
I will be mostly focusing on SQL databases, along with how to implement a database in AWS cloud.
The information in this blog contains,
- Page 1: What do you mean by database, database languages.
- Page 2: Entity Relation Diagram, Relational schema and converting ER into Relational.
- Page 3: Relational Algebra and Calculus :
- Page 4: Data base design, anomalies present, normalization forms and an example.
Q. What is data and a database?
Data is raw information. For example, your daily usage of mobile. It is raw information about the time you spent on you phone, but if you analyze it, how much time did you spend on an app per day, then it becomes information.
A database is a collection of related data which can be used:

Q. What is Database Management?
A DBMS is a collection of programs which,
- Provide management of databases
- Control access to data present in databases
- Contain a query language to retrieve information easily from a database
An example of database, where data is collected, maintained, and used would be the WordPress site database.
Two main uses of database are,
- Storing information
- Sorting information

Database System = Database + Database Management System
Schema of a database:
Schema describes the logical structure of the database, the overall of the database is also called the database schema.
A schema diagram, as shown below, displays only names of record types (entities) and names of data items (attributes) and does not show the relationships among the various files.

The schema will remain the same while the values filled into it change from instant to instant. When the schema framework is filled in with data item values, it is referred as an instance of the schema.
The data in the database at a particular moment of time is called a database state or snapshot, which is also called the current set of occurrences or instances in the database

Database Languages:
1.Data Definition Language(DDL):
- Mainly concerned with definition of data . It is a language that allows the users to define data and their relationship to other types of data.
- It is also used to specify the structure of each table, set of associated values with each attribute, integrity constraints, security and authorization information for each table. The following table gives an overview about usage of DDL statements in SQL

2.Data Manipulation Language(DML):
- Enables user to access or manipulate data
- Insertion of new information into the database
- Deletion of information from the database
- Modification of information stored in the database

3.Data Control Language(DCL):
- DCL statements control access to data and the database using statements such as GRANT and REVOKE.
- The privileges assigned can be SELECT, ALTER, DELETE, EXECUTE, INSERT, INDEX etc. In addition to granting of privileges, you can also revoke (taken back) it by using REVOKE command.
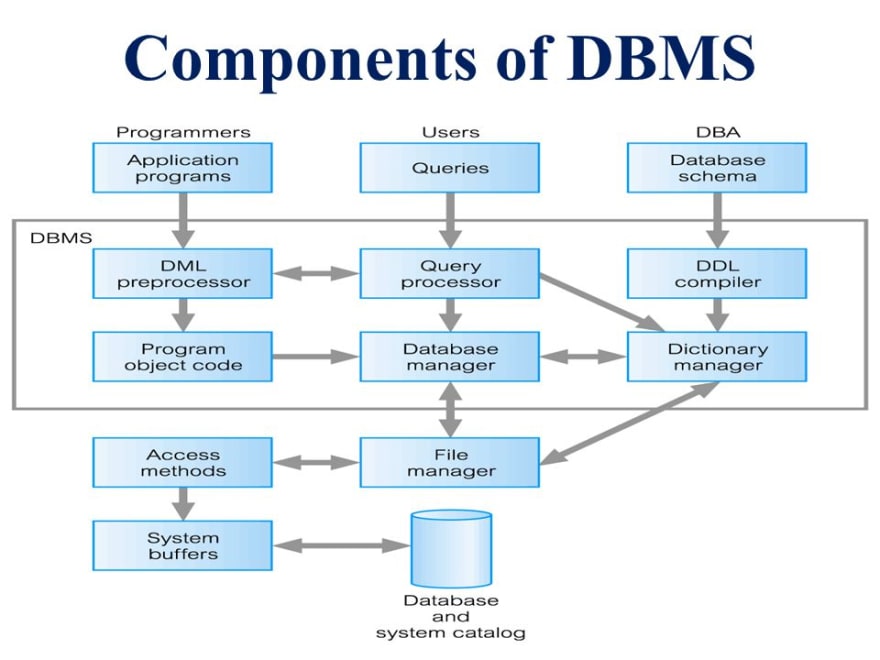
Data Models:
It is a collection of tools for describing data, data relationships, data semantics and data constraints.
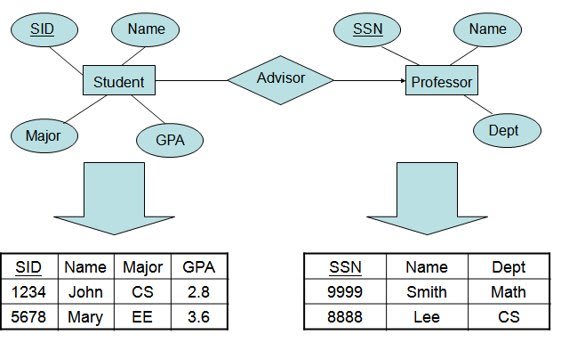
1.Entity- Relationship model:
An entity-relationship diagram (ERD) is a data modeling technique that graphically illustrates an information system’s entities and the relationships between those entities. An ERD is a conceptual and representational model of data used to represent the entity framework infrastructure.
In simple terms , E-R model is a conceptual level model. Entity-Relationship model is based on the notion of real world entities and relationship among them. ER Model is based on:
- Entities and their attributes
- Relationships among entities

