Many development teams skip having a staging environment for their applications. They often submit a PR, potentially run tests in a CI system, merge to master, and then deploy to production. If they have a staging environment, it's often not a true reflection of the production environment due to lack of effort, complexity, or expense. This is a risky pipeline because there is no true integration environment or integration testing being performed. What’s worse is that if there is an issue, developers may engage in “cowboy coding” to try to resolve the issue on their live production environment.
In this article, we'll discuss some of the advantages of using a true staging environment in your software development lifecycle, and why they don't need to be complicated to set up.
What is a Staging Environment, Really?
A staging environment is another environment that you deploy to in your software development and deployment process. You deploy to a staging environment before you deploy to your production environment.
Staging environments are generally meant to be identical or nearly identical to production. This means that they have the same hardware, software, and configuration. The closer you can get to this, the more useful your staging environment will become.
That level of sameness between staging and production ensures that testing on your staging environment reflects what would happen in production under like circumstances.
Unlike development or limited integration test environments, staging environments utilize the same back-end and up-and-downstream services. They also have the same architecture, the same scale, and have highly similar or identical configurations to the production environment.
Depending on any regulatory factors (such as GDPR requirements) and your organization’s level of ability to anonymize data, a staging environment may even have anonymized or complete sets of production data in order to more closely mimic the real world production environment. That means that a staging environment is typically not released or made available to your production user base, but rather it is made available to an internal or pilot user base.
To control costs, you can deploy to your staging environment as part of a release cycle and then tear it down after the release has moved to production.
This methodology provides you with the ability to discover any code quality issues, a higher level of data quality issues, integration problems, and or other dependency issues which would simply not be present or obvious in an integration test environment or lower local or developer environments.
This methodology also gives you the ability to predict with a high degree of confidence, whether or not your production deployment will even be successful, allowing you to answer questions like “will this new service we wrote hang when it starts up in production?” If for example, the libraries we used worked on our computers but don’t work the same on the Linux VM we use to deploy.
Working with a staging environment forces you to validate all the assumptions you made during development and ensure that you have had the relevant thought exercises necessary to ensure deployment success.
Traditional Deployment with Staging Environment

The Risks of Deploying Without Staging
Any way you cut it, testing locally or running unit tests is not a sufficient litmus test for your product quality and functionality. Unit tests are written by humans, and humans are fallible. If you only test for known issues, then you can’t cover the issues you don’t know about.
People often forget about changes that cross service boundaries or gloss over dependencies with upstream users and database migrations. Sometimes a library you’re utilizing may work on your local machine but may not work in the cloud, and the only time you figure out that dependency failure, is when you deploy to production.
Often the data set being tested in lower environments is an unrealistic simulacrum of what is in production. Some people may think a staging environment isn’t necessary when using canary or blue/green deployments since the problem will be caught early, but you are still exposing users to bugs and misconfigurations.
All in all, this exposes users to potentially breaking changes, and depending on the level of the change, it can impact production data or other dependent services and processes.
Relying on faith and hope as a policy to ensure successful production deployments will inevitably run the risk of creating a negative perception of the quality of your product and ultimately result in lost sales, customer attrition, and possible violations of your customer SLAs.
The costs associated with these types of deployment or code failures can include:
- Having to provide immediate hotfixes
- Rolling back releases
- Impacts to development timelines
- Potential data loss
- Negative user experience impact
- Missed SLAs
- Reputational/brand risk
- Lost transactions/sales
- Lost customers
The benefit you receive from using a staging environment is a higher degree of quality assurance and customer satisfaction. Also, by reducing the impact or number of errors in your product you can see a lot of indirect cost savings. For example, you can reduce the amount of time you have to spend potentially rolling changes back, or reduce the time spent providing timely hotfixes that can also impact your regular development cycles by pulling developers out to deal with the problem. You also save the cost of potentially troubleshooting issues in production, and time lost in responding to user inquiries or bug reports.
