What is Graphql?
a "spec" that describes a declarative query language that your clients can use to ask an API for the exact data they want. This is achieved by creating a strongly typed Schema for your API, ultimate flexibility in how your API can resolve data, and client queries validated against your Schema.
Core Concepts
Graphql can be quite different based on how it is handled on the server-side vs. in client-side applications.
Server Side
On the server side graphql is about creating a graph based on the shapes of some objects that you'd like to expose to the web in the form of an api. This allows your users to query that graph in whatever manner they need. You have no control of what data is fetched when, the client dictates that at the time of making a request.
Client Side
Client side graphql operations mainly revolve around the fetching the exact data needed by various application. Clients make requests for data using queries and mutations which allow clients to ask for specific data and even manipulate that data.
Server-Side Config
Schema
typeDefs - since graphql is a strongly typed framework, it requires a strict typeDef of each part of your data.
resolvers - similiar to controllers in a REST api, and are responsible to retrieving data from a data-source. Whether that is a database, in memory, cache or even other apis.
query definitions - queries are are another type in graphql which the client side will primarily use in order to format their request body to meet the needs and demands of their particular application and use-case.
mutation definitions - similar to handers from a REST api, and are functions used for returning values for fields that exist on Types in a Schema. Resolver execution is dependent on the incoming client query.
composition - the ability to compose different apis together underneath a single graphql umbrella.
schema - all of the above components are combined to form a graphql schema, which is a similar to a snapshot of the data your api handles and instructions on how it will handle that data when responding to specific requests.
fragments - similar to partials in some front-end rendering libraries, fragments allow the required logic for queries and mutations to not overly repeat itself. When working with same/similar data there can be a lot of re-use, and fragments facilitate that ability.
Creating a Schema
Schemas are created using (SDL ) Schema Definition Language. Primarily this is used to define our graphql types, such as our queries, resolvers, and mutations.
☝️ Schemas can also be programmatically created using language constructs. In javascript these are funtions that return our schema.
-
Types- a construct defining a shape with fields -
Fields- keys on a Type that have a name and value type -
Scalars- primitive value type built into GraphQL -
Query- type that defines operations clients can perform based on schema -
Mutation- type that defines ouw clients can modify or create data
GraphQL Hello World Server
Minimal ApolloServer
// converts a template string into a graphql schema
const gql = require("graphql-tag");
// https://tinyurl.com/lxpwd2z
// graphql server
const { ApolloServer } = require("apollo-server");
// https://tinyurl.com/y3akd5kh
// schema definitons:
const typeDefs = gql`
type User { # describes the shape of the User type
# non-nullable fields ('!')
email: String!
avatar: String!
friends: [User!]! # array of users, should always return an array of users
}
type Msg {
title: "String!"
}
type Query { # used to define data requested from api
me: User!
msg: Msg!
}
`;
const resolvers = {
//creates a 1to1 mapping for each query defined above
Query: {
me() {
// resolver for the 'me' query
return {
// hard-coded resolved dummy data
email: "myemail@email.com",
avatar: "https://source.unsplash.com/random",
friends: [],
};
},
msg() {
return {
title: "\"this is a default message\","
};
},
},
};
// server is instantiated wtih typeDefs and resolvers
const server = new ApolloServer({
typeDefs,
resolvers,
ctx() { // creates a context object on our server:
return { models }; // allows resolvers and muations to access models
},
});
server.listen(4000).then(() => console.log("server running on port 4000"));
As we see above the minimum things we need to build a graphql server:
- A Query Type
- with at least one field
- And a resolver for any field queries
Which is basically saying we need a Schema with atleast one query and resolver present.


