
Greetings to my dear readers. I wrote an article about installing Apache PySpark in Ubuntu and explained about about Apache Spark. Read it here. Now lets go take a deep dive into PySpark and know what it is. This article covers about Apache PySpark a tool that is used in data engineering, understand all details about PySpark and how to use it. One should have basic knowledge in Python, SQL to understand this article well.
What is Apache Spark?
Let first understand about Apache Spark, then we proceed to PySpark.
Apache Spark is an open-source, cluster computing framework which is used for processing, querying and analyzing Big data. It lets you spread data and computations over clusters with multiple nodes (think of each node as a separate computer). Splitting up your data makes it easier to work with very large datasets because each node only works with a small amount of data.
What is Apache PySpark?

Originally it was written in Scala programming language, the open source community developed a tool to support Python for Apache Spark called PySpark. PySpark provides Py4j library, with the help of this library, Python can be easily integrated with Apache Spark. It not only allows you to write Spark applications using Python APIs, but also provides the PySpark shell for interactively analyzing vast data in a distributed environment. PySpark is a very demanding tool among data engineers.
Features of PySpark
Speed - PySpark allows us to achieve a high data processing speed, which is about 100 times faster in memory and 10 times faster on the disk.
Caching - PySpark framework provides powerful caching and good disk constancy.
Real-time - PySpark provides real-time computation on a large amount of data because it focuses on in-memory processing. It shows the low latency.
Deployment - We have local mode and cluster mode. In local mode it is a single machine fox example my laptop, convenient for testing and debugging. Cluster mode there is set of predefined machines and its good for production.
PySpark works well with Resilient Distributed Datasets (RDDs)
Running our cluster locally
To start any Spark application on a local cluster or a dataset, we use SparkConf to set some configuration and parameters.
Commonly used features of the SparkConf when working with PySpark:
set(key, value)-
setMastervalue(value) -
setAppName(value)-
get(key,defaultValue=None) -
setSparkHome(value) -
The following example shows some attributes of SparkConf:
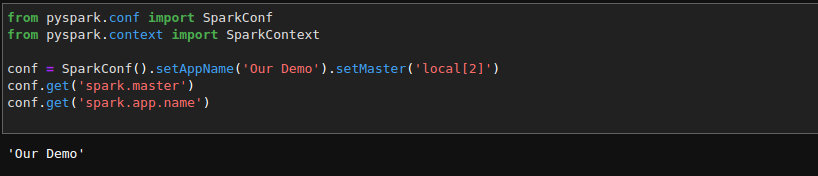
A spark program first creates a SparkContext object which tells the application how to access a cluster. To accomplish the task, you need to implement SparkConf so that the SparkContext object contains the configuration information about the application.
SparkContext
SparkContext is the first and essential thing that gets initiated when we run any Spark application. It is an entry gate for any spark derived application or functionality. It is available as sc by default in PySpark.
*Know that creating any other variable instead of sc will give an error.
Inspecting our SparkContext:
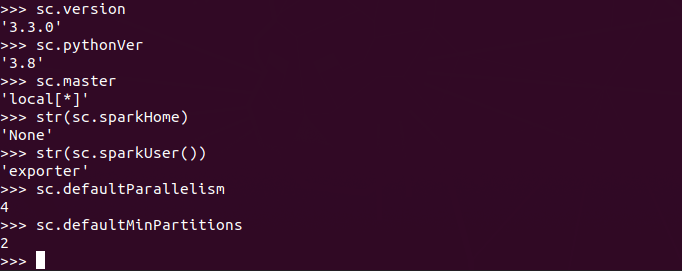
Master - The URL of the cluster connects to Spark.
appName - The name of your task.
The Master and Appname are the most widely used SparkContext parameters.
PySpark SQL
PySpark supports integrated relational processing with Spark's functional programming. To extract the data by using an SQL query language and use the queries same as the SQL language.
PySpark SQL establishes the connection between the RDD and relational table.It supports wide range of data sources and algorithms in Big-data.
Features of PySpark SQL:
Incorporation with Spark - PySpark SQL queries are integrated with Spark programs, queries are used inside the Spark programs. Developers do not have to manually manage state failure or keep the application in sync with batch jobs.
