A primer on the concepts underlying containers and Kubernetes, and how they enable new patterns for application development.
The Container is the New Process
In the beginning there was the computer. The computer, when it started, ran a program called init. The init program then ran every other program that was needed: servers, terminals, and window managers. init could do several interesting things, like starting a program on boot, running a program at regular time intervals, and making sure that programs that it had run had not failed and crashed, whereupon it would restart them. The programs running could see everything on the computer: the other running programs, all files, and the network.

Because it gives programmers an easier model to reason about things by compartmentalizing them, tools to create namespaces were developed. Programs, or processes, running in a namespace can see only the other processes in the same namespace. If they look for files, they see only the portion of the hard disk allocated to that namespace. From a security perspective, a compromised process in a namespace can affect only that namespace.
Tools like Docker and Rkt were developed to use these features systematically. These tools offer the advantage of packaging up a namespace as a container so that it can be easily moved to a different computer, knowing well that it will continue to run in exactly the same way because of its isolated nature. In fact, it’s often easy to think about containers like tiny computers that run completely independently. Because these new tools are so easy to use, they have become a very popular way to build software.
The container is the new process.

Scale: A Good Problem to Have
A computer has finite resources, and it can only process so much data and run so many programs at the same time. A simple way to deal with increased load such as more users, or larger data sets is to scale vertically or add more processing power and memory to the computer, but this gets prohibitively expensive very quickly and there is a limit to how far you can go. Another way is to horizontally scale by adding more computers. These computers now form a cluster.
Applications need to be built differently to run well on a cluster. For example, if we make sure that two copies of the same program can operate without needing to access the other’s data, then we can confidently run multiple copies of the same program on multiple computers and know nothing bad will happen.