1. Entity: An entity can be a person, place, object, event or concept in the user environment about which the organization wishes to maintain data.
Real-world object distinguishable from other objects.
2.Entity sets: A collection of similar entities.
- All entities in an entity set have the same set of attributes
- Each entity set has a key
- Each attribute has a domain
3.Weak entity: A weak entity is an entity that depends on the existence of another entity. In more technical terms it can defined as an entity that cannot be identified by its own attributes. It uses a foreign key combined with its attributed to form the primary key.
The order item will be meaningless without an order so it depends on the existence of order.

Difference between strong and weak entity.

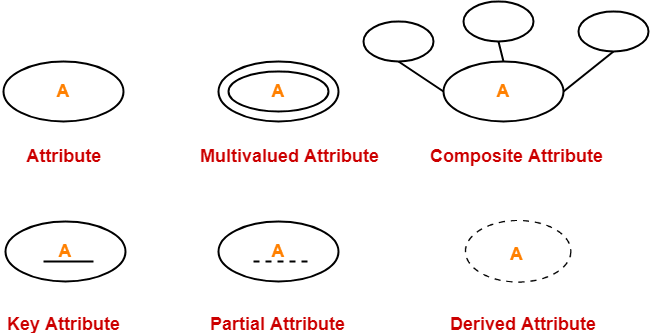
4.Attributes:
A named property or characteristic of an entity that is of interest to an organization, Different Attribute Types,
- Composite Vs. Simple Attributes: an example for composite would be Name= First name + last name. Where as in simple one, name would be equal to first name.
- Single-valued Vs. Multi-valued Attributes: an example for this would be an email id, if it is single valued then it can only store one email id per key, where as in multi valued it could store N number of email id per key,
- Derived attributes: an example for this would be storing date of birth, and calculating age from it.
- Key attributes :Covered below.
5.Relationships:
A relationship describes how entities interact. Degree of a relationship is the number of entity types that participate in it, Types of degree's of a relationship,
- Unary Relationship: One entity related to another of the same entity type
- Binary Relationship: Entities of two different types related to each other
- Ternary Relationship: Entities of three different types related to each other

1.Cardinalities of Relationships
I try to use a verb to connect two entities. For example,
- A student can attend many classes, one class can be attended by many students.
- A driver can own many cars, but a car cannot be owned by many drivers.
Types of relationships,
- One to One relationship: one element in set A to one element in set B
- One to Many relationship: one element in set A to many elements in set B
- Many to One relationship: many elements in set A to one element in set B
- Many to many relationship: many elements in set A to many elements in set B

2.Cardinality constraints
I try to use a use case to form a constraint between two entities. For example,
- A student must attend at least one class, one class can be attended by many students.
- A driver can own at a least car, but a car cannot be owned by many drivers.
Types of cardinality constraints,
- Mandatory one: At least one element
- Mandatory many: At least more than one
- Optional one: one or zero
- Optional many: zero or more than one