Resolver Signature
fieldName: (parent, args, context, info) => data;
| Argument | Description |
|---|---|
parent |
This is the return value of the resolver for this field's parent (the resolver for a parent field always executes before the resolvers for that field's children). |
args |
This object contains all GraphQL arguments provided for this field. |
context |
This object is shared across all resolvers that execute for a particular operation. Use this to share per-operation state, such as authentication information and access to data sources. |
info |
This contains information about the execution state of the operation (used only in advanced cases). |
Resolver Arguments
@param
: initialValue (aka - "parent", "_")
Query: {
demo(initialValue, )
}
initial value contains the parent resolvers context, this is because queries are executed in heirachical succesion, so the child query retains access to the parent query's context. and that is accessible as
initialValuefrom any child query.☝️ NOTE: top-level queries will not have any relationships above them as no other queries get resolved before them. So
initialValuewill benullfor all top-level queries.Query: { demo(_, ) }⚠️ You may see this represented as an underscore: (
_). This simply tells us that this function is ignoring this argument, and makes no use of it.
@param
: arguments (aka - "args", "_ _")
Query: {
demo(_, arguments)
}
arguments- contains any arguments that get passed into our mutations and queries, if any when there are any.☝️NOTE: When the query or mutation doesn't make use of the arguments object it can also be represented with two underscores: (
_ _)❗️ IMPORTANT: expected arguments must be defind in the Schema, graphql will not have the ability to handle any unknown arguments, it will only act on arguments that is has prior knowledge of how to handle.
- Arguments can be added to any field (if necessary)
type Query { pets(type: String!): [Pet] }Here the pets query takes an argument that is a
String, which sets thetypeof the pet.This can be accessed from our resolvers as:
Query: { pets(_, { type }, ctx) { return [/* pets */] } }
- Must be either an
InputorScalarType.
@param
: context (aka - "ctx")
Query: {
demo(_, __, context)
}
An object exposed manually through our apollo server which allows us to access things like our models and database from our resolvers.
☝️ Context must be instantiated on the server along with resolvers and typeDefs:
// api/src/server.js const server = new ApolloServer({ typeDefs, resolvers, ctx() { return { models }; }, });
@param
: info (aka - "ast")
Contains the abstract syntax tree of the current model. Contains information about the operation's execution state, including the field name, the path to the field from the root, and more.
⚠️ This param is rarely used.
Input Types
Input Types are field definitions that can be re-used to populate the arguments necessary for different resolvers.
💡 Think of them as Types for arguments.
- All field values of input types must be either other
InputTypes orScalars// api/src/schema.js input PetInput { name: String # optional type: String # optional }This can be used to populate the input field arguments for our pets resolver definition:
// api/src/schema.js type Query { pets(input: PetInput): [Pet]! }And now this will be available on our pets resolver as input:
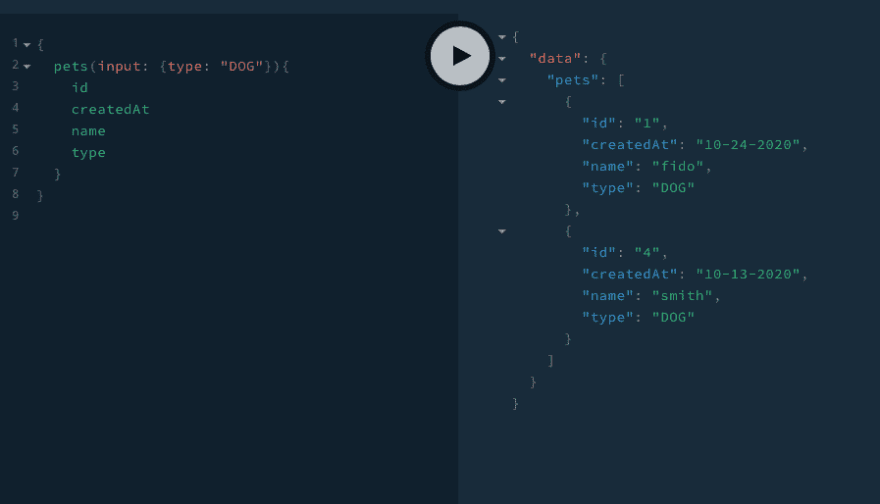
// api/src/resolvers.js Query: { me(parent, args, context) { console.log(parent, args, context); return { id: "oajsdfkla", username: "bob1", }; }, pets(parent, { input }, { models }) { console.log(input, models); const pets = models.Pet.findMany(input || {}); return pets; }, }, }Finally we can query for this data using our gql playground:
# playground query { pets(input: { name: "Fido", type: "Wolf" }){ id createdAt name type } }❗️Must use double quotes (
"") in input field arguments
Challenge
- define query type for the user and pet model in api/src/db/schema.js
{
"user": {
"id": "string",
"username": "string"
},
"pet":{
"id": "string",
"createdAt": "number",
"name": "string",
"type": "string"
}
}
create query type for retrieving an array of pets
instantiate apollo server with required typeDefs and resolvers
// api/src/db/schema.js
const { gql } = require("apollo-server");
const typeDefs = gql`
type User {
id: String!
username: String!
}
type Pet {
id: String!
createdAt: Int!
name: String
type: String!
}
type Query {
me: User!
pet: Pet!
}
`;
module.exports = typeDefs;
// api/src/resolvers.js
module.exports = {
Query: {
me() {
return {
id: "oajsdfkla",
username: "bob1",
};
},
pet() {
return [
{
id: "lkajsdflkjasdflkj",
createdAt: Date.now(),
name: "fido",
type: "mini wolf",
},
];
},
},
};
returns hard-coded data matching each resolvers expected output.
// api/src/server.js
const { ApolloServer } = require("apollo-server");
const typeDefs = require("./schema");
const resolvers = require("./resolvers");
const { models, db } = require("./db");
// add models to apollo-context so that they are available via mutations && resolvers:
const server = new ApolloServer({
typeDefs,
resolvers,
context() {
return { models };
},
});
server.listen().then(({ url }) => {
console.log(`🚀 Server ready at ${url}`);
});


🛠 FIX: pets query not resolving can't read the model from context??
{ "errors": [ { "message": "Cannot read property 'Pet' of undefined", } ] }
Query arguments:
type Query {
me: User!
pets(input: PetInput): [Pet]! # takes optional resolvers defint by PetInput
pet(input: PetInput): Pet # returns a single pet
}
pets(_, { input }, { models }) {
const pets = models.Pet.findMany(input); // uses input to populate db query
return pets;
},
pet(_, { input }, { models }) {
const pets = models.Pet.findOne(input); // uses input to populate db query
return pets;
},
uses the input arguments to allow us to search for matching data from database

