
Most, if not all, developers are at least somewhat familiar with the concept of caching. After all, this technology is so ubiquitous nowadays, from CPU to browser caching, that all software relies on caching techniques to a certain extent to provide rapid responses. A latency of just a few milliseconds can cause millions of loss in revenue, so a sub-millisecond response is becoming the norm. There is a vast number of caching solutions available in the market, thus making the process of choosing the right one an adventure on its own.
In this post, we will discuss what a cache is, and the benefits of caching. Next, we will discuss different caching strategies, and cache eviction policies. Finally, we are going to review some existing caching solutions available.
Caching Fundamentals
What is a cache?
In software development, a cache is a component that stores portions of a dataset that would either take too long to calculate or originates from another underlying system. By reducing unnecessary calculations and preventing additional request roundtrips for frequently used data, can increase the application performance, or decrease response latencies.
Caches are designed to respond to cache requests in near real-time and therefore are implemented as simple key-value stores. The inner workings, however, can still be very different and depend on backend storage.
Typical use cases are in-memory caches for databases or slowly retrievable disk-based data, data stored remotely behind slow network connections or results of previous calculations.
What are a cache hit and a cache miss?
A cache hit happens when the data requested is already available in the cache and can be returned without any other operation or processing.
A cache miss happens when the data requested is not already available and the data must be either retrieved from an underlying system or calculated before it can be returned.
Application Challenges and Caching Benefits
Modern systems have to accommodate large volumes of traffic and need to respond blazingly fast. Also as the volume of traffic and data increases the applications need to be able to grow to be successful. On the other hand, most infrastructure relies on disk-based databases, either directly or indirectly.
Disk-based databases can pose a lot of challenges for distributed applications that require low latency and scalability. A few of the most common challenges include:
- Slow processing queries: The data retrieval speed from a disk, plus the added query processing times, generally keeps response times relatively high. There are a lot of optimization techniques and designs that can boost query performance. However, there is a limit to the performance that we can achieve, before reaching the physical limitations of the medium. A large part of the latency of the database query is dictated by the physics of retrieving data from disk, after all.
- Cost of Scalability: Databases can be scaled either horizontally or vertically. Both of these scaling techniques do have their disadvantages. Vertical scaling is both expensive and you can reach the physical limit of components that can be added to a machine. Horizontal scaling allows sharding of the database to achieve higher throughput. Nonetheless, scaling for higher reads can be costly and may require a lot of replicas to achieve. Moreover, we must be very careful not to become imbalanced while trying to achieve higher response times.
- Availability: Sometimes, the connection to the database server or a database shard can be interrupted. Without a cache, the system will become unresponsive until the connection is restored.
The overall benefit of caching is to aid both the content consumer and content providers. A good caching strategy can offer several advantages.
- Improved responsiveness: Caches can provide faster retrieval of content and prevent additional network roundtrips. Caches maintained close to the user, like the browser cache, can make this retrieval nearly instantaneous.
- Increased performance on the same hardware: For the server where the content originated, aggressive caching can be squeezed from the same hardware. The content owner can leverage more powerful servers along the delivery path to take the brunt of content loading.
- Decreased network costs: Depending on the caching strategy, content can be available in multiple regions in the network path. That way, content can move closer to the user and network activity beyond the cache is reduced.
- Robustness of content delivery: With certain policies, caching can be used to serve content to end users even when it may be unavailable due to network shortages or server failures.
- Elimination of database hotspots: In many applications, a small subset of data will likely be accessed more frequently than the rest. This can result in hotspots in the database. The hotspots may require overprovisioning of database resources based on the throughput requirements for the most frequently used data. Storing common keys in an in-memory cache mitigates the need for overprovisioning while providing fast and predictable performance.
What to Cache
A good indicator of what to cache is to find any element where multiple executions of some request will result in the same outcome. This includes database queries, HTML fragments, or the output of heavy computations.
In general, only one rule applies. Data should not change too often but should be read very frequently.
What not to Cache
A common misconception, especially among tech adjacent roles, is that if you cache everything, you'll automatically benefit from it. What often looks like a good idea in the first place, causes another problem during high data peaks.
Volatile data is generally not very good for caching. Whenever data changes, the cache must be invalidated and, depending on the caching strategy we are using, this can be a costly operation.