6.Identifier (Key):
A key is an attribute or a combination of attributes that is used to identify records.
Sometimes we might have to retrieve data from more than one table, in those cases we require to join tables with the help of keys. The purpose of the key is to bind data together across tables without repeating all of the data in every table.
1.Super Key: An attribute or a combination of attribute that is used to identify the records uniquely is known as Super Key. A table can have many Super Keys.
2.Candidate key: An attribute or a combination of attribute that identifies the record uniquely but none of its proper subsets can identify the records uniquely.
In order to be eligible for a candidate key it must pass certain criteria:
- It must contain unique values
- It must not contain null values
- It contains the minimum number of fields to ensure uniqueness
- It must uniquely identify each record in the table
3.Primary key: A Candidate Key that is used by the database designer for unique identification of each row in a table is known as Primary Key. A Primary Key can consist of one or more attributes of a table.
As with any candidate key the primary key must contain unique values, must never be null and uniquely identify each record in the table.
4. Foreign Key: A foreign key is an attribute or combination of attribute in one base table that points to the candidate key (generally it is the primary key) of another table.
The purpose of the foreign key is to ensure referential integrity of the data i.e. only values that are supposed to appear in the database are permitted.
5.Composite Key: If we use multiple attributes to create a Primary Key then that Primary Key is called Composite Key (also called a Compound Key or Concatenated Key).
6.Alternate Key: Alternate Key can be any of the Candidate Keys except for the Primary Key.
7.Secondary Key: The attributes that are not even the Super Key but can be still used for identification of records (not unique) are known as Secondary Key.

7.Integrity Constraints
Integrity constraints are a set of rules. It is used to maintain the quality of information.
Integrity constraints ensure that the data insertion, updating, and other processes have to be performed in such a way that data integrity is not affected. Thus, integrity constraint is used to guard against accidental damage to the database.
1.Entity Constraint:
- The entity integrity constraint states that primary key value can't be null.
- This is because the primary key value is used to identify individual rows in relation and if the primary key has a null value, then we can't identify those rows.

2.Domain Constraint:
- Domain constraints can be defined as the definition of a valid set of values for an attribute.
- The data type of domain includes string, character, integer, time, date, currency, etc. The value of the attribute must be available in the corresponding domain.

3.Check Constraint: A check constraint allows to state a minimum requirement for the value in a column.

4.Unique Constraint: The UNIQUE constraint ensures that all values in a column are different. Both the UNIQUE and PRIMARY KEY constraints provide a guarantee for uniqueness for a column or set of columns.

5.Referential Integrity:
- A referential integrity constraint is specified between two tables.
- In the Referential integrity constraints, if a foreign key in Table 1 refers to the Primary Key of Table 2, then every value of the Foreign Key in Table 1 must be null or be available in Table 2.

8.Key Constraints
1.Primary Key Constraint: Primary key is to uniquely identify each record in a table. It must have unique values and cannot contain nulls. Thus PRIMARY KEY = NOT NULL+ UNIQUE.
2.Foreign Key Constraint: Foreign keys are the fields of a table that point to the primary key of another table. They act as a cross-reference between tables. It has two types:
- Cascade Update
- Cascade Delete
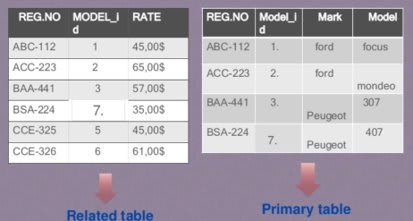
3.Default Constraint: The DEFAULT constraint is used to provide a default value for a column. The default value will be added to all new records IF no other value is specified.

2.Relational Model:
In this model ,data is organized in two dimensional tables called relations. Relational Model is made up of tables,
- A row of table = a relational instance/tuple
- A column of table = an attribute
- A table = a schema/relation
- Cardinality = number of rows
- Degree = number of columns

3.Conversion Rules to relational model
STEP 1: For each non-weak entity, create a relation (or table) that includes all of the simple attributes of that entity.
- Do not include multi valued attributes or derived attributes at this time. If you have a composite attribute, include only the component attributes.
- Choose one of the candidate keys to be the primary key of the table.
STEP 2: For each weak entity, create a relation that includes all simple attributes of the weak entity.
- In addition, include as a foreign key attribute the primary key of the owning entity.
- The primary key of this relation will be the combination of the primary key of the owning entity and the partial key of the weak entity.