Three Real World Scenarios
Let’s walk through some potential scenarios that could be easily prevented if you use staging environments. We’re working with an app called Bitcoin Price Index, by Mark Chavez. This a simple React-based application, which connects the user to the CoinDesk API to provide trend information for Bitcoin prices based on the currency selected.
1. Incorrect Service URLs
In our first scenario, while performing development in our lower (development/local) environments, we point our app to a mock CoinDesk API service to reduce our API usage and control costs. This URL should point to the real CoinDesk API before deployment to production.
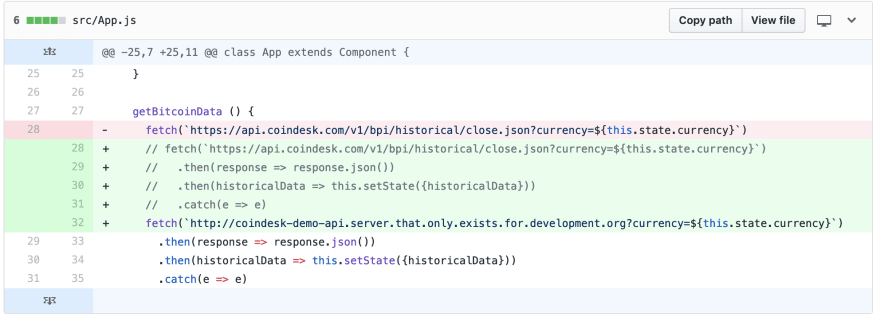
As you can see above, this mock URL somehow made it into our main service application code. (Bad practice, I know, but it happens more often than you’d think!)
This breaking change would have worked seamlessly in developer environments as the mock URL would have been presumably available in the developers’ network. In a staging environment which mimics production, that service dependency wouldn’t have been there, and this breaking change would have been caught before going directly to production.
This is the principle value of having a staging environment: Keeping your breaking changes from going directly to production by providing you a mirror environment to test and validate your changes in.
2. Errors in source control and reviews
Let’s look at another example: Two developers commit new features that both have the same style names, but in different lines of the CSS file. In each developer’s individual feature branch, the styles and subsequent product look as expected.
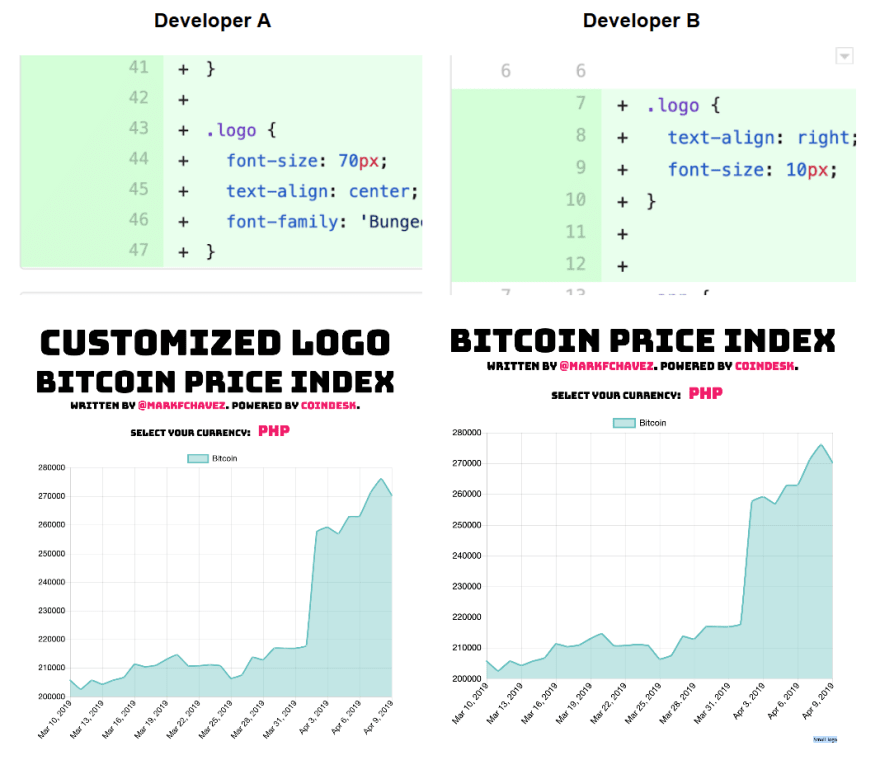
However, when each developer issues pull requests to merge this back into development, the overlapping styles don’t get picked up during review since they are in different pull requests. They get merged incorrectly and deployed to production. The final result leaves the product in an undesirable state.