Consistence Data Access - PySpark SQL supports a shared way to access a variety of data sources like Parquet, JSON, Avro, Hive and JDBC.
User-Defined Functions - PySpark SQL has a language combined User-Defined Function (UDFs). UDF is used to define a new column-based function that extends the vocabulary of Spark SQL's DSL for transforming DataFrame.
Hive Compatibility - PySpark SQL runs unmodified Hive queries and allow full compatibility with current Hive data.
Standard Connectivity - It provides a connection through JDBC or ODBC, the industry standards for connectivity for business intelligence tools.
Important classes of Spark SQL and DataFrames are the following:
pyspark.sql.SparkSession: Represents the main entry point for DataFrame and SQL functionality.
pyspark.sql.DataFrame: Represents a distributed collection of data grouped into named columns.
pyspark.sql.Row: Represents a row of data in a DataFrame.
pyspark.sql.Column: Represents a column expression in a DataFrame.
pyspark.sql.DataFrameStatFunctions: Represents methods for statistics functionality.
pyspark.sql.DataFrameNaFunctions: Represents methods for handling missing data (null values).
pyspark.sql.GroupedData: Aggregation methods, returned by DataFrame.groupBy().
pyspark.sql.types: Represents a list of available data types.
pysark.sql.functions: Represents a list of built-in functions available for DataFrame.
pyspark.sql.Window: Used to work with Window functions.
import pyspark
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
from pyspark.sql import SparkSession
A spark session can be used to create the Dataset and DataFrame API. A SparkSession can also be used to create DataFrame, register DataFrame as a table, execute SQL over tables, cache table, and read parquet file.