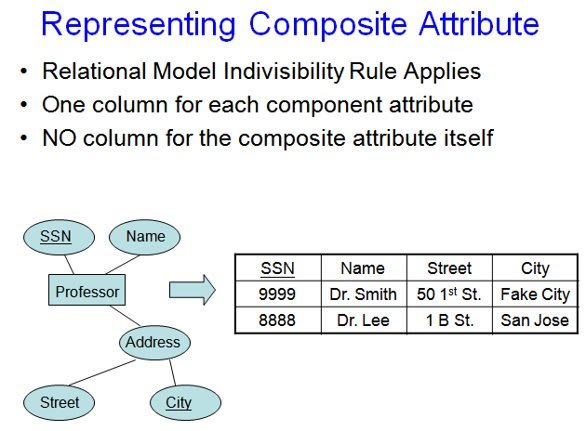
Step 3: For each multi valued attribute, create a new relation that includes that attribute, plus the primary key of the entity to whom that attribute belongs as a foreign key. The primary key of this new relation will be the combination of the foreign key and the attribute itself.

Step 4: Convert relationships into relational model,
1.Relationship Conversion: 1:1
For each binary 1:1 relationship, identify the two entities that participate in that relationship. Take the primary key from table and include it as a foreign key in the other table


2.Relationship Conversion: 1:N
For each 1:N relationship, the primary key of “1” side is added as a foreign key in the table on “N” side entity.
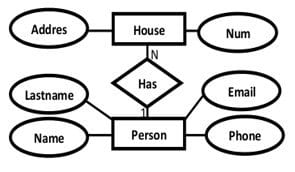

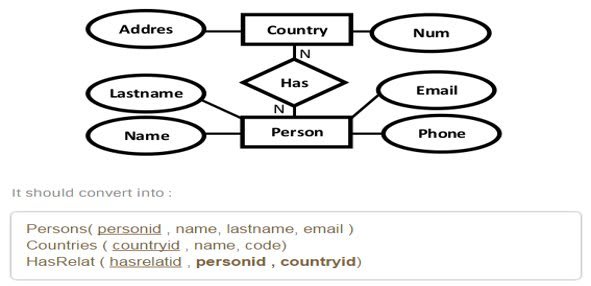
3.Relationship Conversion: M:N
For each binary M:N relationship, create a new relation to represent the relationship. Include in this relation as foreign keys the primary keys of each of the entities that participates in the relationship. The combination of these foreign keys will make up the primary key for the new table.
4.Conversion of N-ary relationship
For each n-ary relationship create a relation to represent it. Add a foreign key into each participating entity type. Also add any attributes of the relationship. The primary key of this relation is the combination of all foreign keys into participating entity

Step 5: Checking for sub classes and super classes
- Super-class: An entity type that includes one or more dissimilar sub-groupings of its occurrences that is required to be represented in a data model.
- Sub-class: A distinct sub-grouping of occurrences of an entity type that require being represented in a data model.
1. Generalization:
Generalization is the process of extracting common properties from a set of entities and creating a generalized entity from it. It is a bottom-up approach in which two or more entities can be generalized to a higher level entity if they have some attributes in common.

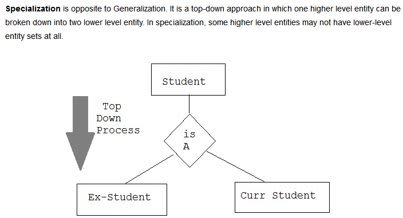
2.Specialization:
In specialization, an entity is divided into sub-entities based on their characteristics. It is a top-down approach where a higher level entity is specialized into two or more lower level entities.
3.Aggregation:
Sometimes you may want to model a 'has-a,' 'is-a' or 'is-part-of' relationship, in which one entity represents a larger entity (the 'whole') that will consist of smaller entities (the 'parts'). This special kind of relationship is termed as an aggregation. Aggregation does not change the meaning of navigation and routing across the relationship between the whole and its parts.

Q. How to confirm a database is Relational?
Codd's rules proposed by E. F. Codd, designed to define what is required from a database management system in order for it to be considered relational .
For a system to qualify as a relational database management system (RDBMS), that system must use its relational facilities to manage the database.
For more information on codd's twelve rules, refer this article by Joe Celko.
Relational Algebra and Calculus :
Query Languages are structured commands to insert and retrieve data from a database.