Another type of data that is not benefited by caching, is data that is fast to retrieve. Caching those elements will introduce additional roundtrips while filling the cache, and inevitably increase the required memory. The benefit of caching these elements might event not show the expected results making them not worth the overhead.
Cache Types
In-memory Cache
An in-memory cache is a chunk of RAM that is used for the temporary storage of data. Since accessing RAM is significantly faster than accessing other media like hard disk drives or networks, caching helps applications run faster due to faster access to data.
Memory caching works by first setting aside a portion of RAM to be used as the cache. As an application tries to read data, typically from a data storage system like a database, it checks to see if the desired record already exists in the cache. If it does, then the application will read the data from the cache, thus eliminating the slower access to the database. If the desired record is not in the cache, then the application reads the record from the source. When it retrieves that data, it also writes the data to the cache so that when the application needs that same data in the future, it can quickly get it from the cache.
One broad use case for memory caching is to accelerate database applications, especially those that perform many database reads. By replacing a portion of database reads with reads from the cache, applications can remove latency that arises from frequent database roundtrips. This use case is typically found in environments where a high volume of data access is seen, like in a high-traffic website that features dynamic content from a database.
Another use case involves query acceleration, in which the results of a complex query to a database are stored in the cache. Complex queries running operations such as grouping and order can take a significant amount of time to complete. If queries are run repeatedly, as is the case in a business intelligence (BI) dashboard accessed by many users, storing results in a cache would enable greater responsiveness in those dashboards.
Distributed Cache
A distributed cache is a system that pools together the RAM of multiple networked computers into a single in-memory data store used as a cache to provide fast access to data.
While most caches exist traditionally in one physical component, be it a server or hardware component, a distributed cache can grow beyond the physical limitations of a single machine by linking multiple computers for larger capacity and processing power.

A distributed cache pools the RAM of multiple computers into a single in-memory data store used as a data cache to provide fast access to data.
Distributed caches are especially useful in environments with high data volume and load. The distributed architecture allows incremental scaling by adding more hardware to the cluster, allowing the cache to grow in step with the data growth.
There are several use cases for which an application may include a distributed cache as part of its architecture:
- Application acceleration: Most applications rely on disk-based databases, either directly or indirectly, and can't always meet today's increasingly demanding requirements. By caching the most frequently accessed data in a distributed cache, we can dramatically reduce the bottleneck of disk-based systems.
- Storing session data: A site may store user session data in a cache as inputs for a multitude of operations, such as shopping carts and recommendations. With a distributed cache, we can have a large number of concurrent web sessions that can be accessed by any server in the system. This allows us to load balance web traffic to several servers and not lose sessions should any application server fail.
- Extreme scaling: Some applications request significant volumes of data. By leveraging more resources across multiple machines, a distributed cache can answer those requests.
Caching Data Access Strategies
When we are caching data, we can choose from a variety of caching strategies that we can implement, including proactive and reactive approaches. The patterns we choose to implement should be directly related to our caching and application objectives.
Cache Aside (Lazy Loading)
Cache aside is perhaps the most commonly used caching approach. This strategy dictates that the cache must sit on the side and the application will directly talk to both the cache and the database.
In this strategy, when the application requires some data, it will first query the cache. If the cache contains the element, we have a cache hit and the cache will return the data to the application. If the data is not present in the cache we have a cache miss. The application will now have to do some extra work. The application will first have to query the database for the required data. Afterwards, it will return the data to the client and finally update the cache with the retrieved data. Now any subsequent reads for the same data will result in a cache hit.

Cache aside caches are usually general purpose and work best for read-heavy workloads.
Systems using cache aside are resilient to cache failures. If there are multiple cache nodes and a node fails, it will not cause a total cause of connectivity but the application might face increased latency. As new cache nodes come up online, and more requests are redirected to them, the node will be populated with the required data with every cache miss. In case of a total cache failure, the application can still access the data through database requests.
A disadvantage of this strategy is that three network round trips are required after a cache miss. First, the application will need to check the cache. Next, the application will need to retrieve the data from the database. Finally, the application will need to update the cache. These roundtrips can cause noticeable delays in the response.
Read Through
Compared to Cache Aside, Read Through moves the responsibility of getting the value from the datastore to the cache provider. This strategy dictates that the cache must sit between the application and the database.