3. Unmet Dependencies
Finally, let’s dive into the old developer expression “it worked on my machine”.
Here a developer added imagemagick to the stack to handle the modification of profile images uploaded to the site. The associated NPM imagemagick library “imagemagick” was installed and saved to package.json, but the underlying imagemagick-cli was only installed on the developer’s machine.
So when testing locally, the functionality worked exactly as expected, but when pushed to production, the feature doesn’t work and the following errors resulted in the logs.
Error: Command failed: CreateProcessW: The system cannot find the file specified
Without a staging environment, it’s easier for this type of problem to make it all the way to production.
The end reality of all these examples is that they are all completely preventable mistakes. These mistakes invariably happen, and may not be caught before production if there isn’t a staging environment. As your application grows in complexity, the potential for these types of errors also grows exponentially.
Using a staging environment as part of your SDLC and deployment lifecycle can reduce the risk of these errors being public mistakes, or private ones.
Staging Environments Don’t Need To Be Complicated
One common excuse for not using staging environments is they are too complicated or costly to set up. There is some truth to this as they can be an added expense. Associated DevOps can be an expensive endeavor, and staging environments can be as difficult to set up as your production environment. However, it does not need to be.
Modern cloud platforms provide the ability to spin up staging environments as needed and allow you to automate their deployment to be part of your standard deployment pipelines. They can prevent mistakes that would break production or block it from being deployed.
The easiest way to get started is to embrace modern cloud providers and their DevOps toolchains such as Heroku Pipelines, which can make deploying staging environments easy, even more cost-effective, and relatively painless.

Heroku Pipelines is a product from Heroku that allows you to manage a group of Heroku apps which share the same code base. Each app in a Pipeline represents a state in your delivery lifecycle. Heroku automatically spins up a staging environment when you deploy to your master branch. Once you’ve verified the app, promoting to production is as simple as clicking a button.
Alternative methods to automatically deploy staging environments include infrastructure as code and container orchestration solutions such as Terraform or Kubernetes.
Without an automated process to make this process easier for us, we would have to provision machines or containers that were identical to our production environment and then deploy them manually.
Ultimately, using a staging environment helps you to embrace modern software development and release methodologies to improve your team’s productivity. More importantly, it helps improve the quality of the product you deliver to customers.





Top comments (10)
👏Best👏in👏class👏behavior👏
We do this at Impartner (staging environments), and I can't tell you how many headaches are prevented by sticking to the process. I might just have to write an article about my team's environment strategy because if you aren't convinced yet my work isn't done.
We have a Dev/Stage/Prod setup, (well Dev/Stage/UAT/Prod, but that will have to wait for the article) and I like to explain it this way:
Dev is my domain as the developer. Expect it to be "broken" half the time, expect users to have access to things they shouldn't, and expect to see features that aren't fully fleshed out yet. Never demo Dev.
Stage is your domain as product owner/project manager/internal stakeholder. This is what you look to as a barometer for progress, and where you go to demo functionality. It should mirror Prod except for the latest stable updates from Dev, but never touch Prod data.
Prod is the client's/user's domain. Don't touch it if you can help it.
In my current role all of my projects integrate with platforms as a backend, such as our PRM, or client CRMs. Because of this, it makes a world of difference when each environment I work in has a matching backend environment. Having that extra step between Dev and Prod can be the difference between finding out the easy way or the hard way that the sandbox I had to work with hadn't been updated in 6 months. It's best to have a second sandbox that is kept refreshed/updated as frequently as possible.
