
What is Regex?
Regular expressions ( or regexes, or regex patterns) are essentially a kind of formal grammar/syntax used to find the set of possible strings that you want to match.
At first, REs can look pretty scary and daunting, but we can write highly efficient matching patterns in terms of length and speed after understanding even a few special characters.
We can use REs to save the day in a variety of use cases :
- Checking a pattern in string
- Splitting into strings
- Replacing part of strings
- Matching a complete string
- Cleaning raw data in Natural Language Processing

All major programming languages and even IDEs have their own standard module for regex where the syntax might change, but the underlying concept remains the same.
# python3
import re
pattern = re.compile("doge\\shen+lo+",re.I)
if pattern.match("Doge hennnloo") is not None:
print("Henlo Doge")
// javascript
const pattern = /doge\shen+lo+/i
if (pattern.test("Doge hennnloo")) {
console.log("Henlo Doge")
}
Let's get started 🚀
Normal Characters 🇦
You can use regex as you use normal strings/characters for matching too :
console.debug(/king-11/.test('king-11')) // returns true
But certain special characters have to be escaped because they carry special meaning in regex.
\ / [ ] { } . ? + * ^ $ | ( )
// we have to escape back slash in string to be tested as well
console.debug(/\\\/\[\]\{\}\.\?\+\*\^\$\|\(\)/.test('\\/[]{}.?+*^$|()'))
// returns true
Character Class and Regex Characters 🧑🏼🤝🧑🏼
A character class allows you to define a set of characters from which a match is considered if any of the characters match.
/[aeiou]/.test('e') // returns true
/[aeiou]/.test('c') // returns false
You can also provide range values to regex for defining character classes using -.
/[a-z]/.test('l') // returns true matches all lowercase alphabets
/[A-Z]/.test('L') // returns true matches all uppercase alphabets
/[0-9]/.test('8') // returns true matches all digits from 0 to 9
/[0-5]/.test('8') // returns false matches all digits from 0 to 5
But if you want to match -, you have to escape it or keep it at the start or end of character class, i.e. [].
/[0\-5]/.test('-')
// returns true matches 0, 5, -
/[-0-5]/.test('-')
// returns true matches digits from 0 to 5 and -
We can define complement character class, i.e. characters we don't want to match, by adding ^ at the start of our class.
/[^a-z]/.test('A')
// returns true doesn't match any lowercase alphabet
Inside a character class, only two characters carry special meaning - in-between characters and ^ at the start of the class rest all other characters don't carry their special meaning; hence we don't need to escape them.
/[$+]/.test('$') // returns true matches $ and +
You can define character classes for things like alphabets and digits but regex makes it easier for you by defining several special regex characters:
-
\w[a-zA-Z0-9_] Alphabets and Digits Class -
\W[^a-zA-Z0-9_] Negated Class of\w -
\d[0-9] Digits Class -
\D[^0-9] Negated Class of\d -
\tTab Character -
\nNewline Character -
\s[ \t\r\f\v\n] Matches all white space characters like space, tab, newline, carriage return, vertical tab, form feed, etc. -
\S[^\s] -
\bMatches Word Boundary where there is a\won one side and\Won other side of position
-
\B[^\b] Matches all non Word Boundaries
Wild 🐯 Cards
-
^symbol allows us to match the starting of the string -
$allows you to match the end of the string -
.allows us to match any character
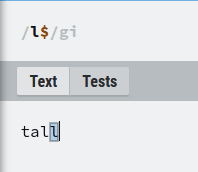
console.log("Tall".match(/l$/ig))
// [ 'l' ]
console.log("Tight".match(/^t/ig))
// [ 'T' ]
 |
 |
 |
|---|---|---|
In the above example, while l was matched only with the last one, whereas T was matched with the first one due to $ and ^, respectively. Without $ as you can see, all the ls were matched.
regex = re.compile("ho.dog")
print(regex.search("hotdog") is not None)
# True
print(regex.search("hoddog") is not None)
# True
. allowed us to match both d and t in the above example. All the three wildcards are special characters to match them specifically, i.e. ^, $ and . you have to escape them using \.
Flags 🎌
You might have observed usage of g or i after the regex expression so what are these things?
These are regex flags that affect the number and type of match we want to make :
-
i - Case insensitive match which doesn't differentiate
tandT - g - Global Flag allows us to match more than one instance of our expression and not just the first instance
-
m - Multiline Flag affects the behaviour of
^and$where a\nnewline character would mean the start of a new string
import re
print(re.search("^football","rugby\nfootball",re.I|re.M))
# <re.Match object; span=(6, 14), match='football'>
print(re.search("^football","rugby\nfootball",re.I))
# None
-
s - DotAll Mode, allows wildcard
.to match newline character as well. - u - Unicode support enabled
Half Way through, but I believe the next half will be easier