In this strategy, when the application requires some data, it will query the cache. If the cache contains the element, we have a cache hit and the cache will return the data to the application. If the data is not present in the cache we have a cache miss. The cache will first have to query the database for the required data. Afterwards, the cache will update itself with the required data. Finally, the cache will return the retrieved data to the application. Now any subsequent reads for the same data will result in a cache hit.

Read Through caches are ideal to use in tandem with the Write Through strategy when we have data that is meant to be kept in the cache for frequent reads even though this data changes periodically.
This strategy is not intended to be used for all data access in an application. If the system uses the cache for all data access between the database and the application, a cache failure can cause a bottleneck in the application performance, or outright cause an application crash since the application cannot access the database.
Write Through
Similar to Read Through but for writes, Write Through moves the writing responsibility to the cache provider. This strategy dictates that the cache must sit between the application and the database. This strategy doesn't provide any functionality for reading data from the primary data source but handles what happens when new data or updates are issued by the application.
In this strategy, when the application tries to update existing data or add new data to the datastore, it will hit the cache. This operation always results in a cache hit, and the cache will either update its entries or create a new entry for the data. Then the cache will update the primary data storage. Finally, the cache will acknowledge that the data were successfully stored.
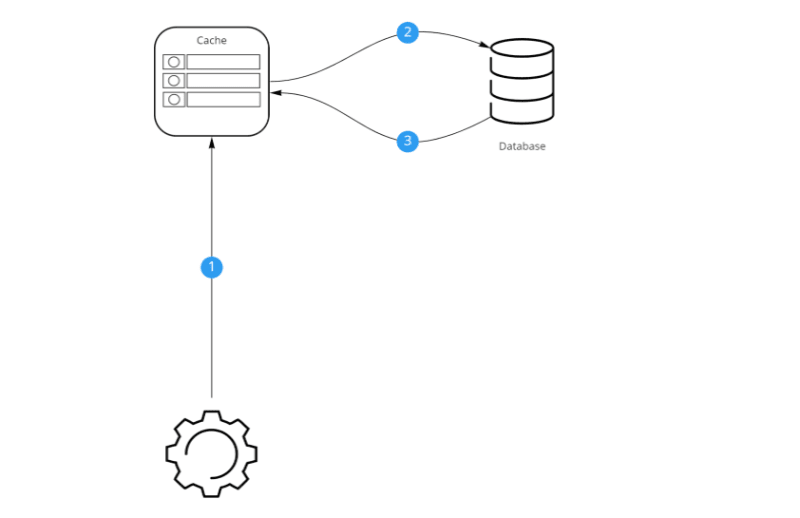
On its own, Write Through doesn't seem to do much, if fact, it introduces an extra write latency since data is written to the ache first and then to the database. But when this strategy is paired with a Read Through reading strategy, ensures data consistency.
As was the case with the Read Through strategy, This strategy is not intended to be used for all data access in an application. If the system uses the cache for all data access between the database and the application, a cache failure can cause a bottleneck in the application performance, or outright cause an application crash since the application cannot access the database.
Write Around
Write Around caches have similar functionality to Write Through caches. In Write Around caches the cache data will be updated only if it's already mapped into the cache, and simultaneously writes the data "through" to the backend storage.
In this strategy, when the application tries to add or update some data, it will query the cache. The cache will update the backend storage with the updated data. Then if the cache contains an entry for the updated data, it will update itself, otherwise, it will skip the data entirely.
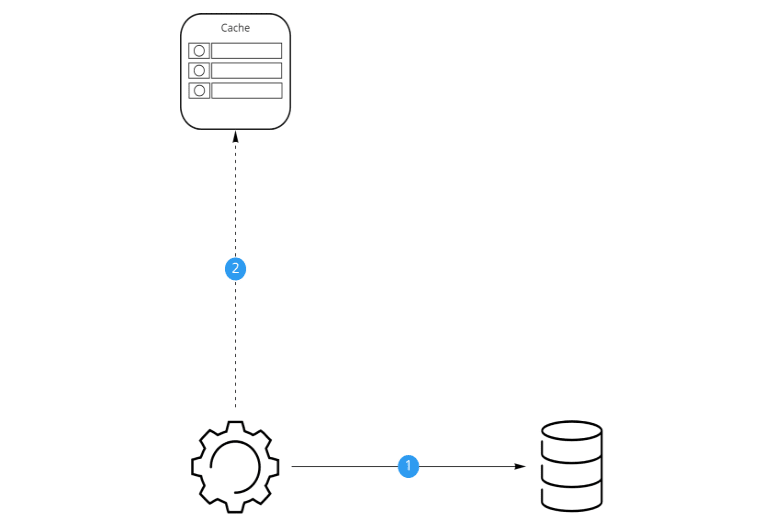
This strategy protects the cache from being flooded with data that are not so frequently read while introducing minimal latency for write operations. It also ensures data consistency between the cache and the main data storage. Because of this, it's very well suited for systems with a very high write volume of one-off data, such as messages from a chatting application.
