URLs are one of the pillars of Web architecture, and a key concept for anyone who codes. This article discusses URLs, what they are, how they are used and how they are made.
What are URLs?
Uniform Resource Locators, better known as URLs, are simply addresses that point to unique resource. They are a type of URI, which stands for Uniform Resource Identifier.
Often called a web address in the context of HTTP, a URL is an address that points to resource, such as an HTML page or an image for example. URLs are used by browsers to load the associated resource.
Here is an example of a URL:
https://www.google.com
We can type this URL into the address bar of a browser, and the browser will retrieve the resource for us.
In this example, the resource is the Google homepage:

When we enter this URL into the address bar of a browser, an HTTP request is sent to a server that is managing the resource. In this case specifically, a GET request is to the server that is hosting the Google homepage.
We can see the network request made by the browser, by using the browsers built-in developer tools:
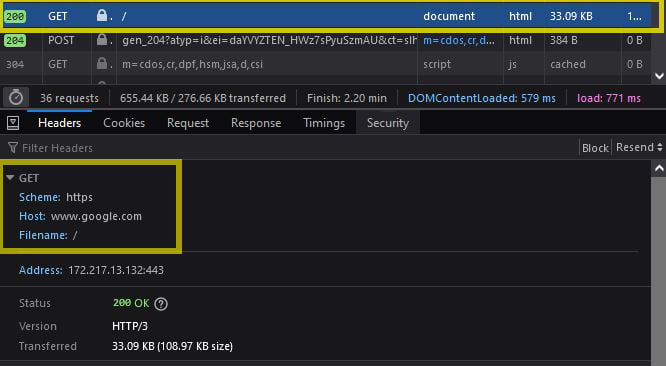
Notice the request information, it contains the follow:
- Scheme: The scheme used in the URL
- Host: The server
- Filename: The full path to the resource
Let’s have a closer look at these elements, and the structure of a URL.
Structure of a URL
Every URL consists of a number of different parts. Some of these parts are optional while others are mandatory. You will probably recognize many of these components.
Here is an example of a basic URL:

Let’s discuss the details further.
Scheme

The first part of a URL is the scheme. URL is used to ‘locate’ a resource, the scheme tells us ‘how’ we to access that resource. It indicates what protocol to use to access the resource.
Browsers are capable of accepting different schemes such as mailto:
Often the protocol is HTTP or HTTPS, when using a browser to access a web page. However there are many schemes available. Here are some examples of other schemes:
http:
mailto:
ftp:
telnet:
news:
tel:
Authority

After the scheme, is the authority component. It indicates what server manages the resource. It includes two elements,the host and the port.
The authority component is separated from the scheme by :// the colon indicates a different part of the URL, and the // means the authority will be next.
However, not all URLs use authority. It is important to understand the requirements of each protocol. Consider the following examples:
https://example.com/blog
mailto:example@example.com?subject=hello
news:<message-id>
Host
In the HTTP context, the host is often a qualified domain but it could also be an IPv4 or IPv6 address.

Port
This number indicates which port to connect to. The port is a communication endpoint. In an HTTP URL scheme, if the port number is omitted, then the port will default to port 80.
URL schemes usually define the port numbers for the protocol. When the port number is omitted, the colon separating them will be omitted too.
http://localhost:80
http://192.168.0.1:8000
Path
The URL path contains information about how to access the resource. It is the path to the resource. The path syntax depends on which URL scheme is being used.

In HTTP URLs, the / indicates a hierarchical structure – in the example above, archive is a child of blog. Note that the / separating the host and the path is not part of the path.
Parameters

Parameters are a list of key value pairs that are used by servers to perform some action before returning the resource. We can observe this by using the Google Search engine.
When you enter a term in the search bar, the term is then included as a URL parameter and processed by the server before returning the resource. We can confirm this by looking at the URL in the address bar:

HTTPS URL. The browser sends an HTTP GET request including the search term as a parameter.

Address bar. Notice the parameters, consisting of key/value pairs.
Every server will handle parameters differently, so it’s important to verify with the owner how they are specifically handled.
URLs in HTML
As previously mentioned, we can enter a URL directly into the address bar of a browser to access a resource. However, there are many technologies that use URLs, such as HTML, CSS and JavaScript. Let’s have a have a look at how URLs are used in HTML.
HTML extensively uses URLs to access documents and move from one to another. Whenever you click a hyperlink, and navigate to another HTML page, you are using a URL. A hyperlink is simply text that is tied to a URL.
Links to other documents are created in HTML, using the <a> element. This allows users to quickly access the desired document.
Here is an example of a link using the <a> element in HTML:
<a href="https://example.com">This is text that is tied to a URL</a>

Wrap Up
We have only scratched the surface of what URLs are and what they are used for. In future posts we will have a closer look at how we use URLs with JavaScript, including the URL web API.
Further reference
For those who are interested in further reading on the subject.
The post What you need to know about URLs appeared first on Jordan Holt.





Latest comments (0)