
- Introduction
Introduction
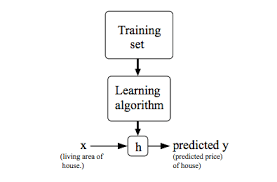
Machine Learning is the process of training machines to become intelligent and solve tasks with minimal supervision. You might be amazed at how YouTube intelligently recommends videos for you or how Spotify magically suggests new songs to you. What powers the intelligent recommendation or magically suggested songs is simply machine learning. Humans learned how to walk by observing how others walked and tried to replicate the process. Similarly, machines learn to perform tasks by iteratively following the patterns in a given dataset and then forming a mathematical function. Data scientists can use the mathematical function to make predictions on new datasets. As shown in the image below, training datasets are fed into the machine learning model. The model learns the patterns and develops a mathematical function (h). The mathematical function is then applied to a new dataset to make predictions. You can read this article to gain a better understanding of machine learning.
### MLOps Introduction
The Youtube recommendation model was built and then deployed on Youtube for users to enjoy. Imagine if Google built the recommendation model without deploying it on Youtube? That would be awkward, and we wouldn't be able to enjoy Youtube recommendations today. Unfortunately, most data scientists are comfortable with just building models without deploying them to production for end-users to enjoy. Machine Learning Operations (MLOps) is simply the process of shipping your machine learning models to production (this is just a basic definition). According to Wikipedia MLOps is
MLOps is a set of practices that aims to deploy and maintain machine learning models in production reliably and efficiently.
As shown in the image below, MLOps is an iterative method, that encompasses the:
- Design Phase
- Model Development Phase
- Operations Phase
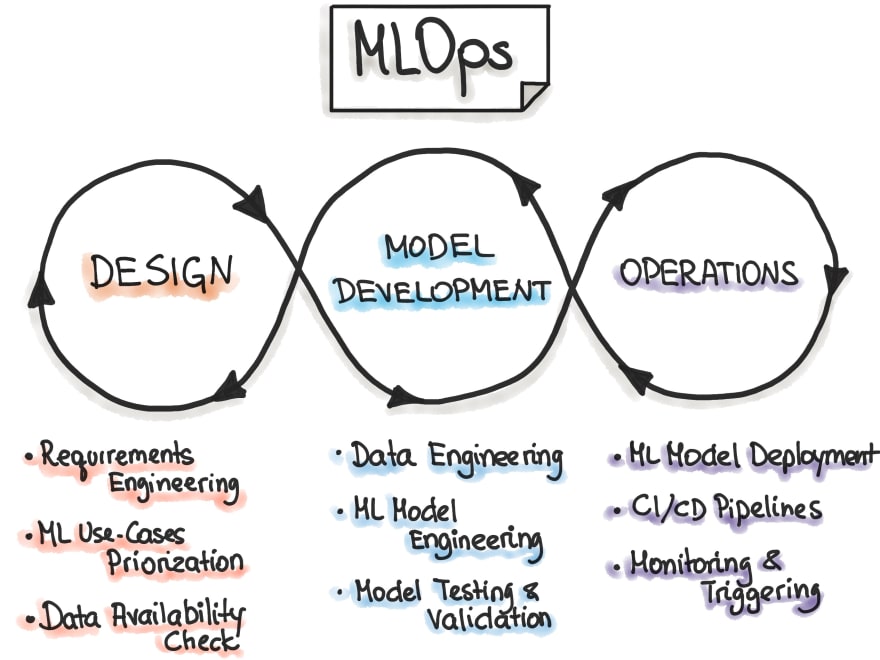
Fig.2 MLOps Phases source
Design Phase
Under the Design Phase we have other sub-phases, which are:
- Requirement Engineering
- ML Use-Cases and Prioritization
- Data Availability Check
Requirements Engineering
According to Javatpoint
Requirements Engineering (RE) refers to the process of defining, documenting, and maintaining requirements in the engineering design process.
Requirement engineering helps an individual/ company understand the desires of the customers. It involves understanding the customers' needs through analysis, assessing the feasibility of a solution/product, settling for a better solution, clearly framing the solution, validating the specifications, managing any requirements before transforming it into a working system.

