
Automatic text summarization allows us to shorten long pieces of text into easy-to-read, short snippets that still convey the most important and relevant information of the original text.
In this article, we'll build a simple but incredibly powerful text summarizer using Google's T5. We'll be using the PyTorch and Hugging Face's Transformers frameworks.
This is split into three parts:
- Import and Initialization
- Data and Tokenization
- Summary Generation
Check out the video version of this article here:
Imports and Initialization
We need to import PyTorch and the AutoTokenizer and AutoModelWIthLMHead objects from the Transformers library:
import torch
from transformers import AutoTokenizer, AutoModelWithLMHead
PyTorch can be installed by following the instructions here, and Transformers can be installed using pip install transformers. If you need help setting up your ML environment in Python, check out this article.
Once you have everything imported, we can initialize the tokenizer and model:
tokenizer = AutoTokenizer.from_pretrained('t5-base')
model = AutoModelWithLMHead.from_pretrained('t5-base', return_dict=True)
And we're set to start processing some text data!
Data and Tokenization
The data used here is a snippet of text from the Wikipedia page of Winston Churchill. Of course, you can use anything you like! But if you'd like to follow along with the same data, you can copy it from here:
Once we have our data, we need to tokenize it using our tokenizer. This will take every word or punctuation character and convert them into numeric IDs, which the T5 model will read and map to a pretrained word embedding.
Tokenization is incredibly easy. We just call tokenizer.encode on our input data:
inputs = tokenizer.encode("summarize: " + text,
return_tensors='pt',
max_length=512,
truncation=True)
Summary Generation
We summarize our tokenized data using T5 by calling model.generate, like so:
summary_ids = model.generate(inputs, max_length=150, min_length=80, length_penalty=5., num_beams=2)
-
max_lengthdefines the maximum number of tokens we'd like in our summary -
min_lengthdefines the minimum number of tokens we'd like -
length_penaltyallows us to penalize the model more or less for producing a summary below/above the min/max thresholds we defined -
num_beamssets the number of beams that explore the potential tokens for the most promising predictions [1]
Once we have our summary tokens, we can decode them back into a human-readable language using tokenizer.decode:
summary = tokenizer.decode(summary_ids[0])
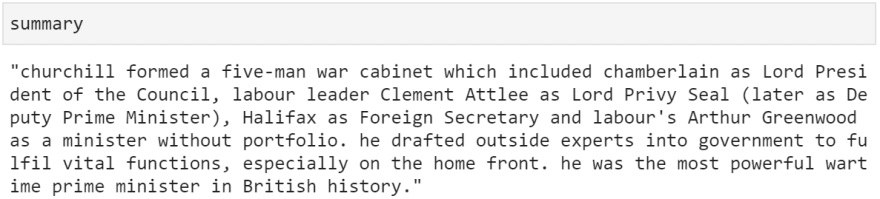
And with that, we've built a text summarizer with Google's T5!
Conclusion
That really is all there is to it. A total of seven lines of code to begin working with one of Google's most advanced machine learning algorithms on complex natural-language problems.
I find it astonishing how easy it is to put something like this together, and I hope this short tutorial has proved how accessible NLP can (sometimes) be - and perhaps solved a few problems too.
I hope you enjoyed this article. If you have any questions, let me know on Twitter or in the comments below. Otherwise, if you'd like more content like this, I post on Medium and YouTube too!
Thanks for reading!
References
[1] Beam search, Wikipedia





Top comments (0)