Relational Query Languages
- The Relational Algebra is an algebraic notation, where queries are expressed by applying specialized operators to the relations.
- The Relational Calculus which is a logical notation, where queries are expressed by formulating some logical restrictions that the tuples in the answer must satisfy.
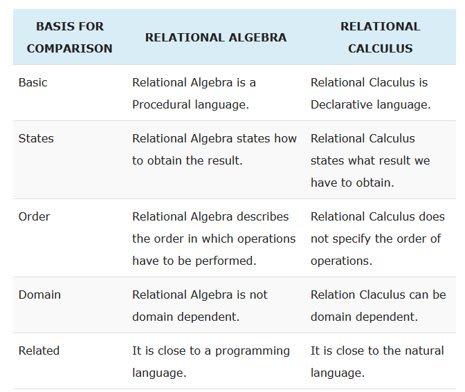
Relational Algebra:
- Relational algebra operations work on one or more relations to define another relation without changing the original relations.
- Both operands and results are relations, so output from one operation can become input to another operation.
There are six basic operations in relational algebra,
- Selection,
- Projection,
- Intersection
- Cartesian product
- Union
- Set Difference.
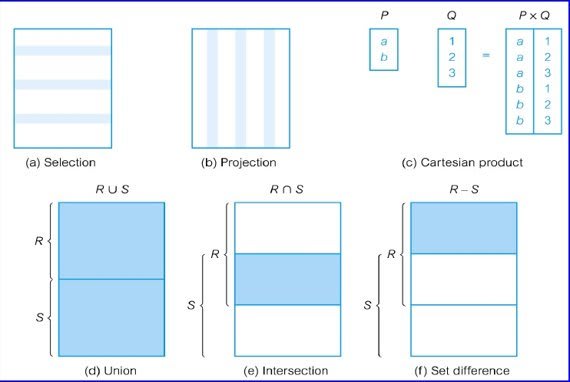
1.Selection:
Works on a single relation R and defines a relation that contains only those tuples (rows) of R that satisfy the specified condition (predicate).
In general the select operation is denoted as σ <selection condition>(R)
For example, List all staff with a salary greater than £10,000.
σsalary > 10000(Staff) 
2.Projection:
Works on a single relation R and defines a relation that contains a vertical subset of R, extracting the values of specified attributes and
eliminating duplicates.
The general form of the PROJECTION operation is Π<attribute list>(R)
For example, Produce a list of salaries for all staff, showing only staffNo, fName, lName, and salary details.
ΠstaffNo, fName, lName, salary (Staff)

We can use Selection as well as projection in one query statement,

3.Set Operations:
It takes an input of two relations instances, they require to input set to be compatible.
- They have the same number of fields
- Corresponding fields, taken in order from left to right have the same domains.
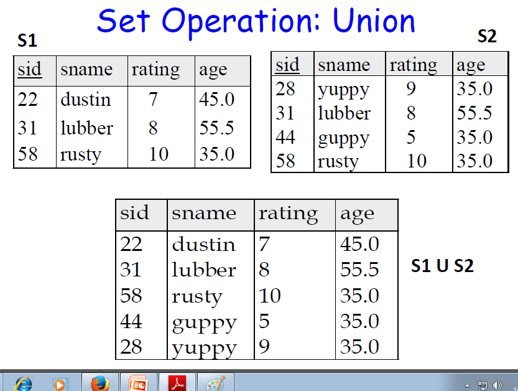
1.Union:
- Union of two relations R and S defines a relation that contains all the tuples of R, or S, or both R and S, duplicate tuples being eliminated.
- R and S must be union-compatible.
2.Intersection:
- Defines a relation consisting of the set of all tuples that are in both R and S.
- R and S must be union-compatible.

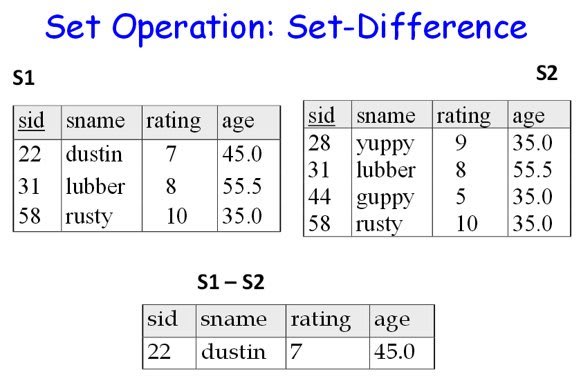
3.Set difference :
- Defines a relation consisting of the tuples that are in relation R, but not in S.
- R and S must be union-compatible.
4.Cartesian product: Defines a relation that is the concatenation of every tuple of relation R with every tuple of relation S.