Mutations
A Type on a Schema that defines operations a client can perform to mutate data (CRUD).
Creating Mutations
- Define
MutationType on Schema - Add fields for
MutationType - Add arguments for
Mutationfields (mutations will likely always require arguments) - Create
ResolversforMutationfields
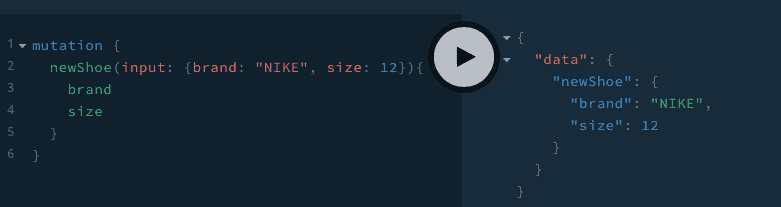
const typeDefs = gql`
#########
input NewShoeInput {
brand: String!
size: Int!
}
type Mutation {
newShoe(input: NewShoeInput!): Shoe!
}
##########
`
const resolvers = {
Query: {
/*...*/
},
Mutation: {
newShoe(_, { input }) {
shoes.push(input);
console.log(shoes);
return input;
},
},
}
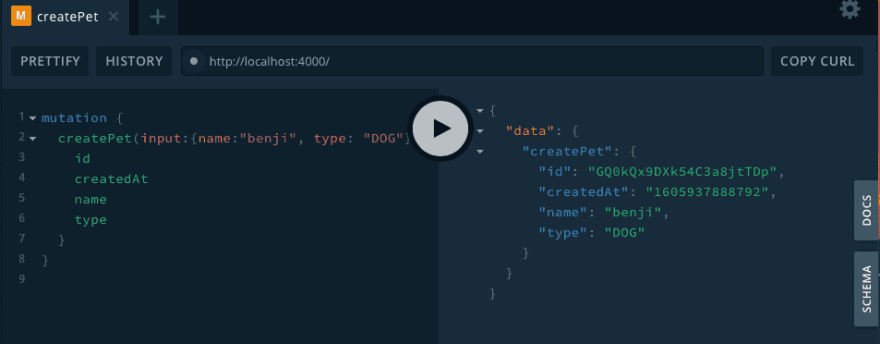
Challenge
Create a mutation to create a new pet:
// api/src/schema.js
type Mutation {
createPet(input: PetInput): Pet!
}
// api/src/resolvers.js
Mutation: {
createPet(_, { input }, { models }) {
const newPet = models.Pet.create(input);
return newPet;
},
},
Advanced SDL (Schema Definition Language)
Enums
A set of discrete values that can be used in place of Scalars. An enum field must resolve to one of the values in the Enum. Great for limiting a field to only a few different options.
☝️ By default
Enumsresolve to a string.
const typeDefs = gql`
enum ShoeType {
JORDAN
NIKE
ADIDAS
}
type Shoe {
brand: ShoeType!
size: Int!
}
`
Now we have limited the types to only the ones we've listed in our enum as options.
Interfaces
Abstract Types that can't be used as field values, but instead are used as foundations for explicit Types. Great for when you have Types that share common fields, but differ slightly.
interface Shoe {
brand: ShoeType!
size: Int!
}
type Sneaker implements Shoe {
brand: ShoeType!
size: Int!
sport: String!
}
type Boot implements Shoe {
brand: ShoeType!
size: Int!
hasGrip: Boolean!
}
❗️ The real power of this isn't felt in our definitions, but rather when we make queries. A type that implements an interface doesn't require new query definitions. We can define all of our queries for Shoes, and they will also apply to Sneakers.
🤔 Think of Javascript Class constructors and how they can extend functionality from a parent class. This seems to work in a similar fashion.
❗️NOTE: You can not query an interface directly, a Shoe in our current example will always resolver to either a Sneaker or a Boot.
Interface Resolver Types
⚠️ We'll need to teach our resolvers how to determine whether they are resolving to a boot or a sneaker in the above use case. We even get a warning in the console that instructs us accordingly:
Type "Shoe" is missing a "__resolveType" resolver. Pass false into "resolverValidationOptions.requireResolversForResolveType" to disable this warning.
server running on port 4000
- note that the server is still running and didn't fail to start.
In order to resolve our shoe type, we'll need to create a custom resolver with the __resolveType method:
const resolvers = {
/*...*/
Shoe: {
__resolveType(shoe) {
if(shoe.sport) return 'Sneaker'
return 'Boot'
}
}
}

⚠️ If there is an error in this setup, you'll likely see the following error:
Abstract type X must resolve to an Object type at runtime Either the X type should provide a \"resolveType\" function or each possible type should provide an \"isTypeOf\" function."