class builder
It is a builder of Spark Session.
getOrCreate()
It is used to get an existing SparkSession, or if there is no existing one, create a new one based on the options set in the builder.
pyspark.sql.DataFrame
A distributed collection of data grouped into named columns. A DataFrame is similar as the relational table in Spark SQL, can be created using various function in SQLContext.
Then manipulate it using the several domain-specific-languages (DSL) which are pre-defined functions of DataFrame.
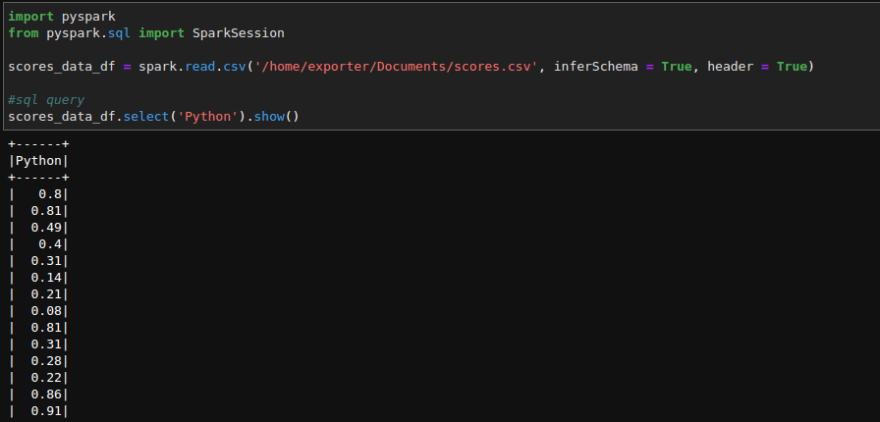
Querying Using PySpark SQL
This displays my file where sql queries are executed:

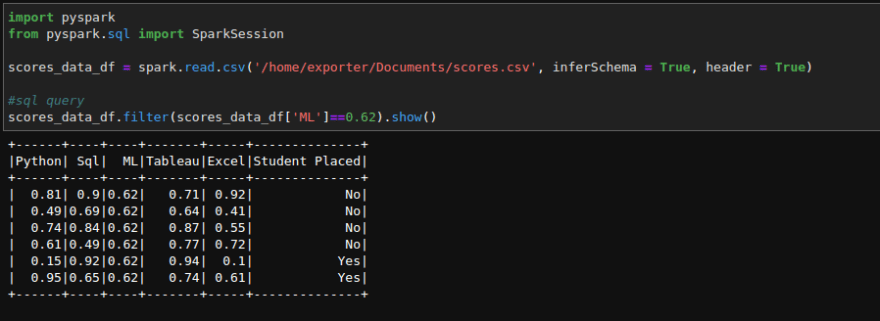
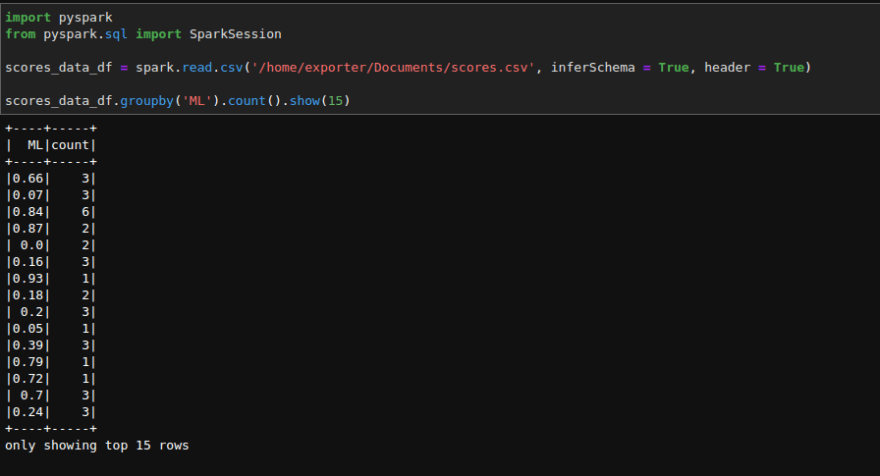
The groupBy() function collects the similar category data.
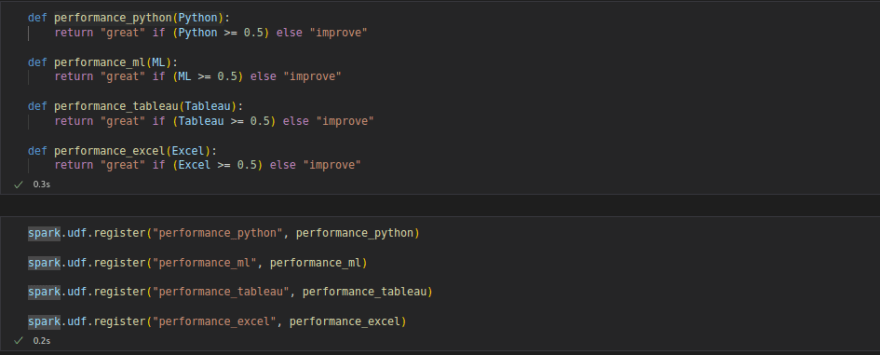
PySpark UDF
The PySpark UDF (User Define Function) is used to define a new Column-based function. Using User-Defined Functions (UDFs), you can write functions in Python and use them when writing Spark SQL queries.
You can declare a User-Defined Function just like any other Python function. The trick comes later when you register a Python function with Spark. To use functions in PySpark, first register them through the spark.udf.register() function.
It accepts two parameters:
name - A string, function name you'll use in SQL queries.
f - A Python function that contains the programming logic.
spark.udf.register()
Py4JJavaError, the most common exception while working with the UDF. It comes from a mismatched data type between Python and Spark.
