Hello! Today we will deploy a serverless infrastructure based on AWS Lambda for uploading images (or any other files) with private storage in an AWS S3 bucket. We will be using terraform scripts that are uploaded and available at my kompotkot/hatchery GitHub repository.
This approach has the following advantages:
- lambda is called on request and therefore allows to save on server maintenance costs if this functionality is not key for your application
- lambda functions have an isolated runtime environment, which is ideal for processing uploaded files. Should malicious code be uploaded, the attacker will not be able to leave the sandbox, and the sandbox session will be forcibly terminated after some time
- storing files in an S3 bucket is very cheap
Project structure
As an example, we'll be using an abstract app for journal entries with an API.
We can upload an image in each entry, and the structure is similar to a file directory:
- journal_1
- entry_1
- image_1
- entry_2
- image_1
- image_n
- entry_n
- journal_n
Our hypothetical API has an endpoint for receiving an entry in a journal:
curl \
--request GET \
--url 'https://api.example.com/journals/{journal_id}/entries/{entries_id}'
--header 'Authorization: {token_id}'
If in response to this endpoint status_code is equal to 200, it means the user is authorized and has access to the journal. Accordingly, we will let them store images for this entry.
Registering the app on Bugout.dev
To avoid adding an extra table to the database, which we would need for storing which image belongs to which entry, we will use resources from Bugout.dev. This approach is used to simplify our infrastructure, but, if required, this step can be substituted for creating a new table in your database and writing an API for creating, modifying, and deleting data about the stored images. Bugout.dev is open source and you can review the API documentation at the GitHub repository.
We will need an account and a team called myapp (you can use any name in relation to your project) at the Bugout.dev Teams page, you should save this team’s ID for the next step (in our case it’s e6006d97-0551-4ec9-aabd-da51ee437909):

