
Arguably version control is among the biggest innovations in software engineering.
Version control or revision control as it is called gives an immense power to the developers while developing the complex systems. Version control allows developers to keep the working pieces of the system available. Specifically version control allows critical capabilities such as reproducibility, traceability.
Reproducibility is like a magical wand which helps to create identical systems no matter how complex the system itself is.
Traceability helps developers to pick up any environment and track its dependencies. Traceability also helps to pick up any two versions of the environment and find out differences, if any.
Advantages offered by reproducibility and traceability are already well understood by the developer community such as :
high-quality — Only keep tested and working code, auditability — be able to track back to the origin where the change started with all details, disaster recovery — be able to reproduce the environment in deterministic amount of time whenever something goes wrong with the service, troubleshooting — be able to pinpoint the root cause or possible cause of any critical issues with the service.
Naturally the question arises can such a successful practice be applied to the cloud?
Until now, not much thought has been given in this direction, but as the cloud becomes more complex (spanning across multiple accounts, multiple regions, and multiple teams), and as the collaboration needed between different teams increases we will have to turn to our best innovation once again.
There are certainly differences when we decide to apply the version control to the cloud. The cloud is not a homogeneous entity like source code. Cloud instead can be seen as a layered onion, where each may have its own versioning scheme and the vertical slice needs to have its own.
The version control needs to be applied to the source code which provisions the cloud. The provisioning is typically done through IaC such as CloudFormation, Terraform or Pulumi.
But only applying version control to IaC source code is not sufficient. IaC is responsible for provisioning the cloud resources and these cloud resources have their own lifetime as well. E.g. The EBS volume can overrun the lifetime of EC2 to which it attaches. This attachment is reflected in resource properties, and these properties keep changing based on what kind of cloud resource it is.
Thus cloud version control onset requires us to protect at least three major entities — the provisioning code, the cloud resources it provisioned in response and the resource properties which may change over the period.
Version controlling the provisioning code is easiest of all. After all, it is a mature art. Keeping these files under git or similar tools, is what is needed. Since IaC is source code, it also enjoys other benefits such as IDEs, code reviews, and continuous deployment. IaC allows the developers their intended state of the cloud environment, however, there is a constant state of flux between what is desired and what is deployed or is running in the cloud.
To version control the cloud resources, we need to work with cloud control plane APIs. These APIs need to be used to fetch all the cloud resources available, as well as their resource properties at that point of time. The version control would also need to be intelligent to mark the resource lifetime as created, available and deleted. We may call this as a snapshotting operation of the cloud. The snapshot marks all the cloud resources and their properties available at that time.
While theoretically it looks plausible, we need to understand the ground reality. Cloud resources seldom exist in isolation. A complex relationship graph binds these resources together. Thus any foolproof solution needs to have a comprehensive coverage of cloud resources. However, this is a huge ask, given the speed at which the cloud vendors are introducing new services and expanding existing services. At the time of writing, there are approximately 250 (+) cloud services available for AWS cloud. In fact, from IaC standpoint, Terraform has much better coverage than AWS’s own CloudFormation and CloudFormation is perceived as lagging always.
So,have there been any efforts by the cloud vendors for cloud versioning? Mainly it is at two levels where we can see it happening. Individual cloud resource levels and by introducing services for cloud resource configuration management.
In AWS Cloud, we now see the resource versioning getting introduced at the resource level. Eg. ECS task definitions are explicitly versioned, similarly launch templates have versions. While these versioning schemes are useful for that individual cloud resources, from an overall cloud perspective having these are not enough. You still need to have snapshotted information about all cloud resources. That is, we need an holistic approach which covers all of the cloud -across multiple accounts, multiple regions, and well almost all cloud resources.
If you think this looks complex, yes it is. And we still haven’t discussed drift detection and reverting to a previous state. It deserves its own separate post.
Naturally, when such versioned cloud information is available would there be additional benefits other than we discussed earlier? There could be multiple such as: cloud linting, automatic suggestions for cloud resource drifts (desired state vs actual state), security vulnerability identification (via rules), notifications in case of accidental resource spawn (most common error for early startups) and obviously auto rollback in case of errors. One further interesting use case that could be served is cloud visualization, which I believe would become essential in the coming time.