An example of user define functions:
PySpark RDD(Resilient Distributed Dataset)
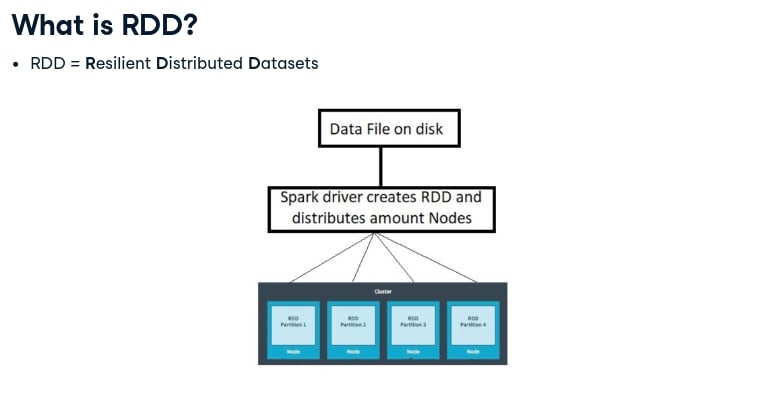
Resilient Distributed Datasets (RDDs) are essential part of the PySpark, handles both structured and unstructured data and helps to perform in-memory computations on large cluster. RDD divides data into smaller parts based on a key. Dividing data into smaller chunks helps that if one executor node fails, another node will still process the data.
In-memory Computation - Computed results are stored in distributed memory (RAM) instead of stable storage (disk) providing very fast computation
Immutability - The created data can be retrieved anytime but its value can't be changed. RDDs can only be created through deterministic operations.
Fault Tolerant - RDDs track data lineage information to reconstruct lost data automatically. If failure occurs in any partition of RDDs, then that partition can be re-computed from the original fault tolerant input dataset to create it.
Coarse-Gained Operation - Coarse grained operation means that we can transform the whole dataset but not individual element on the dataset. On the other hand, fine grained mean we can transform individual element on the dataset.
Partitioning - RDDs are the collection of various data items that are so huge in size, they cannot fit into a single node and must be partitioned across various nodes.
Persistence - Optimization technique where we can save the result of RDD evaluation. It stores the intermediate result so that we can use it further if required and reduces the computation complexity.
Lazy Evolution - It doesn't compute the result immediately means that execution does not start until an action is triggered. When we call some operation in RDD for transformation, it does not execute immediately.
PySpark provides two methods to create RDDs: loading an external dataset, or distributing a set of collection of objects.
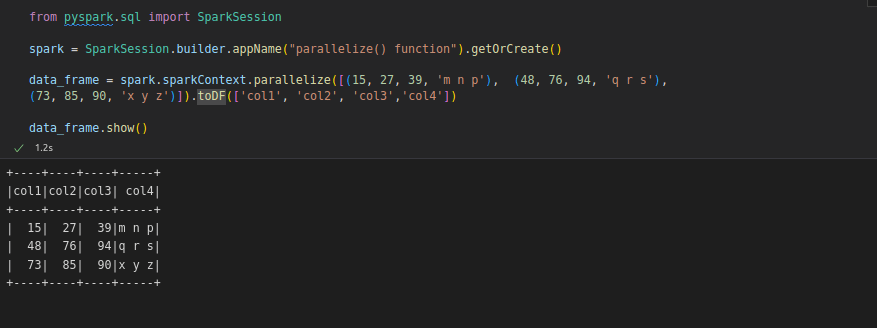
using parallelize
Create RDDs using the parallelize() function which accepts an already existing collection in program and pass the same to the Spark Context.
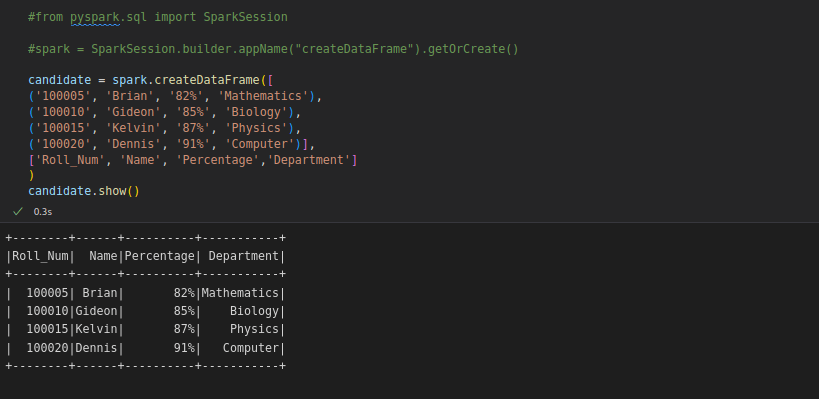
Using createDataFrame() function. We have already SparkSession, so we will create our dataFrame.
