
Branchless programming is a programming technique that eliminates the branches (if, switch, and other conditional statements) from the program. Although this is not much relevant these days with extremely powerful systems and usage of interpreted languages( especially dynamic typed ones). These are very critical when writing high-performance, low latency software.
Modern compilers can identify and optimize your code to branchless machine code to some extent, but they can't detect all patterns.
In this article, I will be explaining in detail branching, why branching causes performance impacts, how to optimize your code to reduce this effect, some good implementations, and my thoughts on branchless coding
What is Branching?
Branching is when we split the flow of the program into two parts based on a runtime condition check. Consider the scenario of executing a simple if statement.
int main() {
int a = 5;
int b = 20;
if (a < b) {
a = 10;
}
return a;
}
In the above program the until the if statement is evaluated the program follows a single control path. After executing the condition "a<b" the program is divided into two branches based on the expression evaluation result.
The above translates to machine code as follows.
0000000000401110 <main>:
401110: 55 push %rbp
401111: 48 89 e5 mov %rsp,%rbp
401114: c7 45 fc 00 00 00 00 movl $0x0,-0x4(%rbp)
40111b: c7 45 f8 05 00 00 00 movl $0x5,-0x8(%rbp)
401122: c7 45 f4 14 00 00 00 movl $0x14,-0xc(%rbp)
401129: 8b 45 f8 mov -0x8(%rbp),%eax
40112c: 3b 45 f4 cmp -0xc(%rbp),%eax
40112f: 0f 8d 07 00 00 00 jge 40113c <main+0x2c>
401135: c7 45 f8 0a 00 00 00 movl $0xa,-0x8(%rbp)
40113c: 8b 45 f8 mov -0x8(%rbp),%eax
40113f: 5d pop %rbp
401140: c3 retq
401141: 66 2e 0f 1f 84 00 00 nopw %cs:0x0(%rax,%rax,1)
401148: 00 00 00
40114b: 0f 1f 44 00 00 nopl 0x0(%rax,%rax,1)
Note: The above output is without applying any optimizations by the compiler. Most compilers have really good optimizers which generate better code than this in most cases depending upon the target ISA, your compiler, the level of optimization, etc.
Yes it works..! What is wrong with it?
The above code will work fine. But the addition of a simple if statement added a conditional jump to the machine code. As we argue this is normal behavior and a language cannot be called a programming language without conditionals which makes it Turing complete.
Instruction Pipelining
CPUs use a technique called Instruction Pipelining. This is a way to implement instruction-level parallelism on a single processor. The CPUs will fetch the upcoming instructions from the memory when executing the current one. This will speeds up the processor as all stages of the CPU are always functioning regardless of the stage of the current instruction.
Executing an instruction consists of 4 stages.
- Fetch: Fetches the next instruction needs to be excited from the memory (usually available in processor cache itself.)
- Decode: After the fetch stage is completed, the instruction will be decoded
- Execute: The decoder will identify the instruction and issues control signals to execute the instruction
- Write Back: After execution, the results will be written back
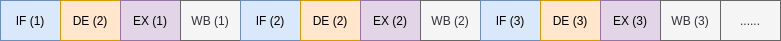
This is the normal way it is expected to work. The issue with this is when fetching the instruction the Decode, Execute and Writeback stages are idle. In order to solve this instruction pipelining was introduced which parallelizes the operation such that all stages are operational at the same time.

Instruction pipelining and branching
When the CPU decodes a branch instruction it has to flush the stages and restart the pipeline. After executing a branch instruction the instruction pointer changes which makes the subsequent instructions that are already fetched invalid.