The disadvantage of this strategy is that recently written data will always result in a cache miss (and so a higher latency) since data can only be found in the slower backend storage.
Write Back
Write Back works pretty similar to the Write Through strategy. The main difference is that the cache does not update the main data storage synchronously, but in batches after predefined time intervals.
In this strategy, when the application adds or updates the data, it communicates with the case. The case will send an acknowledgement to the application. After a defined time interval, the cache will perform a batch query on the data storage and update all relevant data.

Write Back caches improve the write performance and are ideal for both read-heavy and write-heavy workloads.
Since the application writes only to the caching service, it doesn't need to wait until the data are written to the underlying data source, thus improving performance. Also, because all reading and writing are performed on the cache, the application is insulated from database failures. If the database fails, queued items can still be accessed.
This strategy also introduces some problems that need to be addressed. Considering that this strategy reads and writes to the cache first, there is only eventual consistency between the cache and the main data storage. If the main data storage is shared with other applications there is always the danger that other applications will get stale data, if their read operations occur between batch actions. Also, there is no way of knowing whether cache updates will conflict with other external updates. This has to be handled manually or heuristically.
Eviction Policies
Eviction policies allow the cache to ensure that its size doesn't exceed the maximum limit. To achieve this, existing elements are removed from a cache depending on the eviction policy, but it can be customized as per application requirements.
A caching solution may be compatible with different eviction policies, but before choosing a caching strategy, it's good to have an idea of what eviction policies the application might need.
Least Recently Used (LRU)
One of the most used strategies is Least Recently Used. The Least Recently Used eviction policy removes values that were last used most far back in terms of time. To do the analysis, each record in the cache keeps track of its last access timestamp that can be compared to other records, to find the last least recently used item.
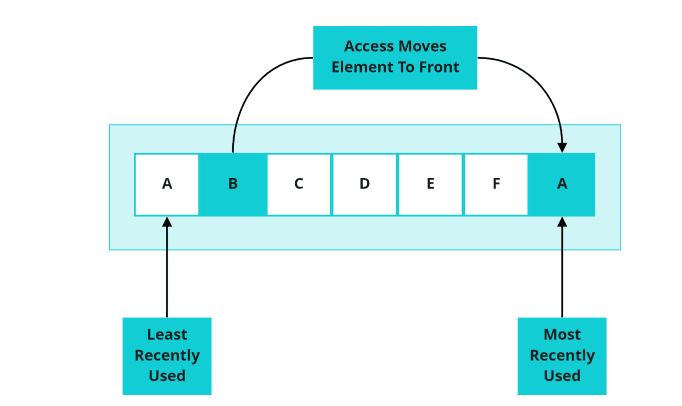
Least Frequently Used (LFU)
The Least Frequently Used eviction strategy removes values that are accessed the least amount of times. To do the analysis each record keeps track of its accesses using a counter which is increment only. This counter can then be compared to those of other records to find the least frequently used element.

Most Recently Used (MRU)
The Most Recently Used eviction policy removes values that were last used most recently in terms of time. To do the analysis, each record keeps track of its last access timestamp that can be compared to other records to find the most recently used element.
Most Frequently Used (MFU)
The Most Frequently Used eviction strategy removes values that are accessed the most amount of times. To do the analysis each record keeps track of its accesses using a counter which is increment only. This counter can then be compared to those records to find the most frequently used element.
Least Time To Live (LTTL)
The Least Time To Live eviction policy removes values that have the least amount of time in their TTL field. To do this analysis each record keeps track of its TTL which is assigned when it's added to the cache and decrements it at specific time intervals. The field can then be compared to those of other records to find the item that lived the longest in the cache.