Another interesting use case that can be served is, allowing to query the cloud resources and their relationships. Again this is a topic which deserves its own dedicated post.
Fortunately few services have emerged in this space which can be helpful.
AWS Config, which is a cloud resource configuration management service by AWS itself. The AWS service works on the notion of recorder, which needs to be configured to record (snapshot) the cloud resources. The recorder can be configured to include all cloud resources or selective few. The resource properties are also recorded. These recorded configuration snapshots then can be stored as long as 7 years (which is default value) in S3. By default, the recorder works only for a single account and region. If you need to make it work for multiple accounts and regions, you need to create aggregators specially.
In a true AWS fashion, the cloud resources this service covers is limited, approx 100 resource types supported, at the time of writing. Another issue with AWS config is pricing. Each resource configuration recording takes ~$0.003/region. For medium to large clouds this could become very expensive very easily. Especially when something breaks and keeps changing the resource property quickly. Due to its pay-per-use model the service pricing is complex.
Fugue.co, is already a known service with its regula open source tool, and many of you might already be familiar with it. You may add cloud accounts to fugue, which would then be scanned (snapshotted). You may then establish a baseline, which would serve as a golden snapshot against which drift would be determined. The Fugue has a working visualizer as well, which can sometimes make cloud management easy. It also supports ~190 cloud resource types, which is way better than AWS Config.

However, fugue does not maintain cloud resource history and one cannot see resource (properties) history, except the drift. It also does not clearly identify the resource lifetime. Fugue seems to be more focused towards compliance and perhaps that explains the pricing tag it comes with ($1250/month).
CloudYali.io, is in an exclusive free preview release, and you need to sign up for an invite. It already supports ~ 250 cloud resource types. It is possible to add multiple accounts to the service, which would then snapshot each account. All the cloud resources, from different accounts and regions can be then seen at a single place. Thus it can be used for comprehensive resource inventory.
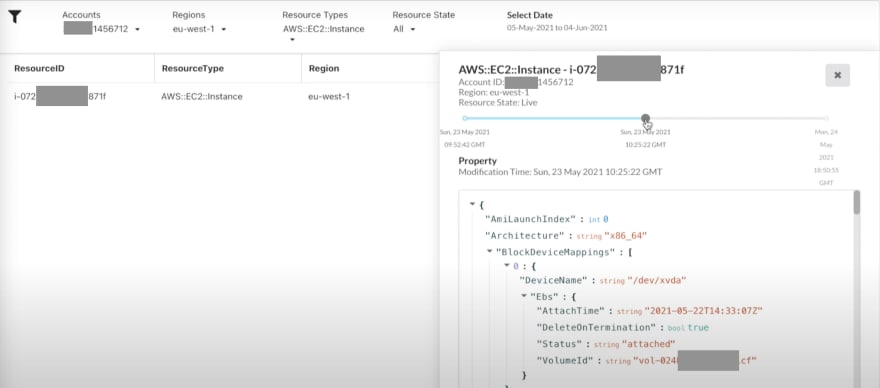
The UI makes it easier to look for resources of a specific type, which can further be narrowed down around accounts, regions or even date range. In a distinguishing feature, CloudYali clearly marks the lifetime of each resource, thus identifying when a specific resource was created or deleted. Interestingly, it is possible to view all the resource properties changing at a single place.
In coming time, I think we would see a more mature services for cloud versioning. Please share your thoughts.
Thanks for reading!





Top comments (1)
Just read your article while I'm researching how to know which version (as in git revision) of the infrastructure (as code) is currently deployed to a certain environment/stage.
If I understood your article correctly, you are arguing that you want to "snapshot"/"version control" the actual resources that have been allocated, right?
But wouldn't it already be a good start if there is a way to know which revision of your infrastructure as code, has successfully been deployed according to the tools you use? At least as long as you trust that they work as you understood it, this should be "very close" so potentially "close enough" to the reality, right?
Have you seen such an approach anywhere? Or have any good resource/idea about it?