Querying for Type specific fields of an Interface
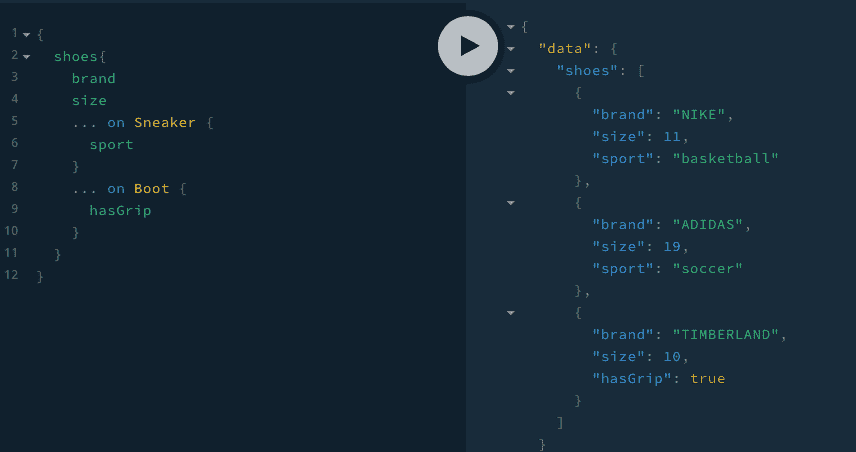
- We also get access to the typeName in our queries:

*☝️NOTE: * it seems that the __typename seems to only run once, even though we've defined it for the shoe itself and then for each type of shoe. This is because graphql de-dupes our fields automatically.
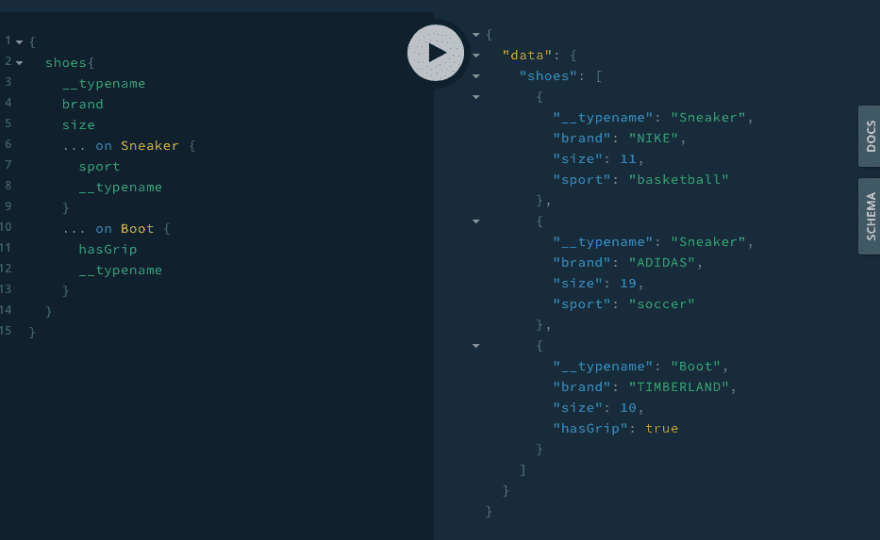
Unions
Like interfaces, but without any defined common fields amongst the Types. Useful when you need to access more than one disjoint Type from Query, like a search.
The
Uniontype indicates that a field can return more than one object type, but doesn't define specific fields itself
type Sneaker {
brand: ShoeType!
size: Int!
sport: String!
}
type Boot{
brand: ShoeType!
size: Int!
hasGrip: Boolean!
}
union FootWear = Sneaker | Boot
FootWear: {
// required to resolve the type of the interface:
__resolveType(shoe) {
// returns the type name as a string
if (shoe.sport) return "Sneaker";
return "Boot";
},
},