Random
The Random eviction policy removes values randomly. This policy does not respect the insertion order of the items in the cache, or how frequently an item is accessed. This policy can be used when we have cyclic access and all elements are scanned continuously, or we expect the distribution to be uniform.
Real Life Caching Solutions
Memcached
Memcached is a general purpose distributed memory caching system. It is often used on dynamic database-driven websites to reduce the number of times an external data source must be read. Memcached is free and open-sourced, licensed under the Revised BSD license making it a very low-cost solution.
The system is designed as a simple key-value store. Memcached does not understand what the application is saving - it can store strings and objects as values, while the keys must always be stored as strings.
In a distributed setting, Memcached nodes don't interact with each other, because the system does not provide any synchronization or replication functionality. Thus the client has to decide which node has to access a particular dataset.
Notable Memcached Users include YouTube, Reddit, Twitter, and Wikipedia.
Limitations
Memcached does not provide any persistence for the cache entries, so with every crash or restart, the cache needs to warm up again.
Another limitation is the size limit of values. The values per key have to be up to 1 MB per key. This means that large objects or data sets may take more space and have to be fragmented in different cache slots. Moreover, objects must be serialized before being stored in the cache, increasing latency for reading/writing operations.
Redis
Redis (Remote Dictionary Server) is an in-memory data structure store, used as a distributed, in-memory key-value database, cache and message broker.
Redis supports several data structures, namely lists, sets, sorted sets, and strings natively. It also supports range queries, hyperloglogs, and geospatial indices.
Redis typically holds the whole dataset in memory but can be configured to persist its data through two different methods. The first method is through snapshotting, where the dataset is asynchronously transferred from memory to disk, at regular intervals, as a binary dump. The second method is journaling, where a record of each operation that modifies the dataset is added to an append-only file in a background process.
By default, Redis writes data to a file system at least every 2 seconds, with more or less robust options available if needed. In the case of a complete system failure on default settings, only a few seconds of data would be lost.
Redis also supports master-replica replication. Data from any Redis server can be replicated to any number of replicas. Redis also provides a publish-subscribe feature, so a client of a replica may subscribe to a channel and receive a full feed of messages published to the master.
Limitations
In a distributed environment, Redis shards data based on the hash slots assigned to each master. If any master goes down, data to be written on this slot will be lost. Moreover, failovers are not supported unless the master has at least one slave.
Since Redis stores the data in a large hash table in memory, it requires a large amount of RAM.
Aerospike
Aerospike is a flash memory and in-memory open-source distributed key-value NoSQL database management system. One of the most important selling points of Aerospike is that supports a hybrid memory model - this means that if RAM is maxed out, other suitable flash drives, (such as SSDs, NVMes, etc.) can be used as an alternative.
Aerospike uses flash drives to scale vertically. Generally, the IOPS (Input Output Per Second) keeps on increasing. SSDs can store orders of magnitude more data per node than DRAM and NVMe drives can now perform up to 100K IOPS per drive. Aerospike exploits these capabilities, it can perform millions of operations per second with a sub-millisecond latency all the time.
Hazelcast
Hazelcast is an open source in-memory data grid based on Java. In a Hazelcast grid, data is evenly distributed among the nodes of a cluster, allowing for horizontal scaling of processing and available storage. Backups are also distributed among nodes to protect against failure or any single node.
Hazelcast can run on-premise, in the cloud, and Docker containers. Hazelcast offers integration for multiple cloud configurations and deployment technologies, including Apache jclouds, Consul, Eureka, Kubernetes, and Zookeeper. Hazelcast can also enable cloud-based or on-premises nodes to auto-discover each other.
Final Thoughts
In this post, we have discussed what cache is and what are the benefits of caching. We also examined what are in-memory and distributed caches. We reviewed the most common caching strategies and we discussed what are the most popular eviction strategies. Finally, we reviewed some caching providers available to us.
It should now be a little more clear that choosing a caching service is not only a decision between big names or familiarity, but it's more of the application's use cases, data access patterns, infrastructure requirements, availability and volume of data among other things.
It’s up to the engineers how much consideration they want to have before they choose something — it’s normal behaviour that people choose a technology with which they are already familiar, but knowing all of these parameters for sure helps us make better design decisions.





Oldest comments (0)