External Data
Read either one text file from HDFS, a local file system or any Hadoop-supported file system URI with textFile(), or read in a directory of text files with wholeTextFiles().

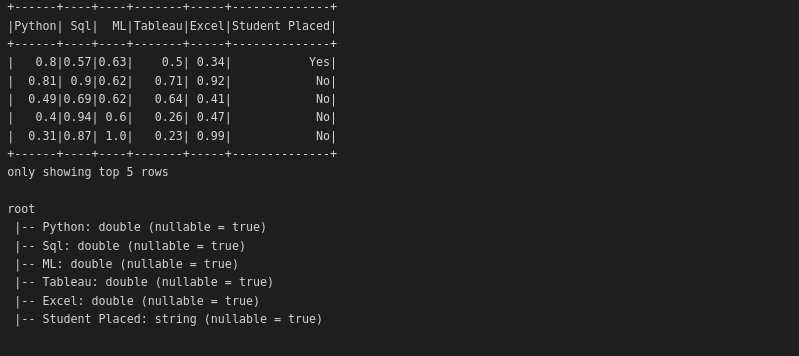
Using read_csv()

The output of using scores_file.show() and scores_file.printSchema()
RDD Operations in PySpark
RDD supports two types of operations:
Transformations - The process used to create a new RDD. It follows the principle of Lazy Evaluations (the execution will not start until an action is triggered). For example :
map, flatMap, filter, distinct, reduceByKey, mapPartitions, sortBy
Actions - The processes which are applied on an RDD to initiate Apache Spark to apply calculation and pass the result back to driver. For example :
collect, collectAsMap, reduce, countByKey/countByValue, take, first
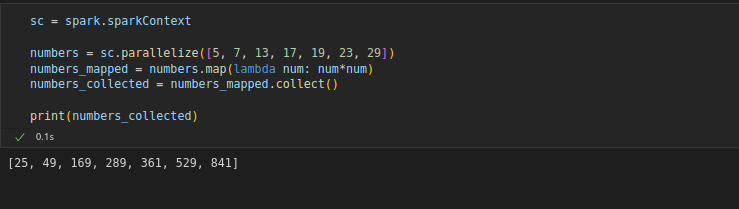
map() transformation takes in a function and applies it to each element in the RDD
collect() action returns the entire elements in the RDD
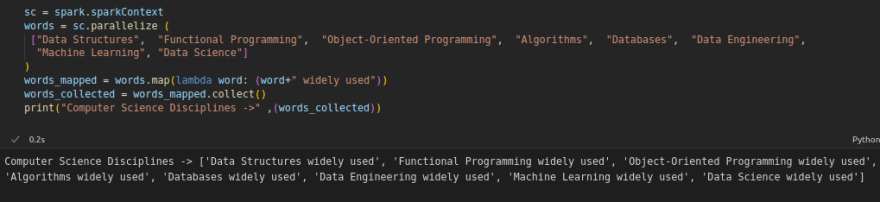
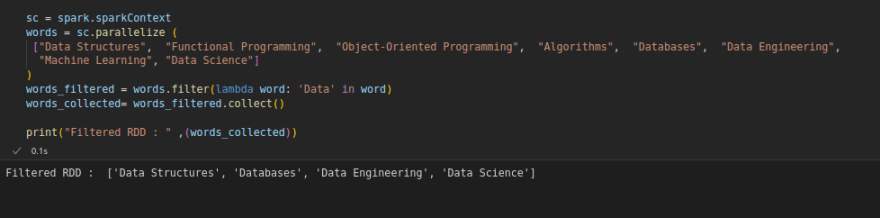
The RDD transformation filter() returns a new RDD containing only the elements that satisfy a particular function. It is useful for filtering large datasets based on a keyword.
Count() action returns the number of element available in RDD.
