Apache Kafka is pretty versatile and it's quite common to hear different names for it. It is referred to as a queuing service, message bus (it is way more than that!), streaming platform (this one is accurate by the way), etc. From my discussion with many folks (esp. who are new to Kafka), a common source of confusion tends to be:
"Is Kafka a Topic or a Queue?"

This is quite expected because the official documentation also uses the same terminology - "The Kafka cluster stores streams of records in categories called topics."
A Topic is one of the most fundamental concepts in Kafka - think of it as a bucket to which you send data and receive data from.
Ok, so it's not a queue then?
Well, the truth is:
"Kafka is both a Topic and a Queue"
Let' see how...
Queue
Queue based systems are typically designed in a way that there are multiple consumers processing data from a queue and the work gets distributed such that each consumer gets a different set of items to process. Hence there is no overlap, allowing the workload to be shared and enables horizontally scalable architectures.
How it is implemented differs from system to system e.g. Rabbit MQ, JMS, Kafka, etc.
Kafka as a Queue

To build an application to process data from Kafka, you can write a consumer (client), point it at a topic (or more than one topic, but let's just assume a single one for simplicity) and consume data from it!
If one consumer is not able to keep up with the rate of production just start additional instances of your consumer (i.e. scale out horizontally) and the workload will be shared among them. All these instances can be categorized under a single (logical) entity called Consumer Group
In the above diagram,
CG1andCG2stand for Consumer Group 1 and 2, which are consuming from a single Kafka topic with four partitions (P0toP4).
A Kafka topic is sub-divided into units called partitions for fault tolerance and scalability. Consumer Groups allow Kafka to behave like a Queue, since each consumer instance in a group processes data from a non-overlapping set of partitions (within a Kafka topic).
Note that the maximum amount of parallelism is limited by the number of partitions of your topic e.g. if you have four partitions in a topic and start off with two consumers (in a group), each consumer will be allocated two partitions each. You can bump up to a maximum of four instances in which case each consumer will be assigned to one partition.
Topic
Pub-Sub systems use topics or channels to broadcast information to all subscribers/consumers. This is different than that of a queue where each consumer (assuming there are multiple consumers of course) gets a different set of data to process.
I used an example of a single application to explain the concept of Kafka as a Queue. Imagine you had to build multiple applications that need to process data from the same Kafka topic but do it differently e.g. one application to filter data by applying business rules while the other one needs to store it in a database - the possibilities are endless.
Kafka as a Topic
The key part here is the fact that all the applications need access to the same data (i.e. from the same Kafka topic). Take a look at this diagram (from the Kafka docs). Consumer Group A and Consumer Group B are different applications and both will receive all the data from a topic. It's as simple as that!
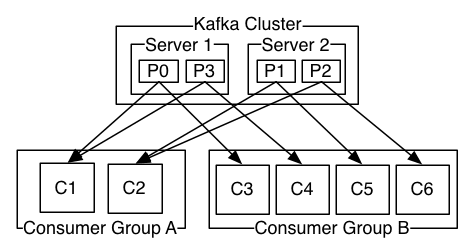
Internally, each application can scale out it's processing by using the "queue" mechanism described above.
That's it for this blog post. I hope you found it useful and stay tuned for more 😀

I would love to have your feedback and suggestions. Just tweet/DM or drop a comment 👇👇





Top comments (1)
nicely explained!! :)