4.Division:
Division is typically required when you want to find out entities that are interacting with all entities of a set of different type entities.
The division operator is used when we have to evaluate queries which contain the keyword ‘all’.
Division is not supported by SQL implementations. However, it can be represented using other operations.(like cross join, Except, In )
Given two relations(tables): R(x,y) , S(y).
R and S : tables
x and y : column of R
y : column of S
R(x,y) div S(y) means gives all distinct values of x from R that are associated with all values of y in S.

5.Join:
The join operation is used to combine related tuples from two relations into single tuples.
The general form of a join operation on two relations R(A1,A2,…An) and S(B1,B2,…Bm ) is R⋈<join condition>S
Some important points about joints:
- You can nest and chain joins to join more than two tables, but DBMS works its way through your query by executing joins on exactly two tables at a time.
- If a join's connecting columns contains nulls, the nulls never join.
- Joins exist only for the duration a query and aren't part of the database.

1.Cross Joins: Cross join is also referred to as Cartesian Product. For every row in the LEFT Table of the CROSS JOIN all the rows from the RIGHT table are returned and Vice-Versa.

2.Equi Joins:
- SQL EQUI JOIN performs a JOIN against equality or matching column(s) values of the associated tables. An equal sign (=) is used as comparison operator in the where clause to refer equality.
- You may also perform EQUI JOIN by using JOIN keyword followed by ON keyword and then specifying names of the columns along with their associated tables to check equality.

3.Natural Joins:
- It is a special case of an equijoin, it compares all the columns in one table with corresponding columns that have the same name in the other table for equality.
- Works only if the input tables have one or more pairs of meaningfully comparable, identically named columns
- Performs join implicitly, It can be replicated explicitly with an ON clause in JOIN syntax or a WHERE clause in WHERE syntax.

4.Inner Joins:
- It combines the rows retrieved from multiple tables on the basis of the common columns of the table or any conditions that tuples satisfy.
- In this kind of a JOIN, we get all records that match the condition in both the tables, and records in both the tables that do not match are not reported.
- INNER JOIN is based on the single fact that : ONLY the matching entries in BOTH the tables SHOULD be listed.
SELECT * FROM A INNER JOIN B USING (col1, col2,…)

5.Left joins:
Left Outer Join/Left Join returns all the rows from the LEFT table and the corresponding matching rows from the right table. If right table doesn’t have the matching record then for such records right table column will have NULL value in the result.

6.Right Outer Join:
Right Outer Join/Right Join returns all the rows from the RIGHT table and the corresponding matching rows from the left table. If left table doesn’t have the matching record then for such records left table column will have NULL value in the result.

7.FULL OUTER JOIN:
It returns all the rows from both the tables, if there is no matching row in either of the sides then it displays NULL values in the result for that table columns in such rows.
Full Outer Join = Left Outer Join + Right Outer Join

8.Self Joins:
If a Table is joined to itself using one of the join types explained above, then such a type of join is called SELF JOIN.

Now if we need to get the name of the Employee and his Manager name for each employee in the Employee Table. Then we have to Join Employee Table to itself as Employee and his Manager data is present in this table only as shown in the below query:

Relational Calculus:
- Relational calculus query specifies what is to be retrieved rather than how to retrieve it.
- No description of how to evaluate a query.
- Non procedural language.
- When applied to databases, relational calculus has forms : tuple and domain.

1.Tuple relational Calculus:
Tuple variable is a variable that ‘ranges over’ a named relation: i.e., variable whose only permitted values are tuples of the relation.
A simple tuple relational calculus query is of the form {t | COND(t)}
where t is a tuple variable and COND(t) is a conditional expression involving . The result is set of all tuples t that satisfy COND(t)
For example, To find details of all staff earning more than £10,000:
{S | Staff(S) AND S.salary > 10000}
2.Domain Relational Calculus:
Uses variables that take values from domains instead of tuples of relations.
If F(d1,d2, . . . ,dn) stands for a formula composed of atoms and d1,d2, . . . ,dn represent domain variables, then:
{d1,d2, . . . ,dn | F(d1,d2, . . . ,dn)} is a general domain relational calculus expression.
For example, Find the names of all managers who earn more than £25,000.
fN, lN | ( sN, posn, sex, DOB, sal, bN) (Staff (sN, fN, lN, posn, sex, DOB, sal, bN) AND posn = ‘Manager’AND sal > 25000)}
Database Development Life cycle