Fig.3 Requirement Engineering Process source
The first step in any Data Science/ Machine learning lifecycle is requirement engineering. This phase is where you understand your customers' needs. For instance, Spotify was able to build a recommendation model because this is what most customers need. You can read more about requirements engineering here
ML Use Cases and Prioritization
This phase is where Machine Learning practitioners prioritize the impact of any proposed machine learning solution on their business. This phase is concerned with analyzing the importance of a proposed machine learning solution towards their goals. The truth is some proposed machine learning solutions aren't profitable to an organization. In this phase, companies drop those solutions.
You can read this article from Srivatsan Srinivasan,a Google Developer Expert; the report will give you more understanding of prioritizing Machine Learning Use Cases.
Data Availability Check
This phase deals with the process of checking if there are available datasets to train the model. You can't train any machine learning model without data
Model Development Phase
The model development phase encompasses these sub-phases;
- Data Engineering
- ML Model Engineering
- Model Testing and Validation
Data Engineering
The Data Engineering phase deals with collecting relevant datasets that will be used to train the model. Data validation is also carried out here; this ensures that the data is valid and clean. If you feed poor data into a sophisticated model, you will get a poor result. You can read this article to learn more about data engineering
ML Model Engineering
The model engineering phase deals with training the model with the data, performing feature engineering. Data Scientist/Machine Learning engineers sometimes try out other models, stack up two or more models together at this phase.
Model Testing and Validation
After you have trained your model, there is a need to test and evaluate the model's performance. You wouldn't want to deploy a model that is performing terribly on unseen data. The model testing and Validation phase deals with testing and evaluating the model on unseen data. While the model might perform better on the training dataset, you want to make sure that the model also performs well on an unseen dataset(test).
Different metrics can be used to evaluate your model; if you are working on a regression task, you can use mean squared error, mean absolute error, e.t.c, while working on classification tasks, you can use accuracy, f1 score, recall, precision e.t.c.
Operations Phase
Ml model deployment, CI/CD Pipelines and Monitoring & Triggering
Under the operations phase, we have these sub-phases;
- ML Model Deployment
- CI/CD Pipelines
- Monitoring and Triggering
ML Model Deployment
This phase deals with deploying the model to production; the production environment can be a website, mobile phones, or edge computing devices like embedded systems.
CI/CD Pipeline
CI/CD means Continuous Integration and Continuous Deployment. CI/CD is a set of practices that enables developers to change codes and deliver the code to production frequently and safely. CI/CD helps data scientists/ machine learning engineers continuously make changes to their model training, testing the newly trained model and deploying it frequently and safely. You can read this article to learn more about CI/CD
Monitoring and Triggering
This phase involves monitoring the model's performance in the production environment, triggering the CI/CD pipeline if the model performance drops below a threshold. The performance of a machine learning model can reduce due to changes in the production datasets; there can be a difference in the data used to train the model and data fed into the model during predictions in the production environment.
If the model performance falls below a certain threshold, then the model needs to be retrained and redeployed; the model retraining is done by triggering the CI/CD pipeline.
Articles Focus
The focus of the articles in this series is on building a machine learning model and deploying the model with Docker and Google Cloud Platform.
Machine Learning models are built to solve problems; hence, a problem statement needs to be defined before building any machine learning model.
Problem Statement
You just resumed as a data scientist at moowale; moowale is a real estate company that lists houses for sale. You have been tasked with building a machine learning model that can be used to predict the price of any building based on some given parameters. The model will be deployed to make it easy for customers to get predicted prices based on information they input into the moowale website.
N.B moowale is a Yoruba word meaning I am searching for a house [to buy].
Data Gathering/Data Engineering
Now that you have a well-defined problem statement, the next stage is to gather the data used to train the model. You can source datasets from public dataset repositories or talk to the data engineer to deliver the needed dataset to you. An existing dataset can be used to train the model; the house price prediction dataset on Kaggle will be used to train the model. You can access the dataset with this link; the train.csv dataset will be used to train the model.
Model Building
It's time to build our model, but we will need to explore the dataset (exploratory data analysis). To follow along, you will need to have an Integrated Development Environment like Jupyter Notebook/Lab (which most data scientists use). You can learn more about Jupyter Notebooks with this link.
Now that you have Jupyter Notebook, you can open it and follow along.
To explore the dataset, we will be using some python libraries, which we will import.
# importing necessary libraries
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
Pandas will be used to read the dataset, NumPy is a numerical module, matplotlib is a plotting module and %matplotlib inline helps Jupyter notebook render plots within the notebook.
Now that the necessary modules have been imported, the next step is to load and visualize the dataset.
# reading the dataset with pandas
dataset = pd.read("train.csv")
# Exploring the first five rows
data.head()

Fig. 4 Image of the first five rows of the dataset (Image by Author)
# printing the number of columns
print(f"There are {len(data.columns)} columns in the dataset")