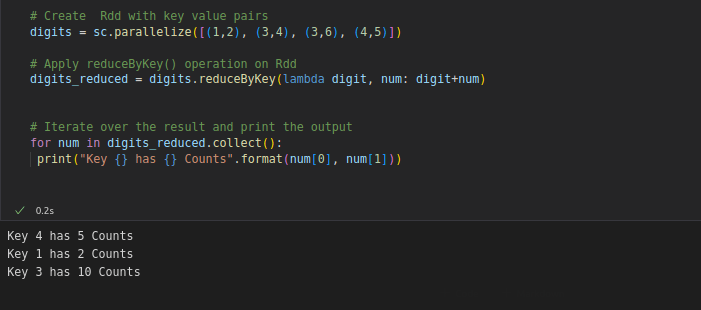
RDD transformation reduceByKey() operates on key, value (key,value) pairs and merges the values for each key.
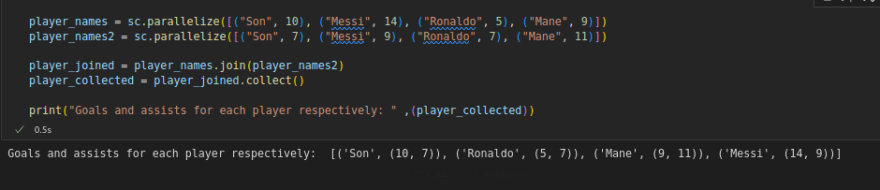
join() returns RDD with the matching keys with their values in paired form.
DataFrame from RDD
PySpark provides two methods to convert a RDD to DataFrame. These methods are:
toDF(), createDataFrame(rdd, schema)
DataFrames also have two operations: transformations and actions.
DataFrame transformations include: select, filter, groupby, orderby, dropDuplicates, withColumnRenamed.
- select() - subsets the columns in a DataFrame
- filter() - filters out rows based on a condition
- groupby() - used to group based on a column
- orderby() - sorts the DataFrame based on one or more columns
- dropDuplicates() - removes duplicate rows from a DataFrame.
- withColumnRenamed() - renames a columnn in the DataFrame
DataFrame actions include: head, show, count, describe, columns.
- describe() - compute the summary statistics of numerical columns in a dataFrame
- printSchema() - prints the types of columns in a DataFrame
- column - prints all the columns in DataFrame.
Inspecting Data in PySpark
# Print the first 10 observations
people_df.show(10)
# Count the number of rows
print("There are {} rows in the people_df DataFrame.".format(people_df.count()))
# Count the number of columns and their names
print("There are {} columns in the people_df DataFrame and their names are {}".format(len(people_df.columns), people_df.columns))
PySpark DataFrame sub-setting and cleaning
# Select name, sex and date of birth columns
people_df_sub = people_df.select('name', 'sex', 'date of birth')
# Print the first 10 observations from people_df_sub
people_df_sub.show(10)
# Remove duplicate entries from people_df_sub
people_df_sub_nodup = people_df_sub.dropDuplicates()
# Count the number of rows
print("There were {} rows before removing duplicates, and {} rows after removing duplicates".format(people_df_sub.count(), people_df_sub_nodup.count()))
Filtering your DataFrame
# Filter people_df to select females
people_df_female = people_df.filter(people_df.sex == "female")
# Filter people_df to select males
people_df_male = people_df.filter(people_df.sex == "male")
# Count the number of rows
print("There are {} rows in the people_df_female DataFrame and {} rows in the people_df_male DataFrame".format(people_df_female.count(), people_df_male.count()))
Stopping SparkContext
To stop a sparkContext:
sc.stop()
It's very crucial to understand Resilient Distributed Datasets(RDDs) and SQL since they will be extensively used in data engineering.
Conclusion
This article covers the key areas of Apache PySpark you should understand as you learn to become data engineer.you should be able to initialize Spark, use User Defined Functions (UDFs), load data, work with RDDs: apply actions and transformations. Soon I will write an article on a practical use case of Apache PySpark in a project.
Feel free to drop your comments about the article.





Top comments (4)
Hello, Kinyungu Denis
Do you have end-to-end project resource using Pyspark that we could follow and learn? because it's kind of boring if we only reading documentation only.
Hello, I am working on an end-to-end project that one can follow through, kindly be patient.
Asante Denis. Good read!
You are welcome, I hope you learnt a new concept