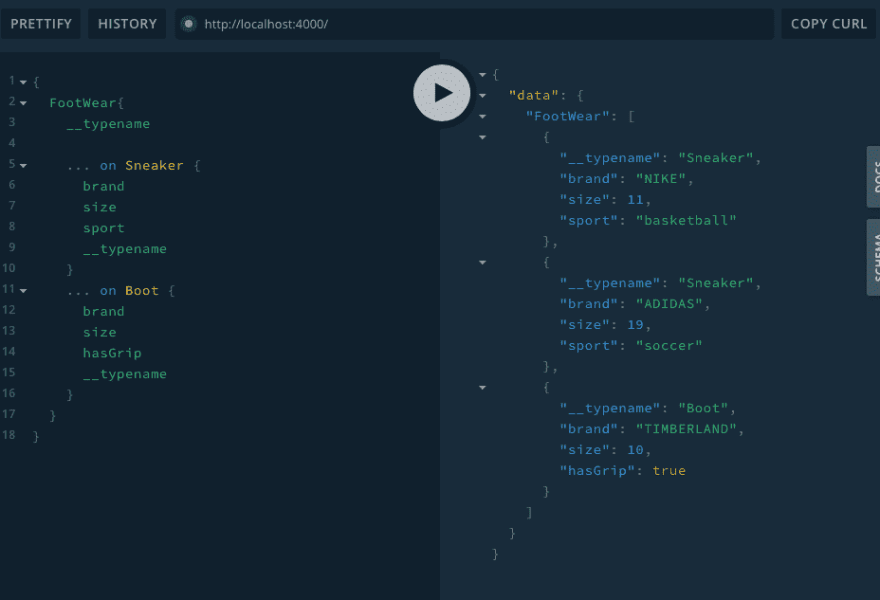
Combining Interfaces and Unions:
interface Shoe {
brand: ShoeType!
size: Int!
}
type Sneaker implements Shoe {
brand: ShoeType!
size: Int!
sport: String!
}
type Boot implements Shoe {
brand: ShoeType!
size: Int!
hasGrip: Boolean!
}
union FootWear = Sneaker | Boot
FootWear: {
// required to resolve the type of the interface:
__resolveType(shoe) {
// returns the type name as a string
if (shoe.sport) return "Sneaker";
return "Boot";
},
},
Shoe: {
// required to resolve the type of the interface:
__resolveType(shoe) {
// returns the type name as a string
if (shoe.sport) return "Sneaker";
return "Boot";
},
},
Relationships
Thinking in Graphs
Your API is no longer a predefined list of operations that always return the same shapes. Instead, your API is a set of Nodes that know how to resolve themselves and contain links to toher related Nodes. This allows a client to ask for Nodes and then follow those links to get related Nodes.
Adding Relationships
- Add a Type as a field value on another Type
- Create resolvers for those fields on the Type
First we'll update our data, so that we can grab a reference to users who own our shoes:
const shoes = [
// 🚧
{ brand: "NIKE", size: "11", sport: "basketball", user: 1 },
{ brand: "ADIDAS", size: "19", sport: "soccer", user: 2 },
{ brand: "TIMBERLAND", size: "10", hasGrip: true, user: 3 },
];
Next let's update our current schema:
type User { # describes the shape of the User type
# non-nullable fields ('!')
id: Int! # 🚧
email: String!
avatar: String!
shoes: [Shoe]! # 🚧
}
interface Shoe {
brand: ShoeType!
size: Int!
user: User!
}
type Sneaker implements Shoe {
brand: ShoeType!
size: Int!
user: User!
sport: String!
}
type Boot implements Shoe {
brand: ShoeType!
size: Int!
user: User!
hasGrip: Boolean!
}
union FootWear = Sneaker | Boot
const resolvers = {
/*...*/
Shoe: {
// required to resolve the type of the interface:
__resolveType(shoe) {
// returns the type name as a string
if (shoe.sport) return "Sneaker";
return "Boot";
},
user(shoe) {
return user;
},
},
Sneaker: {
user(shoe) {
return user;
},
},
Boot: {
user(shoe) {
return user;
},
},
}
Note that we were not able to create the resolver for user on the Abstract Object (interface) Shoe. Instead we must individually resolve each of the types that implement our interface, in this case: "Boot" and "Sneaker"

We can also query the interface alone:

We can also use our new definitions to do other relational queries by adding a User resolver to help resolve shoes that belong to this specific user:
const resolvers = {
/*...*/
User: {
shoes(user) {
return shoes.filter((shoe) => shoe.user !== user.id);
},
},
/*...*/
}
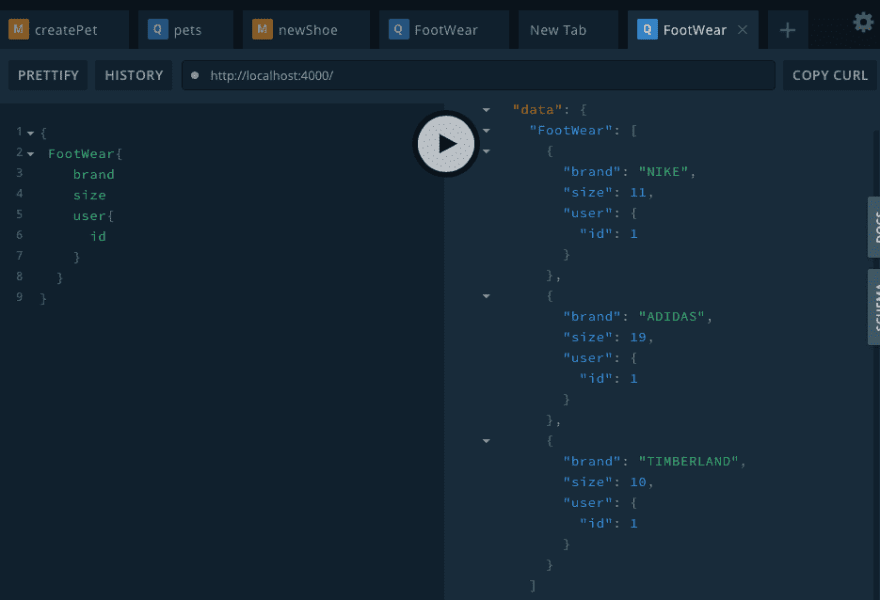
⚠️ This type of logic causes endless recursion:

Challenge
- A pet should have an associated user
- A user should also contain an array of pets.
Create resolvers to handle the related data
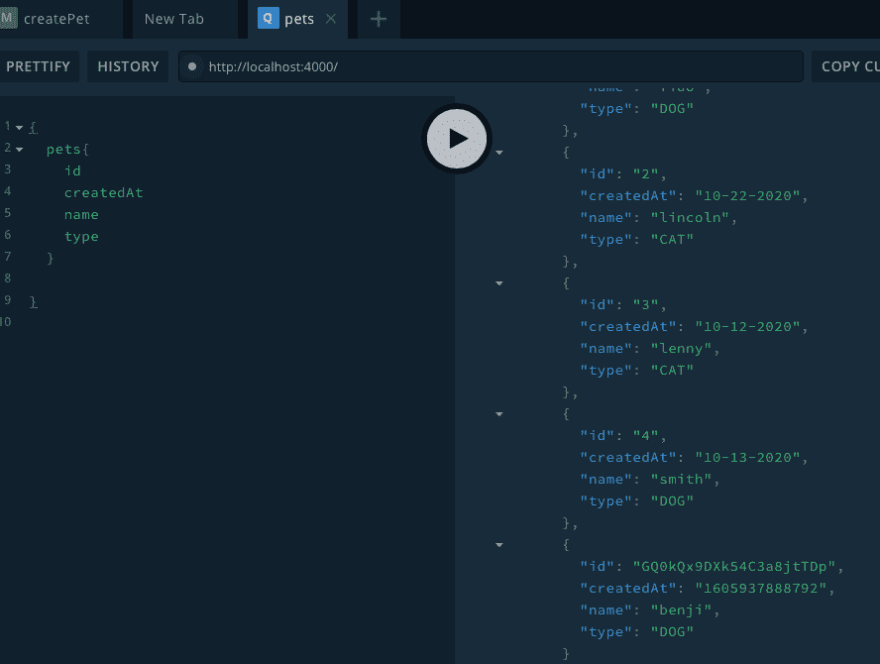
First, we'll want to add the user field to our pet instances in the db:
{
"id": 1,
"createdAt": "10-24-2020",
"name": "fido",
"type": "DOG",
"user": "jBWMVGjm50l6LGwepDoty"
},
Nextwe'll need to ensure we expose our current user to our context:
// api/src/server.js
context() {
const user = models.User.findOne({ username: "frontendmaster" });
return { models, db, user };
},
Next we can update our schema:
type User {
id: String!
username: String!
pets: [Pet]! # 🚧
}
type Pet {
id: String!
createdAt: String!
name: String!
type: String!
user: User! # 🚧
}
And lastly we'll need to add resolvers for each type to resolver to the correct data for our new fields:
Pet: {
owner(pet, __, { models }) {
// normally we'd have to find the matching user, but we only have one user in the db
return models.User.findOne();
},
},
User: {
pets(_, __, { models, user }) {
// return models.Pet.findMany({ user: user.id });
return models.Pet.findMany();
},
},


Client Side Config
As we saw in the server-side section queries and mutations get defined on the server-side of any graphql application, but from the front end we then have to execute those queries and mutations to interact wtih our data.

Operation Names
Unique names for your client side Query and Mutation operations. Used for client-side caching, indexing inside of tools like GraphQl Playground.. Like naming your functions in JS vs keeping them anonymous.
Variables with operations
Operations can define arugments, very much like a function in most programming languages. Those variables can then be passed to query/mutation calls inside the operation as arguments. Variables are expected to be given at run time during operation execution from your client.
query AllCharacters { characters(page: 2) { results { name } } }I this query we're using a query variable called page, and we've currently hard coded it with the value '2', to help us target the second page of characters from this api.
We can also use query variables in graphql playgorund to help us test our queries that accept certain variable arguments:
query AllCharacters($page: Int) { characters(page: $page) { results { name } } }In this example we've created a variable called
$pageinstead of head coding it.☝️ NOTE: it is initially defined after the operation name and used in our characters query
query varibles are scoped to the actual operation itself and can be used anywhere inside of them (when applicable):
query AllCharacters($page: Int, $id: String) { characters(page: $page) { results { name (id: $id) } } }

Aliasing Queries and Mutations
Used to rename fields so that they match the shape expected by our clientside application.

- Also an example of a filter operation using query variables
We can also run multiple queries together:

Apollo Client
Encapsulates HTTP logic used to interact with a GraphQL API. Doubles as a client side state management alternative as well (such as: Redux, MobX, etc...).
If your GraphQL API is also an Apollo Server, provies some extra features. Offers a plug-in approach for extending it's capabilities. It's also framework-independent.
☝️ Note that we can use graphql to handle local application state, as an alternative to local state management.
Storing Data from your API
- All nodes (fields returned from a query) are stored flat by an unique ID
- Unique ID is default to .id or ._id, from nodes. You can alter this behavior
- Every node should send an .id or ._id, or none at all.
- Or you can add custom logic to handle the id reference.
Queries in React
Setup Apollo Client
// client/src/client.js
import { ApolloClient } from "apollo-client";
import { InMemoryCache } from "apollo-cache-inmemory";
import { HttpLink } from "apollo-link-http";
import gql from "graphql-tag";
// network interface to access gql server -- link to gql connection
const link = new HttpLink({ uri: "http://localhost:4000" });
// sets up apollos in-memory-caching
const cache = new InMemoryCache();
// client takes the httplink and the cache as an argument
const client = new ApolloClient({ link, cache });
export default client;
Testing External Queries:
// client/src/client.js
const link = new HttpLink({ uri: "https://rickandmortyapi.com/graphql" });
const query = gql`
{
characters {
results {
id
name
}
}
}
`;
client.query({ query }).then((results) => console.log(results));

- Let's update our client uri once again:
// client/client.js
const link = new HttpLink({ uri: "http://localhost:4000" });
- Then we can use this to provide our client to our application:
// client/index.js
import { ApolloProvider } from "@apollo/react-hooks";
import client from "./client";
const Root = () => (
<ApolloProvider client={client}>
<BrowserRouter>
<App />
</BrowserRouter>
</ApolloProvider>
);
With this in place we've now gained access to the Apollo-dev-tools in our browser as well.
This allows us to access our queries, mutations, and cache as well as the GraphiQL interface.

