One day, my colleague Lihau talked about AST, and shared something relates again in the following week - write babel plugin. This brought me back to my long living but no progress idea - let program to handle some boring coding job for me.
Well, people always like to talk about ideas, I do too. And the idea can be large, even infinity like the universe. We call it the big picture.
So here is my "big picture"🙈.
To split the code, ECMA and CommonJS that we commonly use these days, provide abilities to “import” and “export” some logics through ”declarations” like variables, functions and classes. However, though this ”import” and ”export” design make files smaller, more readable, they are not the final cure of decreasing the file size for client to load on-demand, and created a side product - complicated relationships between not only declarations, but also files.
When QA ask me what does your change affects in a big scale app, I could not answer him/her without searching through the whole repository, look into some files, and sometimes have to repeat this searching process over and over again. And human can always miss something, you know.
Micro front-end could be the cure, or maybe not, who knows? This is a boring and time wasting job for a programmer! So why not program it and just enjoy programming!
The information of ”import”, ”export” and the relationships of the ”declarations”, and files can help me out on this. Think about it, each single file knows who it depends on, which is stated by the ”import”. If I turn this over, it becomes: whose change will affect this file.
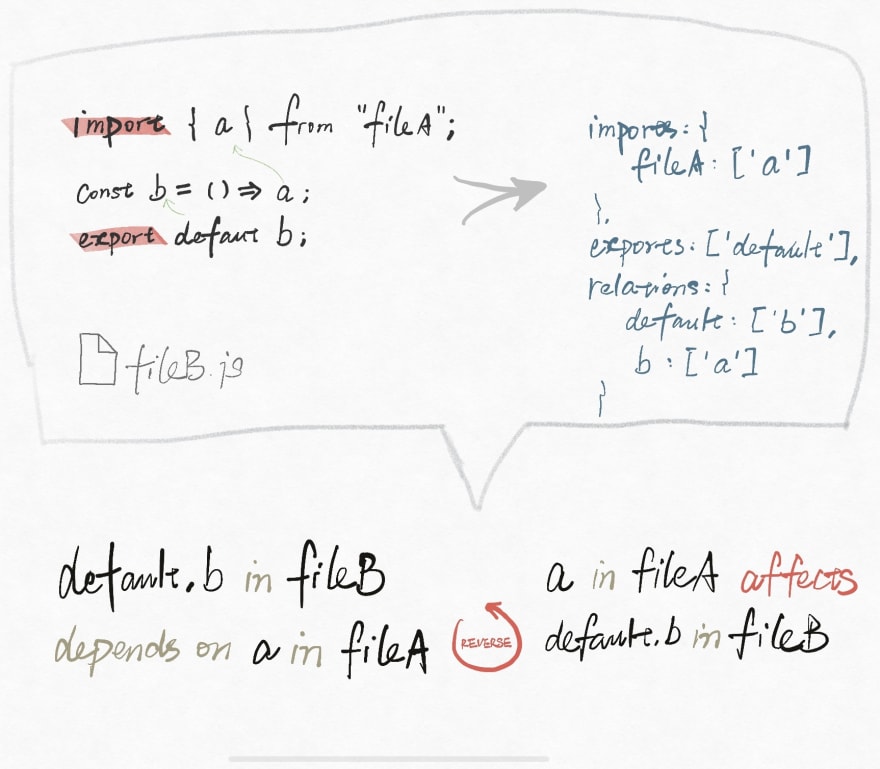
Then going through all the code, I can get the whole picture (wow, my code is so messy :p) - a map reflects the dependencies and change influences.
Reading the single node of this map, I get the information of potential problem could be caused by changing a file carelessly.
And here, I could find another possible result - what file or declarations have been rotten in the corner from thousand years ago and my genius programmers just busy on creating new ones not borthering even rm -f on it.
ESlint and other popular linting tools could help a lot on the unused private piece of code, but not on exported ones. Webpack has some awesome plugins could remove them, but only limits to the files on it’s entry files’ dependency chain. This can be rare and useless though 🤪.
Then how about this? In the current framework world, like React, we do split a page into multiple components, and basically based on the component name, we are likely to have the ability to know what this component is doing.
Other than the front-end developer of this project, people may not understand what does the name of a ”declaration” mean. But surely a page name or a component name means something. If I filter this map a little bit, keep only the components affected by my changes, and simply copy paste or make a bot to auto-reply to questions like “what does your change affected”! What a peaceful world it could be 😌.
Don’t stop creativity here. I could do a little bit more to make the world from harmony to even better probably - by adding a well designed test case database.
UX and integration tests are usually binded to those components, the elements they contains, and based on their reactions to the mouse, touch, keyboard or whatever events. So does the product specifications. And usually QA test cases are more detailed than your specifications.

If everytime QA or PM modify this database with versioning, could it be a perfect specification doc for reference? And possible to filter the part we need by components, page and versions? Or use Puppyteer to took some screenshots, and make it nicer to show the complete UI flow that I could easily make new joiners understood the app without bother me again?
Now back to the declaration and file map I find affected by my changes. Can I use it to ask my database generate the test cases list for regression? Yes, just name and structure of the components could change very often. It will need a responder to be notified of the changes, and properly update the database to keep it working.
Don't get upset yet. How about other tedious work like renaming functions? As the program got the information of the relationships talked above, it may help to avoid name duplication comparing to simple replacing.
And help re-organizing code by spliting one large file (like underscore) into multiple small files according to what declarations are commonly used together in other files, and what are not? Or vise versa.
With help of the above ability, it may also help to restructure your project to properly organized mono-repo by a command line, and modify all the tool configurations according to what each package contains.
And... wait, ideas are cheap, I cannot just keep talking, nothing will happen. So I created a repo here to try out these ideas: https://github.com/JennieJi/ast-lab. Hope it could be useful to you :).





Top comments (0)