
Remember how in the movie Moneyball (2011), Okland A's General Manager Billy Beane hires Economist Peter Brand to use data to change how the game's played? (Seriously though, if you haven't actually watched it, I strongly suggest you do so and come back!) Well, we're about to do the same thing - although operating in the realm of cricket this time.
What we're about to do is called an Exploratory Data Analysis - EDA for short - a process of analysing datasets to summarise their main characteristics. To do this, we will be using this IPL Dataset. First off, let's see what we have shall we?
import pandas as pd
import numpy as np
df=pd.read_csv("matches.csv")
df.head()

Okay, that's a lot of information! Let's break it down using the Pandas Dataframe info() method :
df.info()

As General Manager of the RCB, your job is to extract as much information you can from the data available. And that involves asking the right questions. Looking closely at our dataset, how much of the data is actually useful? Certainly not the umpires. Let's drop 'em out shall we?
df.drop(["umpire1", "umpire2", "umpire3"], inplace=True, axis=1)
df.head()

Now that is something we can work with! The thing about being the GM (and Data Science in general) however, is that no-one tells you what questions you need to ask. And asking the right questions can often to be tougher than answering them. Here's a list of five questions that I think this dataset may be able to answer :
- Is it more advantageous to bat or field first in a given venue?
- Which venue is each team most strongest at?
- Does the chasing team really have the edge in a match affected by rain?
- How crucial is winning the toss at a given venue?
- How is our track record versus different teams?
Now then, let's explore our data on a question-by-question basis! (although not necessarily in that exact order 👻)
Q1) How crucial is winning the toss at a given venue?
The cool thing about Pandas is how you can chain together logic to get your desired output in a less verbose way than say SQL. Our dataset gives us the winner of each match. We also know who won the toss at every match. Putting 2 and 2 together, these two things must be equal if the team that won the toss won the match as well. Finally, we need this data on a by-venue basis. Another point is that a percentage would be more useful to us than a raw number.
df[df["toss_winner"]==df["winner"]].value_counts("venue")/df.value_counts("venue")*100

See how easy that was? Note that we used the value_counts() method to group our data after filtration, and then divided it by the total matches played in that venue. This is another intuitive feature of Panads - in that it can detect similar data objects using indices.
We see that certain venues give a 100 percent dependancy on the toss. However, if we look at how many matches were played in these venues, we have a much clearer picture. The more matches played, the closer that number aproaches 50.
Q2) Is it more advantageous to bat or field first in a given venue?
Now, the process of answering this question follows the same intuition as the first. Although this time, we have to perform a few tweaks to obtain the data in the format we want.
fielding_wins=df[((df["toss_winner"]==df["winner"]) & (df["toss_decision"]=="field")) | ((df["toss_winner"]!=df["winner"]) & (df["toss_decision"]=="bat"))].value_counts("venue")
fielding_wins.sort_index(inplace=True)
batting_wins=df[((df["toss_winner"]==df["winner"]) & (df["toss_decision"]=="bat")) | ((df["toss_winner"]!=df["winner"]) & (df["toss_decision"]=="field"))].value_counts("venue")
missing_rows=pd.Series([0,0],index=["Green Park", "Holkar Cricket Stadium"])
batting_wins=batting_wins.append(missing_rows)
batting_wins.sort_index(inplace=True)
choices=fielding_wins>batting_wins
encoder={True:"Field", False:"Bat"}
choices.map(encoder)

And there's our results! Although that seemed like a lot of code, the logic isn't that hard to follow. Following a top-down approach, we had to
- Compare the fielding team wins to the batting team wins
- Ensure that the indices of both these sets lined up and had the same number of elements
- Save both subsets in different variables to perform operations on them
And finally, we mapped the truth values to "Bat" and "Field" to make our lives easier.
( Confession: I did not do any of this in one go. Everything you see here packaged into one neat block of code was preceded by a lot of warnings, a lot of head-scratching and plenty of trial and error)
Q3) Does the chasing team really have the edge in a match affected by rain?
Let's use the power of Pandas to answer this question in one line of code! If you've been following along with the code so far, this one should be a cakewalk!
df[(((df["toss_winner"]==df["winner"]) & (df["toss_decision"]=="field")) | ((df["toss_winner"]!=df["winner"]) & (df["toss_decision"]=="bat")))& (df["dl_applied"]==1)].size/df[df["dl_applied"]==1].size*100