Lastly, limit anything environment specific like your app's URL to a config file! I have to admit item 1 gave me some heartburn.
I love your breakdown between environments and user personas! I would have loved to use stage for demos in a prior company but it was broken half the time .
By the way, Heroku also offers a concept called a "Review app" that is automatically created for each PR. This can be useful for product owners and testers to see changes in isolation, whereas the full staging environment would have the integrated and latest set of changes.
Also, good work on setting up matching backends for your CRM and PRM. If this uses non-prod data even better because you aren't exposing customer information when testing/demoing.
My staging env doubles as a 'live' copy of the site where clients can play with & try out the new feature to approve it for lunch. I suppose if you don't have external stakeholders... but still seems risky to skip that step.
It can also be useful for product managers to demo new features and get feedback
Since I started working professionally and learnt about staging and production environments, in every project I've been part of there's always a staging environment.
For many of them, I was responsible for setting it up and keeping it working.
And there's no way in projects I worked everything go straight to production.
It is a no brainer. Dev -> staging -> production.
Not having one staging area represents a huge risk for project health because staging is the closest space where one could freely break things without fearing the results.
Nice article and ways to think about these environments.
We stress the importance of a staging environment to all of our clients. I'll definitely be referencing the thoughtful reasoning in this post when answering them in the future. Thanks for the helpful post!
The right way to have the architecture is to have a fix environment for SIT, then have a UAT environment along with a UAT-fix environment and then have a Prod-Stage environment, Prod environment and a Prod-Fix Environment for emergency fixes. These things are required if you are a large organization with large environment.If you want to SIT it self as a SIT plus UAT environment, you would need a SIT-fix environment. This Sit-Fix itself would serve the purpose of applying fixes for issues found in SIT/UAT testing.
What do you think about using feature flags/feature toggles as sort of "staging" environment. I.e. having only one production environment and deploy risky and big changes under feature flag. Enablr flag only for test user, or small amount of beta customers.
And what about that staging can give "false sense of safety". Ive seen many times devs to test on staging thoroughly just to then think that they can "push to production and go home", while actually they missed bug that was only present on production, because of specific production data, setup or scale.
IMHO even with staging you still need a way to limit blast radius with production deployments. And if you have that, do you need staging any more?
Lukáš these are all great issues to point out! IMHO phased releases using future flags are a great way to test major functionality changes out. In fact there is a popular library called scientist that does just that in a controlled way github.com/github/scientist.
You're also right that's important to minimize the blast radius of missed problems. Using future flags exposes customers to potentially broken code, and possibly incompatible versions of dependent services. It can even lead to data loss or data corruption. Having a staging environment with proper test cases and that closely mirrors your production environment will hopefully catch the most obvious problems before they impact customers, and before your dev team leaves for the day.
It's great that your dev team trusts your staging environment so well that it gives them a false sense of safety. However, it's only as good as the test cases and how well it mirrors production. You can test for "known knowns" but tests miss "unknown unknowns". These missed cases can and do cause major production outages, even at established companies.
A common rule of thumb is to never make major changes and leave, especially on a Friday if you want to enjoy your weekend! I think it's important to have post-deployment monitoring in place. If there is a critical change in KPIs/SROs they should be alerted to fix the problem or rollback ASAP.
If you're at a small startup you might not have all this infrastructure and policies in place and its more common to cut corners for efficiency. It becomes more critical at larger companies where major outages or bugs can cause thousands or millions of dollars of damage through lost sales, damaged reputation, etc.
I would say if you can do performance testing in a staging environment that's great! For this to make sense he would have to have similar hardware and similar data to test with. You can use apps like loader.io to do benchmarks. APM tools like NewRelic or AppOptics can also be added to staging and you can measure latency, etc. More testing is better, but you can't anticipate everything. Post-deployment monitoring is also equally important. You can do thinks like a canary or blue-green deployment to see how it handles load before deploying everywhere.