Although containers themselves do not give us any extra tools to build distributed applications, thinking at this level of abstraction makes it easier to build applications for clusters. The container model encourages the assumptions that
- there may be multiple copies running (build for concurrency),
- containers may be started and stopped dynamically on any computer in the cluster (prefer statelessness, ephemeral-ism), and that
- computers or processes may fail or be unavailable at any time but the whole system should still keep working (build for failure and recovery).
With so many computers to manage in the cluster, we are presented with some additional challenges.
- Firstly, we need to manage resources on the computers like processing and storage. This means that we have to efficiently distribute and schedule the processes that consume them across different computers.
- We also need affinities or ways to run related processes together for efficient sharing of resources; and anti-affinities to make sure that processes that compete for the same resources are not run on the same computer.
- For instance, if we wanted to run two copies of the application server process to serve twice the number of requests, we would want these processes to run on different computers in the cluster.
- With many processes running all over the place, we need a way to discover and communicate with all of them. We can communicate with a process if we know the ip address of the computer on which it runs.
With a single computer there is only one ip address. With multiple computers, we need to maintain a map of processes to ip addresses, such as in a distributed database like etcd. When a process starts on a computer, we add this information to the database. We also need to remove the entry from the database if the process fails, or the computer goes down.
Programmers are already very good at writing applications that run on one computer. Ideally, what we’d like to do is have a tool that takes all the computers in the cluster and presents it to the programmer like one big computer.
A step in this direction is Fleet on CoreOS which is basically the idea of the init process on one computer extended to an init for the entire cluster.
The Kubernetes project, introduced by Google, brings us closer to the model we want of having one giant computer.
Kubernetes: The Pod is the New Computer
The first thing Kubernetes does is take away your computers and give you back a single giant computer as a Kubernetes cluster.
A Kubernetes pod specifies a set of Docker or Rkt containers to run.
Now, instead of interacting with different processes running on different computers in the cluster, we can see different processes running in different pods in the Kubernetes cluster.
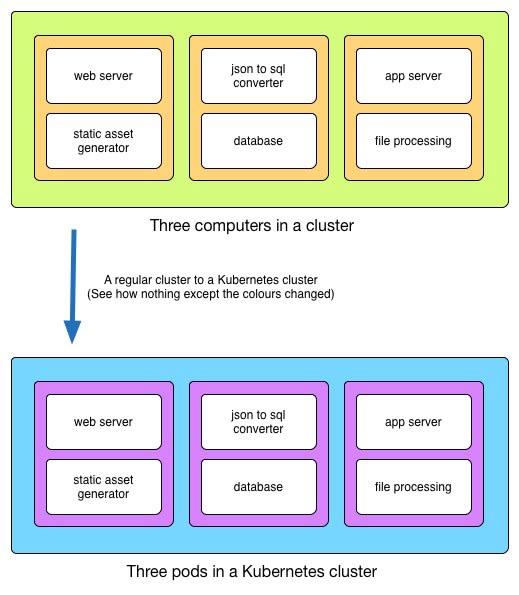
Before, we thought of what processes to run together on the same computer. Now, we can think what pods to build around what groups of processes; pods become a nice way to model a functional unit of an application. We can even just drop in pods built by the community and have it working straight away, for instance for logging and monitoring.
All processes in a pod are run on the same computer, this solves sharing resources like a mounted disk. In the background, Kubernetes allocates pods to different computers or Kubernetes nodes. We can set criteria by which this occurs like resource constraints and affinities to other pods and to nodes.
A computer is a collection of resources, some processing, memory, disk, and network interfaces. Just like a computer, a pod too can be assigned a quantity of resources from the underlying pool. It also receives its own network interfaces and ip address on a virtual network for pods.
The pod is the new computer.
If we need a particular function to scale, we just run more copies of the pod on the cluster. When hardware is limiting, we just add more compute or storage resources to the cluster. By decoupling the resource from the function that it was created to perform, the scheduler can ensure that all available compute resources are being used as efficiently as possible.
The Kubernetes replication controller is responsible for making sure that a certain number of copies of a same pod is always running at any time. Like a distributed init, if a pod fails; because a process in it failed, because pod dependencies failed, or because the node it was on goes down; Kubernetes detects it and brings up another copy on an available node.
A Kubernetes service keeps track of all pods of a certain type in the cluster. For instance, we could have a app server service that keeps track of all the app server pods in the cluster. Services form a very convenient abstraction; our application can quickly find all functional units of a particular type and distribute work over them.
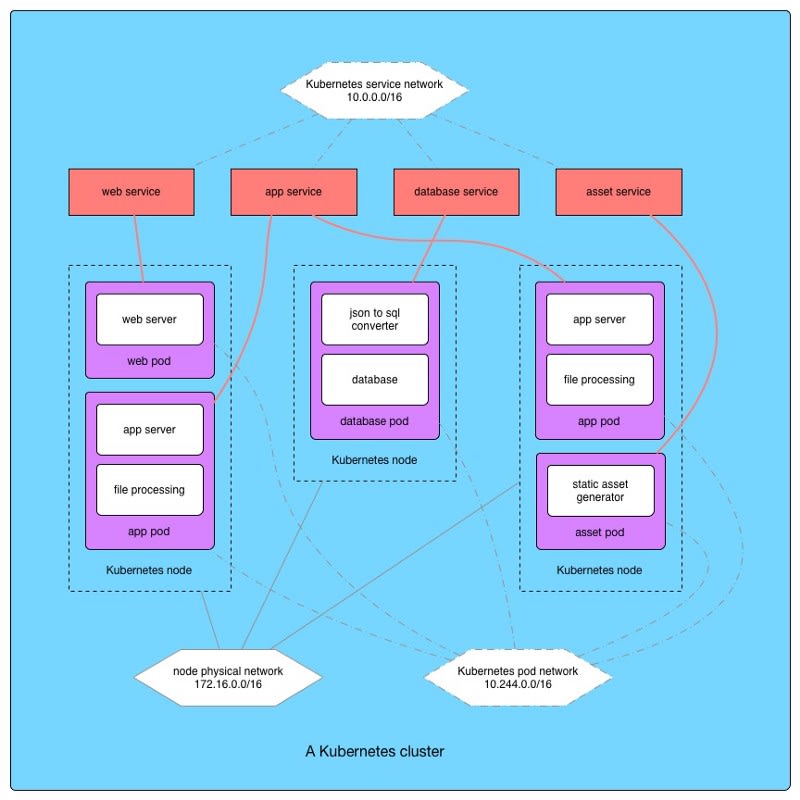
Kubernetes is as much a framework to manage and schedule processes over a cluster as it is a new mental model to build applications on top of enforced by its grouping of processes in pods and discovery enabled by services.
Full Circle and the Road Ahead
Managing one computer is already a hard problem. Managing a whole bunch that talk to each other is much more complex. Thanks to the good people who’re making incredible tools like Docker and Kubernetes, we now have simple models like containers, and tools for making clusters of computers behave like a single computer. Building applications at scale has never been easier.
Containers and cluster management tools have also impacted the way people are building applications. They create new patterns and abstractions, the implications of which are still being explored. For instance, it would be interesting to use containers to build reusable application components and libraries. At Hasura, we’re building components for databases, search, user management, and file management amongst other things so that applications can be quickly built by assembling these components and tying them together.
In general, we’ve come further in our pursuit to create simpler models. The fact remains that all software today is about running code and executing functions. In that respect, everything we’ve built is just about managing these functions: grouping them, running multiple copies of them, locating and speaking with them, and handling failure. Pushed to its logical conclusion, perhaps some day we will see a system where we specify only functions, and the system takes care of literally everything else. That would be nice.
Add backend APIs to your apps in minutes with the Hasura platform. Take it for a spin here: https://hasura.io





Top comments (0)