In this post, I am going to show you common sorting algorithms and provide their implementation in python.
If you are a programmer or if you have already been interviewed for a job, then you surely know the importance of knowing and mastering algorithms in order to increase your coding level or have a chance to get hired.
Even if they may seem easy, they can really become tricky.

And that's why you should practice a lot.
As a wise man said on Quora:
Algorithms are made to be practiced, not learned.
I think that you got the point, so let's dive in.
Sorting Algorithms
When working with data, sorting is one of the essentials tasks. Even if there is a lot of methods to sort data, some of them are better than others, some are more efficient for specific usages.
Depending on the method ( recursion, iteration, comparisons ) or the data structures used, you can have a lot of possibilities.
8 must-know Sorting Algorithms
This section focus on explaining each algorithm: the concept, the complexity, and the use cases. I also provided solutions for each algorithm written in Python, however, if you want to challenge yourself, try it on your own before check it.😉
Bubble Sort
Bubble sort a simple sorting algorithm that works by swapping the items between them if they are in the wrong order.
Example :

Bubble Sort from WikiPedia
#Bubble Sort Algorithm
def bubbleSort(data):
lenght = len(data)
for iIndex in range(lenght):
swapped = False
for jIndex in range(0, lenght - iIndex - 1):
if data[jIndex] > data[jIndex + 1]:
data[jIndex], data[jIndex + 1] = data[jIndex + 1], data[jIndex]
swapped = True
if swapped == False:
break
print(data)
- The worst and average-case complexity of the Bubble Sort is О(n2), meaning that the data is in the opposite order we want to sort, or the elements are arbitrarily distributed in the list.
- The best-case complexity is O(n). That's the case where the data is already sorted.
Bubble sort is used when :
- simple code is preferred;
- the complexity doesn't matter.
Selection Sort
Selection Sort is an ameliorated version of Bubble Sort because of the performance. Even if they have the same worst-case performance, Selection Sort performs fewer swaps.
Selection sort works in one of two ways: It either looks for the smallest item in the list and places it in the front of the list (ensuring that the item is in its correct location) or looks for the largest item and places it in the back of the list.
Example:

Selection sort of animation. Red is the current min. Yellow is a sorted list. Blue is the current item. Wikipedia
Code
#Selection Sort Algorithm
def selectionSort(data):
for scanIndex in range(0, len(data)):
minIndex = scanIndex
for compIndex in range(scanIndex + 1, len(data)):
if data[compIndex] < data[minIndex]:
minIndex = compIndex
if minIndex != scanIndex:
data[scanIndex], data[minIndex] = data[minIndex], data[scanIndex]
print(data)
Selection Sort has the same complexities as Bubble Sort.
Selection Sort is used when:
- Sorting small arrays
- checking off all the elements is compulsory
- Less swapping is required
Insertion Sort
Insertion is a brute-force sorting algorithm but it does fewer comparisons than the Selection sort.
Insertion Sort works by choosing an item and by ordering the directs neighbors whether they are greater/smaller than the chosen item. As the number of sorted items builds, the algorithm checks new items against the sorted items and inserts the new item into the right position in the list.
Example :

Image from Wikipedia
Code:
#Insertion Sort Algorithm
def insertionSort(data):
for scanIndex in range(1, len(data)):
tmp = data[scanIndex]
minIndex = scanIndex
while minIndex > 0 and tmp < data[minIndex - 1]:
data[minIndex] = data[minIndex - 1]
minIndex -= 1
data[minIndex] = tmp
print(data)
- Insertion Sort has a worst and average complexity case of O(n2). This occurs respectively when the array is sorted in reverse order and when the elements are arbitrarily organized in the array.
- The best-case complexity is O(n). It occurs when the data is already sorted in the desired order.
Insertion Sort is used when :
- There are a few elements left to sort;
- The array is small.
QuickSort
QuickSort is an efficient sorting algorithm. It uses the divide-conquer approach to split the array into sub-arrays that is recursively called to sort the elements.
Implement a QuickSort algorithm requires to choose a pivot, then split the array into two sub-arrays according to the pivot, then arrange them following if they are greater/smaller than the pivot. Then we sort the two sub-arrays and repeat the process again.
Example :
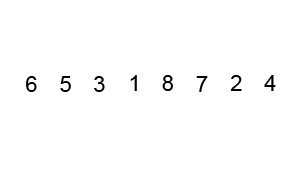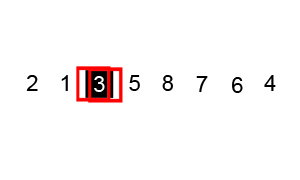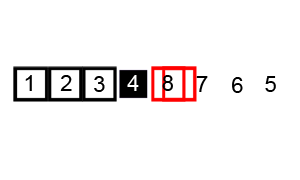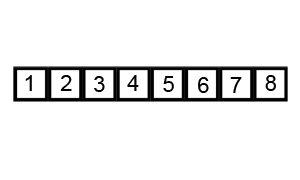
Image from Wikipedia
Code:
#Quick Sort Algorithm
def quickSort(data, left, right):
if right<= left:
return
else:
pivot = partition(data, left, right)
quickSort(data, left, pivot - 1)
quickSort(data, pivot + 1, right)
return data
def partition(data, left, right):
"""This function chooses a pivot point that dertermines the left and right side of the sort"""
pivot = data[left]
leftIndex = left + 1
rightIndex = right
while True:
while leftIndex <= rightIndex and data[leftIndex] <= pivot:
leftIndex += 1
while rightIndex >= leftIndex and data[rightIndex] >= pivot:
rightIndex -= 1
if rightIndex <= leftIndex:
break
data[leftIndex], data[rightIndex] = data[rightIndex], data [leftIndex]
print(data)
data[left], data[rightIndex] = data[rightIndex], data[left]
print(data)
return rightIndex
- QuickSort has worst-case complexity of O(n2). It occurs when the pivot element picked is always either the greatest or the smallest element.
- The best-case and average-case complexity are O(n*log(n)). It occurs when the pivot element is always the middle element or near to the middle element.
QuickSort is used when :
- Recursion is needed and supported;
- The array is small;
- There are a few elements left to sort.
MergeSort