Now we can use the useQuery hook form apollo to help us qeury for our data:
// client/src/pages/Pets.js
export default function Pets() {
const [modal, setModal] = useState(false);
const MY_PETS = gql`
query MyPets {
pets {
id
name
}
}
`;
const { data, loading, error } = useQuery(MY_PETS);
if (loading) return <p>Loading...</p>;
if (error) return `XError! ${error.message}`;
return (
<div className='page pets-page'>
{/*...*/}
<section>
<div className='row'>
<PetsList pets={data.pets} />
</div>
</section>
</div>
);
}
Mutations
mutation CreateAPet ($newPet: NewPetInput!) {
createPet(input: $newPet) {
id
name
type
}
}

Client Side Variables for mutations
// client/src/pages/Pets.js
const NEW_PET = gql`
mutation CreateAPet($newPet: NewPetInput!) {
createPet(input: $newPet) {
id
name
type
}
}
`;
const [createPet, newPet] = useMutation(NEW_PET);
if (loading || newPet.loading) return <Loader />;
if (error || newPet.error)
return `XError! ${error && error.message} ${
newPet.error && newPet.error.message
}`;
const onSubmit = (input) => {
// input contains the values from our form: {name, type}
setModal(false);
createPet({ variables: { newPet: input } });
};

Currently we're able to create a new pet, although our page does not respond to the new data and so we actually have to do a refresh to get the new data.
Why is Cache out of sync?
If you perform a mutation that updates or creates a single node, then apollo will update your cache automatically given the mutation and query have the same fiields and id.
⚠️ Always ty to match the fields on mutations and queries 1to1, this let's us opt into apollo's default caching behavior
This is also why when we create a new pet apollo doesn't refresh the page, because it has never cached that item yet since it was just created. Which is why refreshing does pull down the item.
⚠️ This is also the case when we're deleting