Next, let’s create a Bugout.dev Application for our team myapp through a curl request (the token can be generated at the Bugout.dev Tokens page) and save it in the BUGOUT_ACCESS_TOKEN variable:
curl \
--request POST \
--url 'https://auth.bugout.dev/applications' \
--header "Authorization: Bearer $BUGOUT_ACCESS_TOKEN" \
--form 'group_id=e6006d97-0551-4ec9-aabd-da51ee437909' \
--form 'name=myapp-images' \
--form 'description=Image uploader for myapp notes' \
| jq .
In response we will get confirmation of a successfully created application:
{
"id": "f0a1672d-4659-49f6-bc51-8a0aad17e979",
"group_id": "e6006d97-0551-4ec9-aabd-da51ee437909",
"name": "myapp-images",
"description": "Image uploader for myapp notes"
}
The ID f0a1672d-4659-49f6-bc51-8a0aad17e979 will be used for storing resources, where every resource is the uploaded image’s metadata. The structure is set in any form depending on the required keys, in our case, it will look as follows:
{
"id": "a6423cd1-317b-4f71-a756-dc92eead185c",
"application_id": "f0a1672d-4659-49f6-bc51-8a0aad17e979",
"resource_data": {
"id": "d573fab2-beb1-4915-91ce-c356236768a4",
"name": "random-image-name",
"entry_id": "51113e7d-39eb-4f68-bf99-54de5892314b",
"extension": "png",
"created_at": "2021-09-19 15:15:00.437163",
"journal_id": "2821951d-70a4-419b-a968-14e056b49b71"
},
"created_at": "2021-09-19T15:15:00.957809+00:00",
"updated_at": "2021-09-19T15:15:00.957809+00:00"
}
As a result, we have a remote database, where every time we upload an image to an S3 bucket, we’ll be writing which journal(journal_id) and which entry(entry_id) the image was added to under which ID, name, and extension.
Preparing the AWS project environment
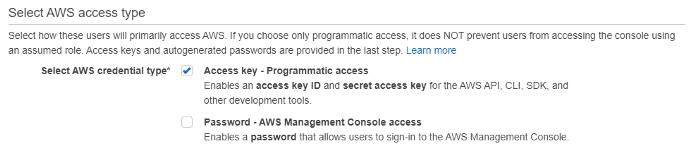
AWS will store images in an S3 bucket and function as a server on Lambda for image manipulation. We will need an AWS account and a configured IAM user for terraform. It is an account with Programmatic access to all resources without having access to the web console:
Get the access keys and add these variables to your environment:
export AWS_ACCESS_KEY_ID=<your_aws_terraform_account_access_key>
export AWS_SECRET_ACCESS_KEY=<your_aws_terraform_account_secret_key>
Let’s also deploy a VPC with the subnets:
- 2 subnets with private access
- 2 subnets with public access
They will be useful for configuring the AWS Load Balancer. The code for this module can be found under files_distributor/network. Let’s edit the variables in the variables.tf file and launch the script:
terraform apply
From the output, add environment variables with values AWS_HATCHERY_VPC_ID, AWS_HATCHERY_SUBNET_PUBLIC_A_ID and AWS_HATCHERY_SUBNET_PUBLIC_B_ID.
Server code
In our project, we’ll be using a simple AWS Lambda function. In my experience, I’ve noticed that as the packet with code surpasses 10MB, the upload speed to AWS drops dramatically. Even if we upload it to the S3 bucket in advance and then make a lambda from it, AWS can freeze for a long time. Therefore, if you are using third-party libraries it can make sense to use lambda layers, whereas if you aren’t planning to use any libraries with lightweight code on CloudFront, consider looking into lambda@edge.
The full code can be found in the lambda_function.py file in the repository. In my opinion, it’s more effective to work with nodejs, but to facilitate in-depth file processing we’ll use python. The code consists of main blocks:
MY_APP_JOURNALS_URL = "https://api.example.com" # API endpoint for accessing out journal entries app
BUGOUT_AUTH_URL = "https://auth.bugout.dev" # Bugout.dev endpoint for writing resources (image metadata)
FILES_S3_BUCKET_NAME = "hatchery-files" # S3 bucket name, where we’ll store the images
FILES_S3_BUCKET_PREFIX = "dev" # S3 bucket prefix, where we’ll store the images
BUGOUT_APPLICATION_ID = os.environ.get("BUGOUT_FILES_APPLICATION_ID") # Bugout.dev application ID that we created prior
Let’s expand the default exception to proxy the response from Bugout.dev Resources. E.g., if the image does not exist, when we request the resource, we’ll receive error 404, which we’ll in turn return to the client as a reply to the request for the missing image.
class BugoutResponseException(Exception):
def __init__(self, message, status_code, detail=None) -> None:
super().__init__(message)
self.status_code = status_code
if detail is not None:
self.detail = detail
To save an image in an S3 bucket we’ll use the cgi standard library that’ll let us parse the request’s body that was sent in multipart/<image_type> format. We’ll save images under the path {journal_id}/entries/{entry_id}/images/{image_id} without specifying the file’s name and extension.
def put_image_to_bucket(
journal_id: str,
entry_id: str,
image_id: UUID,
content_type: str,
content_length: int,
decoded_body: bytes,
) -> None:
_, c_data = parse_header(content_type)
c_data["boundary"] = bytes(c_data["boundary"], "utf-8")
c_data["CONTENT-LENGTH"] = content_length
form_data = parse_multipart(BytesIO(decoded_body), c_data)
for image_str in form_data["file"]:
image_path = f"{FILES_S3_BUCKET_PREFIX}/{journal_id}/entries/{entry_id}/images/{str(image_id)}"
s3.put_object(
Body=image_str, Bucket=FILES_S3_BUCKET_NAME, Key=image_path
)
When we extract an image from the S3 bucket we’ll need to encode it into base64 for correct transmission.
def get_image_from_bucket(journal_id: str, entry_id: str, image_id: str) -> bytes:
image_path = f"{FILES_S3_BUCKET_PREFIX}/{journal_id}/entries/{entry_id}/images/{image_id}"
response = s3.get_object(Bucket=FILES_S3_BUCKET_NAME, Key=image_path)
image = response["Body"].read()
encoded_image = base64.b64encode(image)
return encoded_image
The lambda_handler(event,context) function’s implementation is available at this GitHub link, to sum up:
- Firstly, we assert that the request is formatted correctly and contains
journal_idandentry_id - Then we call our hypothetical app’s API
https://api.example.com/journals/{journal_id}/entries/{entry_id} - Depending on the request method:
GET,POSTorDELETEwe read, upload or delete an image from the journal’s entry - When we’re uploading to the S3 bucket, we check the extension and the file’s size. This can be expanded into hash verification to avoid uploading the same file, etc.
Next, we’ll need to package requests into the Lambda library. Luckily, boto3 for work with AWS functionality is ready out of the box. Let’s create an empty python environment, install the library and package the contents of site-packages:
python3 -m venv .venv
source .venv/bin/activate
pip install requests
cd .venv/lib/python3.8/site-packages
zip -r9 "lambda_function.zip" .
Place the created archive lambda_function.zip into the files_distributor/bucket/modules/s3_bucket/files directory and add the Lambda function itself:
zip -g lambda_function.zip -r lambda_function.py
Our server is ready, now we can upload code to AWS and deploy Lambda server, to do so use the script in files_distributor/bucket:
terraform apply
We’re left with:
- A private AWS S3 bucket
hatchery-sourcesthat stores the Lambda function code - A private AWS S3 bucket
hatchery-filesthat we’ll store our images into with the prefixdev - AWS Lambda function with working server code
- An IAM role for the Lambda that allows writing into a specific S3 bucket and logs
The IAM role rules are in files_distributor/bucket/modules/iam/files/iam_role_lambda_inline_policy.json. The other file iam_role_lambda_policy.json is needed for the Lambda to function works correctly.
To debug Lambda you can just print the required values or use the standard logging module for python. The output for every Lambda function call is available at AWS CloudWatch:

After creating the function, add a variable BUGOUT_FILES_APPLICATION_ID from our code to the Lambda environment, which you can do in the tab Configuration/Environment variables.
As the last step, save the AWS Lambda arn into the environment variable AWS_HATCHERY_LAMBDA_ARN.
Configuring the AWS Load Balancer and open ports
The only step left now is to create AWS Security Group where we’ll set a port the AWS Load Balancer will listen to for subsequent data transmit into the Lambda function (in our case it’s 80 and 443).
terraform apply \
-var hatchery_vpc_id=$AWS_HATCHERY_VPC_ID \
-var hatchery_sbn_public_a_id=$AWS_HATCHERY_SUBNET_PUBLIC_A_ID \
-var hatchery_sbn_public_b_id=$AWS_HATCHERY_SUBNET_PUBLIC_B_ID \
-var hatchery_lambda_arn=$AWS_HATCHERY_LAMBDA_ARN
Congratulations, our AWS Lambda function is open to the world and ready to upload and return images for our journal entries app!





Top comments (0)