Well there we go - the chasing team wins a whooping 81 percent of rain-affected matches!
Q4) Which venue is each team most strongest at?
Now this one takes a bit of thinking, as well as some domain knowledge. First off, what we require is a count of winner-venue pairs. Naturally, we know that each team will perform best in one given venue - most commonly their Home Stadium. Counts of these pairs should be expected to appear at the top of a sorted list (barring anomalies such as teams that have rebranded multiple times). Using this intuition, we may answer our question with the following code snippet :
team_venue_counts=df.groupby(["winner", "venue"]).agg("count")["id"]
team_venue_counts=team_venue_counts.sort_values(ascending=False)
team_venue_counts.head(9)

We see that teams do indeed have the largest number of wins at their Home Stadium. However, a percentage would be a much better indicator of how strong teams perform at home. This would require some splicing, appending and rearranging - both with the winner-venue pairs and the venue counts. Unfortunately, the complexity of that process lies outside the purpose of this post. Moving on!
Q5) How is our track record versus different teams?
This one includes a few convoluted steps - primarily because our team appears both in the "team1" and "team2" columns. But all in all, the code is again pretty straightforward :
as_team1_wins=df[(df["team1"]=="Royal Challengers Bangalore") & (df["winner"]=="Royal Challengers Bangalore")].value_counts("team2")
as_team1_games=df[(df["team1"]=="Royal Challengers Bangalore")].value_counts("team2")
as_team2_wins=df[(df["team2"]=="Royal Challengers Bangalore") & (df["winner"]=="Royal Challengers Bangalore")].value_counts("team1")
as_team2_games=df[(df["team2"]=="Royal Challengers Bangalore")].value_counts("team1")
(as_team1_wins+as_team2_wins)/(as_team1_games+as_team2_games)*100
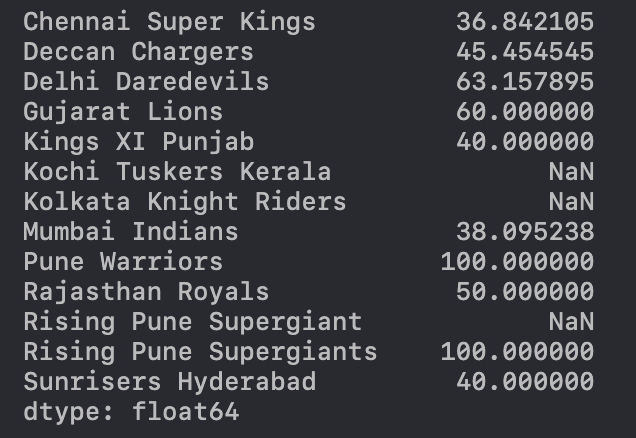
Now, I have to admit that that was a bit of a hack. The different variables used to store data weren't exactly the same size - leading to those NaNs in-between. However, it's still impressive that Pandas knew what to do with the rest of it!
Secondly, we see that there's two separate entries for "Rising Pune Supergiant" and "Rising Pune Supergiants" respectively. This certainly deserves some cleaning up!
Now it's your turn! Think you can fix those errors? As GM, what other insights might you obtain with this dataset? What other data may you need to augment it with in order to derive better insights? And last but not least, what may be the best methods to visualise our findings?
Any questions? Anything you think I might have done differently? Do feel free to let me know and I'd be more than happy to respond!





Top comments (2)
Ok that was a lot of IPL stuff and it was really nice!!!
Glad you liked it!