If you perofrm a mutation that updates a node in a list or removes a node, you are responsible for updating any queries referencing that list or node. There are many ways to do this with apollo.
Keeping Cache in Sync
- Refetch matching queries after a mutation
- use update method on mutation (recommended)
- watch queries
Refetch
Refetching enables you to refresh query results in response to a particular user action, as opposed to using a fixed interval.
Update method
const [createPet, newPet] = useMutation(NEW_PET, {
update(cache, { data: { createPet } }) {
const data = cache.readQuery({ query: ALL_PETS });
cache.writeQuery({
query: ALL_PETS,
data: { pets: [createPet, ...data.pets] },
});
},
});
In this approach we're manually handling the caching so that we can run an update using our query, which will allow us to re-load our data after a mutation occurs.
Watch Query
Provide this object to set application-wide default values for options you can provide to the watchQuery, query, and mutate functions.
Note: The useQuery hook uses Apollo Client's watchQuery function. To set defaultOptions when using the useQuery hook, make sure to set them under the defaultOptions.watchQuery property.
const defaultOptions = {
watchQuery: {
fetchPolicy: 'cache-and-network',
errorPolicy: 'ignore',
},
query: {
fetchPolicy: 'network-only',
errorPolicy: 'all',
},
mutate: {
errorPolicy: 'all',
},
};
watchQuery(options)
This watches the cache store of the query according to the options specified and returns an ObservableQuery. We can subscribe to this ObservableQuery and receive updated results through a GraphQL observer when the cache store changes.
NAME / TYPE DESCRIPTION contextanyContext to be passed to link execution chain errorPolicy`"none""ignore" {% raw %} fetchPolicy`"cache-first""network-only" {% raw %} nextFetchPolicyanySpecifies the FetchPolicy to be used after this query has completed. notifyOnNetworkStatusChangeanyWhether or not updates to the network status should trigger next on the observer of this query partialRefetchanyIf true, perform a queryrefetchif the query result is marked as being partial, and the returned data is reset to an empty Object by the Apollo ClientQueryManager(due to a cache miss).pollIntervalanyThe time interval (in milliseconds) on which this query should be refetched from the server. query`DocumentNodeTypedDocumentNode` returnPartialDataanyAllow returning incomplete data from the cache when a larger query cannot be fully satisfied by the cache, instead of returning nothing. variablesTVariablesA map going from variable name to variable value, where the variables are used within the GraphQL query.
Optimistic UI
Your UI does not have to wait until after a mutation operation to update itself. Instead, it anticipates the response from the API and process as if the API call was in sync. The API response replace the generated response. This gives the illusion of your app being really fast.
Optimistic UI is a pattern that you can use to simulate the results of a mutation and update the UI even before receiving a response from the server. Once the response is received from the server, the optimistic result is thrown away and replaced with the actual result.
☝️ Loading Skeletons > Loading Spinners
// client/src/client.js
import { ApolloClient } from "apollo-client";
import { InMemoryCache } from "apollo-cache-inmemory";
import { HttpLink } from "apollo-link-http";
import { ApolloLink } from "apollo-link";
import { setContext } from "apollo-link-context";
import gql from "graphql-tag";
// network interface to access gql server -- link to gql connection
const http = new HttpLink({ uri: "http://localhost:4000" });
// create test for slower networks using apollo:
const delay = setContext(
(request) =>
new Promise((success, fail) => {
setTimeout(() => {
success();
}, 800);
})
);
// combines the usage of httplink && apollo link to a single link reference:
const link = ApolloLink.from([delay, http]);
// sets up apollos in-memory-caching
const cache = new InMemoryCache();
// client takes the httplink (from our custom link) and the cache as an argument
const client = new ApolloClient({ link, cache });
export default client;
here we've simply taken the HttpLink that the client needs to intantiate ApolloClient and added a reference to a delay paramter using setContext from apollo. This allows us to simulate slow network requests, with our given delay parameter.
Now we can use this in our application and we can test our optimistic response setup using the delay we've configured so that the loading states will last longer than normal while in development mode.
// client/src/Pets.js
const onSubmit = (input) => {
setModal(false);
createPet({
variables: { newPet: input },
optimisticResponse: {
// used to render updated ui while graphql syncs db
__typename: "Mutation", // operation type
createPet: {
// matches the resolver name
id: "this-id-does-not-matter-here", // if id is available include -- gets replaced with new data from mutation
__typename: "Pet", // include all expected fields,
// these will be used to populate the data until the actuam mutation occurs/updates.
type: input.type,
name: input.name,
},
},
});
};
optimisticResponseis a property we can set from our mutation's update functions.Since we're taking advantage of the optimistic UI rendering, it's only good practice to remove any loading state handlers.
// ❌ if (loading || newPet.loading) return <Loader />; if (loading) return <Loader />;Remove newPet Loading state to opt out of loading state in favor of optimistic rendering.
☝️ NOTE we removed the loading handler for only our newPet mutation loading state, this is because we're looking to render it optimistically and if were to keep the loading state in place, it would flicker in very quickly as the state of our hook went from loading: true => loading: false.
Client Side Schemas
In addition to managing data from your API, apollo client can also be used to manage local state originating from our front end client side application.
Think of it as an alternative to reach for redux or other state management/machine libraries.
You can create a schema to define that state which allows you to query for that state the same way you query you api for data.
☝️ The approach here is very similar to creating schema for the backend of your application, you'll need the same two things to get started:
typeDefsresolvers
// client/src/client.js
// extend backend types with front-end schema.
const typeDefs = gql`
extend type User {
age: int
}
`
const resolvers = {
User: {
age() {
return 3 // hard-coded repsonse
}
}
}
// ❌ const client = new ApolloClient({ link, cache });
const client = new ApolloClient({ link, cache, resolvers, typeDefs });
Now we can update our query to incorporate our changes:
// client/pages/Pets.js
const ALL_PETS = gql`
query allPets {
pets {
id
type
name
owner {
id
age @client
}
}
}
`;
The
@directive@clienttells apollo that this field gets resolved on the client-side only. It will simply ignore this field for any backend only operations and still allow us to use it on the front end as a piece of local state related to our user.
Fragments
A GraphQL fragment is a reusable part of the query. A GraphQL fragment lets you build multiple fields, and include them in multiple queries.
# fragment ownerInfo for RepositoryOwner fields
fragment ownerInfo on RepositoryOwner {
id
avatarUrl
resourcePath
url
}
// GraphQL Query with fragments used in multiple queries
{
googleRepo: repository(owner: "google", name: "WebFundamentals") {
name
owner {
...ownerInfo //fragment
}
}
facebookRepo: repository(owner: "facebook", name: "react") {
name
owner {
...ownerInfo //fragment
}
}
}
A fragment consists of three unique components:
- Name: This is the unique name of the fragment (each fragment can have its own name)
- TypeName: The type of object the fragment is going to be used on. This indicates which nested object, from the GraphQL schema, this fragment is created on
- Body: The last part is the body of the fragment. The body of the fragment defines the fields that will be queried for
So why are fragments cool within a GrapQL query?
- Reusability – With fragments, you can organize your queries into reusable units
- Caching – GraphQL clients make use of fragments, to provide caching options
// client/src/pages/Pets.js
const PETS_FIELDS = gql`
fragment PetsFields on Pet {
id
name
type
vaccinated
}
`;
// usage:
const ALL_PETS = gql`
query allPets {
pets {
...PetFields
}
}
${PET_FIELDS}
`;
const NEW_PET = gql`
mutation CreateAPet($newPet: NewPetInput!) {
createPet(input: $newPet) {
...PetFields
}
}
${PET_FIELDS}
`;
Challenge:
- Extend Pet Type with new Field: Vaccinated
// client/src/client.js
const typeDefs = gql`
extend type Pet {
vacinated: Boolean!
}
`;
const resolvers = {
Pet: {
vacinated: () => true
}
};
Fragment for pet type
Update fragment to exist for both ALL_PETS query and NEW_PET mutation
Hey everyone, I'm Gaurang, a full-stack developer that is constantly learning and building in public. I love that I was able to change my career at such a late stage in life all by learning online with so many different resources. I generate content to reinforce what I'm learning and to help others like me in the future.
If you enjoyed my content, please feel free to connect with me wherever you spend your time online.





Latest comments (0)