
What is pandas?
Pandas is an open source library in Python which allows us to handle data with two-dimensional data tables. It is built on top of NumPy package, and they are frequently used together. Pandas library depends on NumPy array to implement some of its objects.
Pandas was originally created by Wes McKinney. On the book "Python for Data Analysis", Wes McKinney says where the name "pandas" comes from:
The pandas name itself is derived from panel data, an econometrics term for multidimensional structured datasets, and a play on the phrase Python data analysis itself.
Pandas contains data structures and data manipulation tools meant to make data cleaning and analysis fast and easy.
It is one of the most preferred and used tools in data wrangling. If you don't know what it means: data wrangling or munging is the process of transforming and mapping data from one "raw" data form into another format, making it more appropriate for analysis, for example.
With pandas it is possible to load your data into a dataframe, which means that it aligns your data in a tabular fashion as rows and columns. Additionally you can select subset of data, merge dataframes, group by specific values, run functions, and much more. It's like a SQL but with Python.
Why should I use pandas for analysis?
When I started to learn Python and specifically pandas I was wondering why should I use it instead of plain NumPy. I can do several things with NumPy arrays as well, but I found that with pandas I can work with both tabular and heterogeneous data, and it is the biggest difference between pandas and NumPy. NumPy is for working with homogeneous numerical array data. If you intend to deal with data analysis you will have to work with different data types.
Besides, pandas DataFrame object is easier to work when you compare it to working with lists or dictionaries through loops or lists comprehension.
Installing
Run the following commands depending on your operational system.
Ubuntu
$ sudo apt-get install python3-pandas
MacOS
# install pip
$ sudo easy_install pip
$ sudo pip install --upgrade pip
# install pandas with pip
$ pip install pandas
Trying it out
Once you have pandas installed in your machine, in any Python runner you can try it out by running the following code:
import pandas as pd
df = pd.DataFrame({'result': ['It works']})
df
Note [1]: You can start Python by typing 'python3' on your terminal or you can use another environment to run Python, such as PyCharm and Jupyter Notebook.
Note [2]: If you don't have python3, update your python! Python 2.x will be supported until 2020.
Pandas main data structure
Pandas has two types of data structures: Series and DataFrame.
As you read at the beginning of this post, pandas loads your data into a dataframe composed of rows and columns³, where rows have index and columns have names. Each column is a Series object, so we can conclude that a DataFrame is a collection of Series objects.
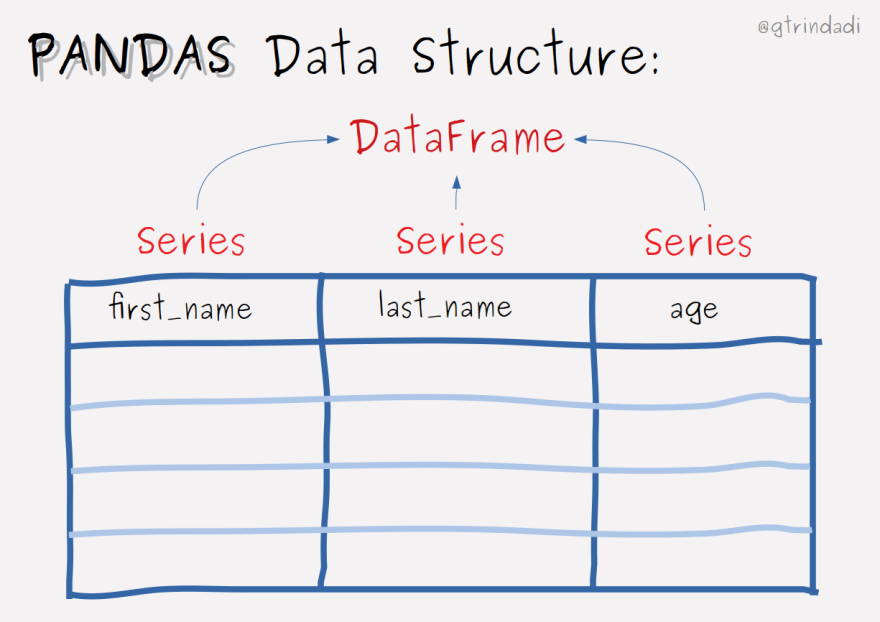
Note [3]: You might see in some articles on the internet that columns are called 'variables', and rows as 'observations'.
Series
A Series is the data structure for a single column of a DataFrame, in other words it is a one-dimensional data structure. They are capable of holding any data type (integers, strings, float, Python objects, etc). Series has elements of a single type.
The first element in a Series is assigned the index 0, being it a zero-based indexing. Therefore the last element has the index equals N-1, where N represents the total number of elements in the Series.
The values of a Series are mutable, however the size of a Series is immutable and cannot be changed. So, to change the Series size, you need to change the DataFrame size too; in other words, if you want add a value in a Series you need to add values to all the Series in a DataFrame.
DataFrame
DataFrame is a collection of Series, like a two-dimensional data-structure, where each Series can have its own type.
As Series, the rows in a DataFrame works with zero-based indexing.
DataFrame is size-mutable which means that elements can be appended or deleted from it.
Wrapping up
In this post you learned that pandas is a library in Python which helps us to deal with two-dimensional data. It has a data structure to ease the data manipulation and data analysis, and that's why we can use pandas for analysis.
We also learned how to install and try it out in your machine.
And we finish it learning about its data structures, where pandas is composed by DataFrame that contains a collection of Series.
In the next post I will show you how to read a file in pandas and some of the basics DataFrame operations.





Top comments (2)
This was a great intro! Thanks!
I'm so glad that you liked it. 😊