
What is Recursion?
What is Recursion?
What is Recursion?
Recursion in programming, as you may have heard, refers to a function calling itself. A simple example is shown below:
It can be thought of as continuously repeating same thing and at each point, either stop and return to the previous step because you have satisfied some condition or keep repeating using the result of the previous action. You start off something and you keep doing it unless you satisfy a particular condition, which is known as the base case.
Let’s say, for example, sweeping. Sweeping involves swiping the broom across the floor continuously until you’ve reached the door or a designated point you’ve chosen to stop. You’ll see that, for every next sweep you want to make, you make it considering the result of the previous sweep. You may keep changing direction or stop sweeping. That is how recursion works.
For a function to be recursive, it must have two parts: the base case and the recursive call.
The base case ensures that the function does not keep running infinitely. It tells the function when to stop. In the above code, line two if (i < 0) return; is our base case. In the sweeping action, the base case would be if we reach the door.
The recursive call, contains a call to the function itself. - in the above code, hello(--i);
If you’ve been following, you’d realize that this is just like the iterative statements we know. The above code could be re-written as:
While the two are very similar, and can be used in place of the other in most cases, there are some fundamental differences.
Basic differences between Recursion and Iteration
First; recursion takes up more space in memory during execution. When the function is invoked, the function’s call address is placed at the base of the stack. The address of its recursive calls are placed on top of the call stack. The call stack holds the address of the function to be executed in the order, “Last In, First Out”.
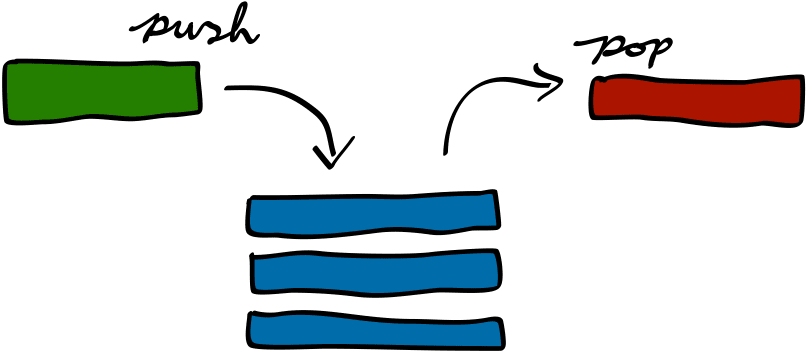
These addresses are popped out once the base case is reached and the function call is returned. Since these recursive calls are stored in the call stack, it take up more memory. It thus takes an extra O(D) space-complexity where D is the number of recursive calls.
Iteration involves repeatedly executing a set of statements. It stores the addresses of the parameters it needs and refers to them during execution. It does not need to create a new call stack or store new variables for each execution like recursion.
And hence recursion is slower in execution because of the function call overheads (which include setting up the call stacks, storing variables and address to be return to. Though this can be improved by tail-call optimization which doesn’t create new stack.
Why and when should I use recursion or iteration?
So you might be wondering, why should I use recursion when it’s more costly in some cases? My answer to that is, Recursion shouldn’t generally be your first approach if you need to do something repeatedly. If you can do it with iteration simply, then go on ahead.
However, you can use recursion when your data needs to be broken down into smaller, repetitive instances. And when you need to, ‘divide and conquer’ your problems. Like sorting an array, dealing with graph and tree data structures (like a file directory). Just use it, when it feels natural and you aren’t worried about space or when you can’t seem to find a simple iterative solution to your problem. I’ve not seen any case where recursion was chosen over iteration in web development.
More Code Examples
Some examples of recursive functions are:
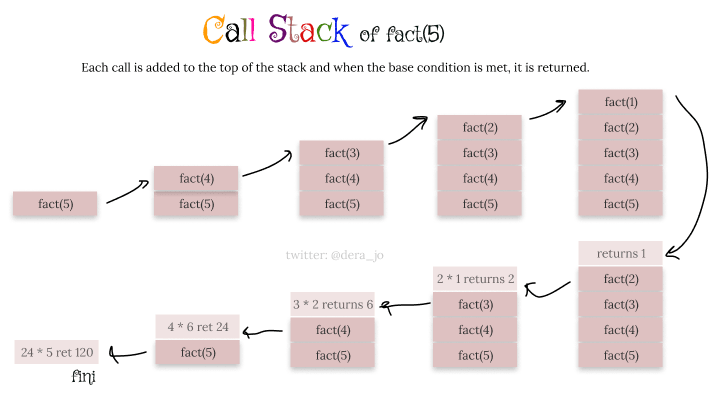
- Factorial problem: Find the factorial of a given integer. For e.g, 5! = 5 * 4 * 3 * 2 * 1
- Our hello example: Here, we will compare two versions of the example.
Each recursive call returns to the address of the function that called it and finishes up execution.
So the recursive calls, when it reaches the base case, returns each of the functions to the function that called it and that function then, continues execution using the returned variables and the variables stored at that execution context.
I hope that helped you understand recursion more! Feel free to leave your comments or follow me on Twitter @dera_jo





Oldest comments (3)
The first two code examples are not identical in function, as you can see from the output. So the first script cannot be 're-written' to the second code.
Yes, however, it‘s just a small problem: Simply use „>=“ instead of „>“ in the loop or a do-while-loop.
Some comments may only be visible to logged-in visitors. Sign in to view all comments.