Quantifiers 3️⃣
Sometimes we require to match a character class, character, group ( coming up ) zero, one, more than one or even, let's say 11-22 times ( random numbers ); in such cases, quantifiers come to the rescue:
-
?Matches its preceding character, class or group zero or one time.
regex = re.compile("hot?dog")
print(regex.search("hotdog") is not None)
# True
print(regex.search("hodog") is not None)
# True
-
*Matches its preceding character, class or group zero or more times ( ∞ ).
regex = re.compile("hot*dog")
print(regex.search("hotttttdog") is not None)
# True
print(regex.search("hodog") is not None)
# True
print(regex.search("hotog") is not None)
# True
-
+Matches its preceding character, class or group one or more times ( ∞ ).
regex = re.compile("hot+dog")
print(regex.search("hotttttdog") is not None)
# True
print(regex.search("hodog") is not None)
# False
print(regex.search("hotog") is not None)
# True
-
{n,m}Matches its preceding character at leastntimes and at mostmtimes. The default value fornis0and the default formis∞
regex = re.compile("hot{1,3}dog")
print(regex.search("hotdog") is not None)
# True
print(regex.search("hottttdog") is not None)
# False
print(regex.search("hotttog") is not None)
# True
Groups ✨
Groups allow us to create grouped expressions that can help us in substitution, referencing them in later parts of a regular expression.
Let's say we want to replace all the function with arrow functions. Obviously, we would like to retain the name of the function and its arguments, but we need to reference them in replacement. With VSCode, our favourite editor and regex, we can do something like :
function NotAnArrow(argument) {
console.log("I do something")
}

const NotAnArrow = (argument) => {
console.log("I do something")
}
What we used were capturing groups, which we created using (.+) and (.*) ( arguments might not be there ). Anything inside those brackets forms our group, and the expression inside them is the one that will be matched.
There are other types of groups as well:
- Named Groups
(?<Name>...)is a group that provides us reference to that group using its name instead of numbers - Non Capturing Groups
(?:...)is a group that will match, but we can't reference them in the result of the regex expression.
Alternation |
Alternation is a simple OR that we can use between different parts of our regex pattern to match this or that or even that by providing different options, just like radio buttons.
const regex = /(java|type)(?:script)?|html5?|css3?|php|c(\+\+)?\s/gi
for (let x of `JavaScript is here but PhP came
before them and now its TypeScript`.matchAll(regex)) {
console.log(x)
}
// [ 'TypeScript', 'Type', index: 56, input: 'JavaScript is ..... ]
// .
// .
So here is what we did with that complex-looking but now easy for you to understand Regular Expression.
- Created Group to match both
Java,JavascriptandTypescriptusing|and? - Used
|to match other languages as well - Escaped
+to match forC++andCas well using? - Finally, a character class
\sto signify the end of the language name - Flags like
gito match all languages and irrespective of case
Usually, you will find yourself using
|inside of groups as you wouldn't want to pollute your global regex just like you always use virtual environment. Make sure to make themnon capturingif you don't want to reference or find them in your results.
Trick 🎃 Treat
+and*are of nature greedy. They will keep adding characters to the match until they find the last instance of any succeeding expression or the sentence ends.
import re
regex = re.compile("(a|m).+e")
print(regex.match("apple maple"))
# expected ['apple','maple'] found 'apple maple'
Here .+ ignored the e of apple and went all the way to finish at e of maple as it was the last instance of e that it was able to find.
Lazy Mode for * and + can be activated by appending ? after the quantifier matches only the minimum required characters for the regex expression.
const regex = /(?:a|m).+?e/gi
for (let x of "apple mapple".matchAll(regex)) {
console.log(x);
}
// expected ['apple','maple'] found ['apple' 'maple']
I highly recommend you to check language-specific docs for syntax and available features. One of the best docs for regex is for python.
I didn't cover one feature that I might make a new article on it is Lookahead and Lookbehind. You can wait :) or check out the link.

Why did I say that? Because sometimes regex can take exponential time to search a be really catastrophic. So .....
May the code be with you 🖖





Latest comments (0)