A Mergesort works by applying the divide and conquer approach. The sort begins by breaking the dataset into individual pieces and sorting the pieces. It then merges the pieces in a manner that ensures that it has sorted the merged piece.
The sorting and merging continue until the entire dataset is again a single piece.
Example:

An example of a merge sort. First divide the list into the smallest unit (1 element), then compare each element with the adjacent list to sort and merge the two adjacent lists. Finally, all the elements are sorted and merged. Wikipedia
Code:
#Merge Sort Algorithm
def mergeSort(data):
"""This function determines whether the list is broken
into individual parts"""
if len(data) < 2:
return data
middle = len(data)//2
# We break the list in two parts
left = mergeSort(data[:middle])
right = mergeSort(data[middle:])
# Merge the two sorted parts into a larger piece.
print("The left side is: ", left)
print("The right side is: ", right)
merged = merge(left, right)
print("Merged ", merged)
return merged
def merge(left, right):
"""When left side/right side is empty,
It means that this is an individual item and is already sorted."""
#We make sure the right/left side is not empty
#meaning that it's an individual item and it's already sorted.
if not len(left):
return left
if not len(right):
return right
result = []
leftIndex = 0
rightIndex = 0
totalLen = len(left) + len(right)
#
while (len(result) < totalLen):
#Perform the required comparisons and merge the two parts
if left[leftIndex] < right[rightIndex]:
result.append(left[leftIndex])
leftIndex += 1
else:
result.append(right[rightIndex])
rightIndex += 1
if leftIndex == len(left) or rightIndex == len(right):
result.extend(left[leftIndex:] or right[rightIndex:])
break
return result
- MergeSort has worst-case and average-case complexity of O(n*log(n)) which makes it fastest than some of the other sorting algorithms.
Bucket Sort
Bucket Sort algorithm work by dividing the array into buckets. Then the elements in each bucket are sorted using any sorting algorithms or by recursively calling the Bucket Sort algorithm.
The process of bucket sort can be view as a scatter-gather approach. The elements are first scattered into buckets then the elements of buckets are sorted. Finally, the elements are gathered in order.
Example:
![]()
![]()
Code:
#Bucket Sort Algorithm
def bucketSort(data):
bucket = []
for iIndex in range(len(data)):
bucket.append([])
for jIndex in data:
index_bucket = int(10 * jIndex)
bucket[index_bucket].append(jIndex)
print(bucket)
for iIndex in range(len(data)):
#I used the built-in method sorted() to sort the array.
bucket[iIndex] = sorted(bucket[iIndex])
kIndex = 0
for iIndex in range(len(data)):
for jIndex in range(len(bucket[iIndex])):
data\[kIndex] = bucket[iIndex\][jIndex]
kIndex += 1
print(data)
- Bucket Sort algorithm has the worst-case complexity of O(n2). It occurs when elements in the same range are put in the same bucket, resulting in more elements in some buckets than others. Also, it can be even worse when an inappropriate sorting algorithm is used to sort elements in the buckets.
- The best-case complexity is O(n+k). It occurs when the elements are uniformly distributed in the buckets with a nearly equal number of elements in each bucket. It can even be better if the array is already sorted.
- The average-case complexity is O(n). It occurs when elements are randomly distributed in the array.
Bucket Sort is used when :
- With floating numbers;
- Input is uniformly distributed over a range.
Shell Sort
Shell Sort is a variation of Insertion Sort. With this algorithm, the array is sorted at a specific interval based on the chosen sequence. The interval between the elements is gradually decreased based on the sequence used. The performance of the shell sort depends on the type of sequence used for a given input array.
Example:

Gif from GfyCat
Code:
#Shell Sort Algorithm
def shellSort(data, length):
gap = length//2
while gap > 0:
for iIndex in range(gap, length):
temp = data[iIndex]
jIndex = iIndex
while jIndex >= gap and data[jIndex - gap] > temp:
data[jIndex] = data[jIndex - gap]
jIndex -= gap
data[jIndex] = temp
gap //= 2
print(data)
- Shell Sort has worst-case complexity less or equal than O(n2).
- Shell Sort has average-case and best-case complexity of
O(n*log(n)). - Shell Sort is used when:
- Recursion exceeds a limit.
- Insertion doesn't perform well when close elements are far.
Heap Sort
Heap Sort is one of the best sorting methods being in-place and with no quadratic worst-case complexity. Heap Sort uses a heap data structure.
A heap is a complete binary tree. It also verifies such rules as:
- children are smaller than parents;
- The largest/smallest element is at the root of the heap, depending on the way you sorted it.
To make a heap sort algorithm, we must create a heap of the array first. When done, we can now write the Heap Sort algorithm. The advantage with Heap Sort is that the value at the root is always greater than all value, so we can put it at the end of the sorted array, remove it from the heap, and then heapify the binary tree again to have the greater value at the top again.
Example:

Gif from Wikipedia
Code:
#Heap Sort Algorithm
def createHeap(data, length, index):
largest = index
left = 2 * index + 1
right = 2 * index + 2
if left < length and data[index] < data[left]:
largest = left
if right < length and data[largest] < data[right]:
largest = right
if largest != index:
data[index], data[largest] = data[largest], data[index]
createHeap(data, length, largest)
def heapSort(data):
length = len(data)
#We build max heap
for index in range(length, 0, -1):
createHeap(data, length, index)
for index in range(length -1, 0, -1):
data[index], data[0] = data[0], data[index]
createHeap(data, index, 0)
print(data)
Heap Sort has O(n*log(n)) time complexities for all the cases ( best case, average case, and worst case) making it one of the most used sorting algorithms.
Heapsort is great when you need to know just the "smallest" (or "largest") of a collection of items, without the overhead of keeping the remaining items in sorted order. For example, a Priority Queue.
Conclusion
In this article, I showed you must know algorithms with their implementation in Python. Every article can be made better so your suggestion or questions are welcome in the comment section.
If you also think that I missed some important sorting algorithm, let me know. 🤠
Check the code of all the sorting algorithms in this repo.





{kind=link}
Top comments (13)
Why is BubbleSort considered so important? I'd say it's the last failed algorithm you should know.
Important ones would be:
InsertionSort and it's efficient variations ShellSort and HeapSort. Because it has a O(N) best case behavior (when already sorted).
QuickSort, because in it's randomized version illustrates the power of random, and it's simplicity and raw speed.
MergeSort because of it's stability and usefulness in parallel algorithms, distributed algorithms, and databases (ie. Merge join)
RadixSoft because it's not a comparison algorithm and takes time O(n lg u) (which is MUCH faster than Quicksort). Van Embde Boas if you want to get really performant with these concepts with time O(n lg lg u).
BitonicSort because it's a basic parallel sorting algorithm and also used in the more sophisticated theoretical efficient sorting algorithms.
TimSort: because it's the one that's actually implemented in Python and Java so it's a good case study of a real world sorting algorithm.
But I think you can safely forget BubbleSort ever existed. I think SelectionSort is way more intuitive anyway.
Actually, BubbleSort IS an important sort, and anybody calling him or herself a Software engineer needs to understand how it works.
Reason? Well, you can't understand the concept of Light completely without understanding what the Darkness is. I know it's toooo dramatic but believe me, you need to know what bad algorithms are in order to understand the good ones.
sure.. though selection sort is sufficient to represent naive sorting..
but I'll grant that you have a point
Thanks for the answer. I will look to add TimSort to the article.
sorry I didn't mean to sound so dogmatic..
but wanted to share an alternative set of "essential" algorithms
2 comments.
First, I would introduce Mergesort before Quicksort. While Quicksort is of greater general importance, mergesort is a good introduction to the divide and conquer type of strategy. Since I would group quicksort as a div&conq algorithm, it makes sense to start with a "baseline" of mergesort before venturing into more complicated examples with partitions, etc.
On the "other" algorithms request, you could add Radix sort to the list, possibly as a augmentation to the bucket sort. One other algorithm worth mentioning might be Timsort given its (a) advanced nature and (b) ties to Python.
😀 This is awesome!
Thanks a lot! :)
Thanks so. It's very nice
Awesome post, fantastic job!
Thanks Derrick!
Excellent review, haven't looked at these since programming class (JAVA), nice to see Python code for each.. Keep it up!
Nice article. Though it could be much much and much better if you had added the complete gifs. As you know if a picture is worth a thousand words then a good gif is certainly worth a million