1.Requirement Analysis:
Requirements analysis is done in order to understand the problem, which is to be solved. There are two major activities in requirements analysis,
- Problem understanding or analysis
- Requirement specifications.
Goals of Requirements Analysis:
- To determine the data requirements of the database in terms of primitive objects.
- To classify and describe the information about these objects . .
- to identify and classify the relationships among the objects.
- To determine the types of transactions that will be executed on the database and the interactions between the data and the transactions.
- To identify rules governing the integrity of the data .
2.Database Design:
- In this phase, the information models that were developed during analysis are used to design a conceptual schema for the database and to design transaction and application.
- In conceptual schema design, the data requirements collected in Requirement Analysis phase are examined and a conceptual database schema is produced.
3.Database Design Framework:
- Determine the information requirements.
- Analyse the real-world objects that you want to model in the database.
- Determine primary key attributes.
- Develop a set of rules that govern how each table is accessed, populated and updated.
- Identify relationship between the entities.
- Plan database security.
4.DBMS Selection:
In this phase an appropriate DBMS is selected to support the information system.
A number of factors are involved in DBMS selection. They may be technical and economical factors. The technical factors are concerned with the suitability of the DBMS for information system. The following technical factors are considered.
- Type of DBMS such as relational, object-oriented etc
- Storage structure and access methods that the DBMS supports.
- User and programmer interfaces available.
- Type of query languages.
- Development tools etc.
5.Implementation :
- After the design phase and selecting a suitable DBMS, the database system is implemented.
- The purpose of this phase is to construct and install the information system according to the plan and design as described in previous phases.
- Implementation involves a series of steps leading to operational information system that includes creating database definitions, developing applications, testing the system, developing operational procedures and documentation, training the users and populating the database.
6.Design guidelines for Relational Schema:
- Meaning of the relation (Table) attributes, It should be easy to explain the meaning of entities and relationship between entities.
- Reducing repetitive values in the tuples, try to follow DRY concept
- Reducing the null values in the tuples: try to avoid, placing the attributes in a base relation whose value may usually be null.
- Not allowing the possibility of bogus tuples, When the tables are joined with equality conditions on attributes that are either primary key or foreign key.
7.Functional dependencies:
A functional dependency is an association between two attributes of the same relational database table. One of the attributes is called the determinant and the other attribute is called the determined.
If A is the determinant and B is the determined then we say that A functionally determines B and graphically represent this as A -> B.

Types of Functional Dependency:
1.Partial Dependency and Fully Functional Dependency:
1.Partial Dependency: If you have more than one attributes in primary key. Let A be the non prime key attribute. If A is not dependent upon all prime key attributes then partial dependency exists.
2.Fully functional dependency: Let A be the non-prime key attribute and value of A is dependent upon all prime key attributes. Then A is said to be fully functional dependent.
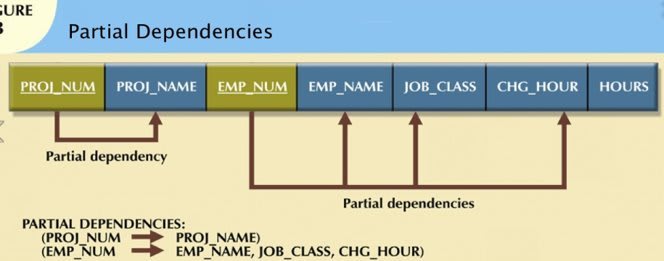
In the above example, Proj_NAME depends on Proj__NUM whereas EMP_NAME, JOB_CLASS and CHG_HOUR is depends on EMP_NUM.
A easy way to understand it would be if attribute Y is Partially dependent on the attribute X only it if it is dependent on a subset of attribute X.
2.Transitive and Non Transitive Dependency:
1.Transitive Dependency: It is due to dependency between non-prime key attributes. Suppose in a relation R, X-> Y (Y depends upon X ), Y->Z (Z depends upon Y) then X ->Z (depends upon X). There fore Z is said to be transitively dependent upon X.
2.Non Transitive dependency: There is no dependency between non-prime key attributes
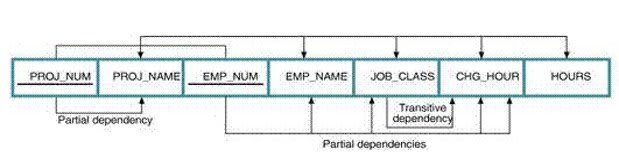
In the above example, CHG_HOUR depends on JOB_CLASS.
3. Single value and multi valued Dependency:
1.Single valued dependency: In any relation R, if for a particular value of X, Y has single value then it is know as single valued dependency.
2.Multi valued dependency(MVD): In any relation R, if or a particular value of X, Y has more than one value then it is know as multi valued dependency.
Denoted by x ->-> Y

Anomalies:
Database anomalies are the problems in relations that occur due to redundancy in the relations. These anomalies affect the process of inserting, deleting and modifying data in the relations. Some important data may be lost if a relation is updated that contains database anomalies.

