
Rate limiting refers to preventing the frequency of an operation from exceeding a defined limit. In large-scale systems, rate limiting is commonly used to protect underlying services and resources. Rate limiting is generally used as a defensive mechanism in distributed systems, so that shared resources can maintain availability. It also protects our APIs from unintended or malicious overuse by limiting the number of requests that can reach our API in a given period of time.
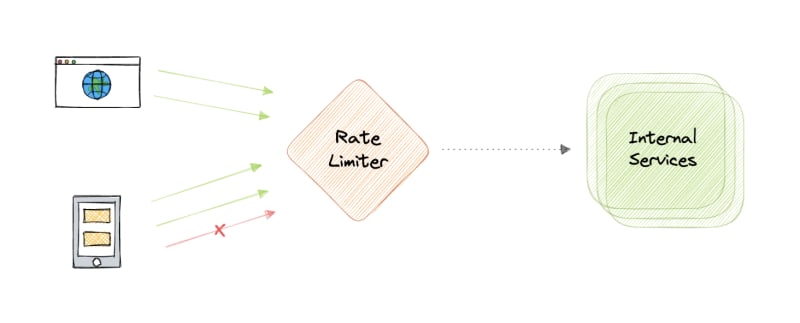
Why do we need Rate Limiting?
Rate limiting is a very important part of any large-scale system and it can be used to accomplish the following:
- Avoid resource starvation as a result of Denial of Service (DoS) attacks.
- Rate Limiting helps in controlling operational costs by putting a virtual cap on the auto-scaling of resources which if not monitored might lead to exponential bills.
- Rate limiting can be used as defense or mitigation against some common attacks.
- For APIs that process massive amounts of data, rate limiting can be used to control the flow of that data.
Algorithms
There are various algorithms for API rate limiting, each with its advantages and disadvantages. Let's briefly discuss some of these algorithms:
Leaky Bucket
Leaky Bucket is an algorithm that provides a simple, intuitive approach to rate limiting via a queue. When registering a request, the system appends it to the end of the queue. Processing for the first item on the queue occurs at a regular interval or first-in, first-out (FIFO). If the queue is full, then additional requests are discarded (or leaked).
Token Bucket
Here we use a concept of a bucket. When a request comes in, a token from the bucket must be taken and processed. The request will be refused if no token is available in the bucket, and the requester will have to try again later. As a result, the token bucket gets refreshed after a certain time period.
Fixed Window
The system uses a window size of n seconds to track the fixed window algorithm rate. Each incoming request increments the counter for the window. It discards the request if the counter exceeds a threshold.
Sliding Log
Sliding Log rate-limiting involves tracking a time-stamped log for each request. The system stores these logs in a time-sorted hash set or table. It also discards logs with timestamps beyond a threshold. When a new request comes in, we calculate the sum of logs to determine the request rate. If the request would exceed the threshold rate, then it is held.
Sliding Window
Sliding Window is a hybrid approach that combines the fixed window algorithm's low processing cost and the sliding log's improved boundary conditions. Like the fixed window algorithm, we track a counter for each fixed window. Next, we account for a weighted value of the previous window's request rate based on the current timestamp to smooth out bursts of traffic.
Rate Limiting in Distributed Systems
Rate Limiting becomes complicated when distributed systems are involved. The two broad problems that come with rate limiting in distributed systems are:
Inconsistencies
When using a cluster of multiple nodes, we might need to enforce a global rate limit policy. Because if each node were to track its rate limit, a consumer could exceed a global rate limit when sending requests to different nodes. The greater the number of nodes, the more likely the user will exceed the global limit.
The simplest way to solve this problem is to use sticky sessions in our load balancers so that each consumer gets sent to exactly one node but this causes a lack of fault tolerance and scaling problems. Another approach might be to use a centralized data store like Redis but this will increase latency and cause race conditions.
Race Conditions
This issue happens when we use a naive "get-then-set" approach, in which we retrieve the current rate limit counter, increment it, and then push it back to the datastore. This model's problem is that additional requests can come through in the time it takes to perform a full cycle of read-increment-store, each attempting to store the increment counter with an invalid (lower) counter value. This allows a consumer to send a very large number of requests to bypass the rate limiting controls.
One way to avoid this problem is to use some sort of distributed locking mechanism around the key, preventing any other processes from accessing or writing to the counter. Though the lock will become a significant bottleneck and will not scale well. A better approach might be to use a "set-then-get" approach, allowing us to quickly increment and check counter values without letting the atomic operations get in the way.
This article is part of my open source System Design Course available on Github.
 karanpratapsingh
/
system-design
karanpratapsingh
/
system-design
Learn how to design systems at scale and prepare for system design interviews
System Design
Hey, welcome to the course. I hope this course provides a great learning experience.
This course is also available on my website and as an ebook on leanpub. Please leave a ⭐ as motivation if this was helpful!
Table of contents
-
Getting Started
-
Chapter I
-
Chapter II
-
Chapter III
- N-tier architecture
- Message Brokers
- Message Queues
- Publish-Subscribe
- Enterprise Service Bus (ESB)
- Monoliths and Microservices
- Event-Driven Architecture (EDA)
- Event Sourcing
- Command and Query Responsibility Segregation (CQRS)
- API Gateway
- REST, GraphQL, gRPC
- Long polling, WebSockets, Server-Sent Events (SSE)
-
Chapter IV
- …





Oldest comments (0)