_URL = 'https://www.kulkarniankita.com';
const generateSitemap = (posts) => `<?xml version="1.0" encoding="UTF-8"?>
<urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9">
${posts
.map((slug) => {
return `
<url>
<loc>${`${PROD_URL}/${slug}`}</loc>
</url>
`;
})
.join('')}
</urlset>
`;
function Sitemap() {}
Sitemap.getInitialProps = async (ctx) => {
const { res } = ctx;
const allPosts = getBlogPostsData();
const staticPages = ['', 'about', 'blog', 'courses', 'conferences', 'about'];
const allPages = [
...allPosts.map(({ categorySlug, slug }) => `${categorySlug}/${slug}`),
...staticPages,
];
res.setHeader('Content-Type', 'text/xml');
res.write(generateSitemap(allPages));
res.end();
}
export default Sitemap;
Why getInitialProps? 🤔
getInitialProps is great for SEO 💯 as it will send the data before the page gets rendered from the server.
Notice how we are setting the header as text/xml and writing XML as a response. This is because we don’t want anything else but XML to get dynamically rendered since the format of our sitemap is going to be XML.
Here is a condensed version of sitemap looks like: 👇

robots.txt 🦾
Mr. Bot uses robots.txt to figure out where your sitemap is located so we need to generate robots.txt as well. Here is how robots.txt will look like:
User-agent: *
Allow: /
Disallow: /nogooglebot/
Sitemap: https://www.kulkarniankita.com/<location-of-sitemap.xml>
Host: https://www.kulkarniankita.com
You can disallow specific pages to be indexed by Disallow property whereas Allow indicates that all other user agents are allowed to crawl the entire site.
The site's sitemap file is located at the URL specified in Sitemap property.
Static Generation in Next.js
By default, in Next.js all your content will be pre-rendered i.e all the HTML content will be available in advance vs having it all done on client-side JavaScript. This proves to be great for SEO as when Mr. Bot 🤖 is looking to crawl your data and review HTML, it will find all the text of that site. This is a huge advantage of using Next.js.
That's a wrap, hope this post was useful. 🙌 There is a lot more to SEO for which I'll create a part 2 of this article as I build my blog further.
If you would like to learn more about Next.js, I have a course on 2 platforms: Udemy and Zero to Mastery.
Intersection of Frontend and Leadership 💌:
If you found this article helpful, you will like my newsletter 💌! I write a weekly newsletter on content related to front-end development, leadership, career development, my journey into content creation, and lots more behind the scenes that I don’t share anywhere else. If you would like to know more or would like to subscribe, visit the link below: https://kulkarniankita.com/newsletter





Latest comments (0)