Relations that have redundant data may have problems called update anomalies, which are classified as ,
1.Insertion Anomaly:
If you want to add new information in any relation but cannot enter that data because of some constraints. In Employee, you can't add new department Finance unless there is an employee in Finance department.
In addition to this information, it violates Entity integrity Rule 1.
2.Deletion Anomaly:
The deletion Anomaly occurs when you try to delete any existing information from any relation and this causes deletion of any other undesirable information.
In relation Employee, if you try to delete tupe containing Deepak this leads to the deletion of the department "Sales" completely.
3.Update Anomaly:
The update anomaly occurs when you try to update any existing information in any relation and this causes inconsistency of data.
For Example,


Decomposition:
To Avoid anomalies and preserve the dependencies in the database.
1.Lossless Decompostion:
An example of this will be rather than storing all information in a single table, store it in multiple tables.

After Breaking a single big table into smaller tables,

2.Dependency preserving :
If the original table is decomposed into multiple fragments, then somehow, we suppose to get all original FDs from these fragments. Every dependency in original table must be preserved or say, every dependency must be satisfied by at least one decomposed table.

Database normalization:

Database designed based on ER model may have some amount of inconsistency, ambiguity and redundancy. To resolve these issues some amount of refinement is required. This refinement process is called as Normalization. It has three goals:
- To eliminate redundant data (e.g. storing the same data in more than one table) a
- To store only related data in a same table.
- Organize data efficiently
- Both goals reduce the amount of space a database consumes, ensures data is logically stored, and maximize operational efficiency.
- A good database design includes the normalization, without normalization a database system may slow, inefficient and might not produce the expected result.

UNF to 1 NF:
First Normal Form is a relation in which the intersection of each row and column contains one and only one value.
There are two approaches to removing repeating groups from un-normalized tables:
- Removes the repeating groups by entering appropriate data in the empty columns of rows containing the repeating data.
- Removes the repeating group by placing the repeating data, along with a copy of the original key attribute(s), in a separate relation. A primary key is identified for the new relation.
The official qualifications for 1 NF are
- Each attribute name must be unique
- Each attribute values must be single
- Each row must be unique
- There is no repeating groups
For example,

1 NF relation with the first approach
Following the concept of atomic values

1 NF with the second approach
With the second approach, we remove the repeating group (property rented details) by placing the repeating data along with a copy of the original key attribute (clientNo) in a separte relation.

1 NF to 2 NF:
Second normal form (2NF) is a relation that is in first normal form and every non-primary-key attribute is fully functionally dependent on the primary key.
After removing the partial dependencies, the creation of the three new relations called Client, Rental, and PropertyOwner

2 NF to 3 NF:
A relation that is in first and second normal form, and in which no non-primary-key attribute is transitively dependent on the primary key.
The normalization of 2NF relations to 3NF involves the removal of transitive dependencies by placing the attribute(s) in a new relation along with a copy of the determinant.

3 NF to Boyle Codd Normal Form:
A relation is said to be in BCNF when:
- If every determinant is a condidate key
- It should be in 3 NF
A relation is in BCNF, if and only if, every determinant is a candidate key.

To transform the ClientInterview relation to BCNF, we must remove the violating functional dependency by creating two new relations called Interview and SatffRoom as shown below,

3 NF to 4 NF
A relation is said to be in 4 NF when:
- It is in BCNF
- There is no multivalued dependency in the relation. MVD occurs when two or more independent multi valued attributes are about the same attributes occur with same table.AS R->->B

After applying 4 NF form,

A summary would be

I worked on a Parcel Delivery System for my Junior year data base project, you can find it on GitHub.
I will be trying to write more on database in cloud, for more information about it.
- https://aws.amazon.com/products/databases/
- Amazon DynamoDB is very easy to understand and use.





Top comments (0)