As you can see in the above figure the instruction is invalidated and restated and the pipeline is restarted. In some cases, the new location may not be available in the CPU cache. in the case of a cache miss, the new block needs to be moved from memory to the CPU cache. This adds latency to the processing. Modern CPUs use some branch prediction techniques to deal with these scenarios, but still not that efficient (Spectre vulnerability, which once shook the internet came from this part.).
Apart from instruction pipelining, this has effects on modern CPU capabilities like Out of Order Execution (OOE), vector processing, etc.
How to optimize?
This is really a tough question. Conditionals are the inevitable part of a program. Not every scenario can be optimized. A very few conditionals can be replaced with some better patterns. In some cases replacing branches will degrade the performance as it might introduce more additional instructions. Modern compiles recognize some patterns and optimize them with branchless code.
Not all use cases have a branchless counterpart, but some can be replaced with a branchless alternative.
Utilizing booleans in Mathematical formulas
eg. 1) Maximum of 2 numbers
if(a > b) {
return a;
} else {
return b;
}
The above code snippet can be written as
return (a > b) * a + (a <= b) * b;
This can be further optimized by using a sign mask method.
int fast_max(int a, int b) {
int diff = a - b;
int dsgn = diff >> 31;
return a - (diff & dsgn);
}
eg. 2) Conditional assignments
x = ( a > b ) ? C : D;
x = (a > b) * C + (a <= b) * D;
eg. 3) Accessing array element
int x[] = [3,4,5,6,7,8];
int lenX = 6;
inline int getItemAtPosition(int i){
if(i>=lenX)
return x[i-lenX];
return x[i];
}
This is a common scenario. This can be optimized as
inline int getItemAtPosition(int i){
return x[i % lenX];
}
Bit level operations
eg. 1) Absolute Value
inline long abs(int a ){
if(a>=0)
return a;
else
return -a;
}
This can be optimized to.
inline long abs(int a) {
int mask = a >> 31;
a ^= mask;
a -= mask;
return a;
}
In some cases, shift operations can be tricky. Different CPU architectures implement shift operations in different ways. In some cases, the shift operation causes more cycle time.
Is it real? Does it really matter?
If you are writing code using some interpreted, dynamically typed languages it doesn't matter much because there are so many conditionals getting executed even for a simple statement you write(like checks for handling the type system, storage flags, etc). So this doesn't really add a performance boost to it. If you are writing low latency high-performance software, this can be helpful. This can give you a noticeable performance improvement especially if you use conditionals iteratively.
Modern compilers have built-in optimizers which can recognize some patterns and replace them with branch-less counterparts. But these are limited, so it's always better to write optimized code.
All the above snippets do not give you the best results in all the cases. Some CPU architectures have special instructions for handling these things.
Cover image by Photo by Jeremy Waterhouse from Pexels





Top comments (4)
Good article! I like the explanations of why branchless execution matters, and the mention of branch prediction leading to vulnerabilities such as Spectre, however you make a very bold statement :-)
I would be delighted to see evidence of this from performance testing, as my reading in this space tends towards leaving low-level optimisation to the compiler/CPU and concentrating on structural things (such as hoisting complex method calls out of loops)?
Hello
The assembly you show is for -O0. If you compile with -O1 instead, you will get:
We NEVER want to analyze code compiled with -O0 when it comes to optimization. Why? Because it doesn't make any sense.
Looking at the various implementations, version 1 works very well : see godbolt.org/z/sj6xzM
Much better than the ugly version 2.
I am not familiar enough with the cost of each opcode to say whether version 3 is faster than version 1.
This time, the so-called "optimized version" is clearly less optimized! See godbolt.org/z/h3dhT7
The modulo operator calls
__aeabi_idivmodand we all know that division cost at a lot!We can also see that there is no conditional in the first version...
See godbolt.org/z/d13jco
Again, there no conditional in the first version. The second version doesn't seems to be faster, but clearly the source code is less readable.
This leads me to your conclusion:
This was true 10 or 15 years ago.
I believe this is wrong today.
Modern compilers will optimize code much better than you. People are spending their life (often because it's their job) to write optimizers. They know many more tricks than you.
You have to understand how optimizers in compilers work: they look for a common patterns. When they found one, they optimize your code. Take the max function for instance: the "normal" version will be recognized for sure and optimized aggressively. With the other versions, compilers don't recognized anything. You try to be smart but at the end you fail because you don't let the compiler do its job properly.
Doesn't this mean we should not care when we write code?
Absolutely no.
But we have to understand where we can be smart and where the compiler will be smarter.
We should write clear code, compiler-friendly code. We should choose the correct containers (eg: linked list vs array list). We should find good architecture. We should choose the right algorithm (eg: not all sorting algorithm are the same).
Then we let the compiler works.
If performances are not good, then we use a profiler to see where we must optimize. We never optimize ahead with code that pretends to be "smart". We must understand why a particular piece of code, identified by the profiler, is slow. We optimize this piece only. We profile again.
Remember: premature optimization is the root of all evil.
I have tried to change the compiler to "x86-64 clang (trunk)" as the results are quite different for some snippets.
This confirms something important: don't assume, measure, try, measure again.
Example 3 is not correct. The modulo operator is not branchless. The only way to make this branchless is to have the second argument be a power of 2 (in this case, modulos can be calculated by bit-shifting). Instead, do something like:
return x[i - (i >= lenX) * lenX]Of course, we are assuming i is less than lenX
Some comments have been hidden by the post's author - find out more