Fig. 5 Printing the number of columns in the dataset (Image by Author)
There are 81 columns(or features) in the dataset; not all are useful for model building. You will need to rely on picking the necessary columns to be used to train the model. Data scientist either relies on domain knowledge gained from experience or consulting with a domain expert in the field of interest to choose valuable columns. For this task, I will just pick columns based on assumptions. Columns that will be chosen are 'MSSubClass',"LotFrontage','YrSold','SaleType','SaleCondition','SalePrice
data_new = data[['MSSubClass','LotFrontage','YrSold','SaleType','SaleCondition','SalePrice']]
# checking for missing values
data_new.info()

The LotFrontage has missing values; since the column is of float datatype, the missing values can be filled with the column mean, column median, or a constant number.
# Filling with a constant number
data_new['LotFrontage'] = data_new['LotFrontage'].fillna(-9999)
# check for missing values again
data_new.info()

There are no more missing values, the next phases is model building.
Looking closely at the data_new.info() result, you will notice that we have two columns with object data type.
Machine Learning models expect all columns to be in numerical format, hence converting the columns to numeric. LabelEncoder is widely used to convert categorical columns to numeric columns; you can read more about LabelEncoder here
# using label encoder to encode the categorical columns
from sklearn.preprocessing import LabelEncoder, StandardScaler
# saletype label encoder
lb_st = LabelEncoder()
# salecondition label encoder
lb_sc = LabelEncoder()
lb_st.fit(data_new['SaleType'])
lb_sc.fit(data_new['SaleCondition'])
data_new['SaleType'] = lb_st.transform(data_new['SaleType'])
data_new["SaleCondition"] = lb_sc.transform(data_new['SaleCondition'])
The .fit() method encodes each category to a number, and the .transform() method transforms the category to number (you need to fit before you can transform).
Now that all columns are in numerical format, it's time to build the machine learning model. Machine Learning Engineers/ Data scientists usually split the dataset into train and test sets (the train set is used to train the model while the test set is used to evaluate the model's performance). To split the dataset into train and test, the features used to train the model must be separated from the target.
# Separating the dataset into features(X) and target(y)
X = data_new.drop("SalePrice",axis=1)
y = data_new['SalePrice']
The features are named X, and the target is named y because machine learning is basically mathematical functions applied to data. Recall from mathematics that *f*X= y, the target(y) is computed by applying a mathematical function on your features (X) (this is what happens in machine learning or during model training).
# splitting the dataset into train and test set
from sklearn.model_selection import train_test_split
X_train, X_test, y_train,y_test = train_test_split(X,y)
Now that we have our train and test dataset, it's time to build our model. There are two significant types of machine learning tasks, Classification and Regression. Regression deals with numerical targets, while classification deals with categorical targets.
The target is SalePrice which is numerical; hence a regression model will be used.
There are different regression models; Linear Regression is the simplest to understand and beginner-friendly regression model. LinearRegression model will be used in this project to keep it simple); you can use other regression models like RandomForestRegressor etc.
from sklearn.linear_model import LinearRegression
lr = LinearRegression()
# training the model
lr.fit(X_train,y_train)
Model Evaluation
Recall that after building your model, you need to evaluate the performance of the model. Several metrics can be used to evaluate machine learning models; for regression models, metrics include mean squared error, mean absolute error, root mean squared error e.t.c. Root Mean Squared Error metric will be used to evaluate the model.
from sklearn.metrics import mean_squared_error
np.sqrt(mean_squared_error(lr.predict(X_test),y_test))
# this will give approximately 73038
The Root Mean Squared Error is quite large; machine learning engineers/ data scientists tries to reduce the error by trying other models and applying feature engineering. I won't be diving into that; the article's aim is not to minimize the error.
Now that we have our model, to use the model in production, you will need to save the model and the two label encoder that was initialized earlier.
# joblib is for saving objects for later use
import joblib
joblib.dump(lr,'lr_model')
joblib.dump(lb_sc,'lb_sc')
joblib.dump(lb_st,'lb_st')
joblib.dump() accepts two default parameters: the object you want to save and the name you wish to save the object with.
Now that we have our model saved, we have finally come to the end of the first article in this series.
Conclusion
This article has introduced you to machine learning, the importance of machine learning operation in the Machine Learning Lifecycle. How to frame a problem statement, gather data, build a linear regression model, evaluate the model and finally save the model for future use. In Part2 of this series, you will learn how to build machine learning APIs with flask, test the APIs and containerize the API with Docker.





Top comments (0)