
Introduction
If we want to setup a blog, there are many options, for enterprise level, you can use WordPress, which helps you to deliver a blog pretty fast, or you can build it using something like Hexo, which has pretty much everything built-in, you only need to tune config and write content in markdown and host that on Heroku or Vercel, Netllify. Or, you can start everything from frontend to backend and host it on your own server, and this is what this blog will talk about.
The previous blog of my current company was hosted on WordPress, which costs and under a different domain from what we want. Our expected domain is xxx.page, and it was on xxx.app domain, which is on 2 different servers, in order to migrate it, we will need to install PHP language and bunch of WordPress plugins, some of them could cause severe security issues.
To avoid such question and extend flexibility of our company blog for better SEO purpose, we decide to build it using Nextjs and Strapi, a headless content management system (CMS) and host that on the xxx.page server.
To do that, you will have to refer to docs first:
from basic introduction we can understand what we can do with this suite:
Nextjs provides intelligent default setup for SSR, SSG purpose, along with default optimization function, the default Rust-based compiler provides 5x times faster than babel
Strapi provides a built-in UI dashboard that allows user to do everything you want with content, and since it is a Node project, you can add more configuration to it, like image compression function, database connection, email channel, etc.
the result blog for Desty.app
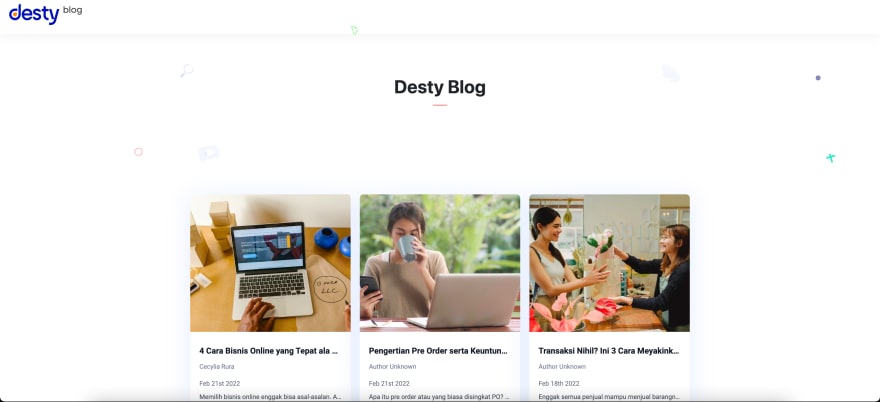
Strapi as backend

In this case, Strapi is the backend where content is stored. We decide to install docker image of Strapi directly on the server, and if more config needed to be added in code, we can do it in server directly.
Doing that can actually save lot of trouble, there is no need for writing code in Strapi to connect to database, since we store files in server directly, like WordPress, and else functions can all be done directly on its dashboard.
You can choose other headless CMS, well, Jamstack's headless cms section is a good place to offer those options
after hosting your Strapi project and make couple content types and publish, for example, articles or posts, or else, you can access to the json data by checking the url xxx.xxx/[content type name], for example, mine is xxx.xxx/articles and xxx.xxx/categories.
in this case the client side can fetch data directly, or if you want your data private, you can setup authentication in Strapi's code and change the role of public access to only authenticated users, and you can define authenticated users in UI dashboard directly.
Nextjs as frontend

Nextjs is the frontend, and we use static generator to do so, we will use Jenkins to do a daily trigger everyday 4:00pm to build the entire blog so everything is included in the build, and thus providing better user interaction since it is fast.
First, lets take a look of hosted Strapi:

after clicking the open administrator and signup and login, you will see:

The blank Strapi project should not have those collection types on the left side, and you can feel free to build whatever content type you want in Content-Types Builder, feel free to explore Strapi doc here
Here I will demonstrate how to do the client side:
- start a Nextjs project by using
npx create-next-app@latest
# or
yarn create next-app
- define the basic layout
well, this is not strictly required in the first place, you can extract layout logic out later, along with some css files
- define routes
the basic blog route will be
- /blog --> root
- /blog/category/[name] --> category name, displays articles under that category
- /blog/[slug] --> article page with unique slug
- data fetching
you can define the data fetching in lib folder, naming a file like api.js
import axios from "axios";
async function getStrapiAuthToken() {
const { data } = await axios.post(
process.env.NEXT_PUBLIC_STRAPI_API_URL + "/auth/local",
{
identifier: process.env.STRAPI_IDENTIFIER,
password: process.env.STRAPI_PASSWORD,
}
);
return data.jwt;
}
export function getStrapiURL(path = "") {
const p = `${process.env.NEXT_PUBLIC_STRAPI_API_URL}${path}`;
return p;
}
// Helper to make GET requests to Strapi
export async function fetchAPI(path) {
const requestUrl = getStrapiURL(path);
const { data } = await axios.get(requestUrl);
return data.reverse();
}
then you can fetch articles using this method along with Nextjs's provided data fetching methods such as getStaticProps and getStaticPaths or getServerSideProps, for details, check this page
one example of fetching articles would be
// for root path '/', getStaticPaths cannot be used, // only use it in places like /blog/[slug]
export async function getStaticPaths() {
const articles = await fetchAPI("/articles");
return {
paths: articles.map((article) => ({
params: {
slug: article.slug,
},
})),
fallback: "blocking",
};
}
// this is required
export async function getStaticProps({ params }) {
const articles = await fetchAPI(`/articles?slug=${params.slug}`);
const categories = await fetchAPI("/categories");
return {
props: { article: articles[0], categories },
revalidate: 10,
};
}
the default gives only limited number of entries that can be fetched, you can add /articles?_limit=-1 to replace /articles to access unlimited number of entries.
Right now we have a blog that requires building every time, but if we update like 50 blogs per day, or like Twitter it may have up to 500M new tweets per day, you will have to define skeleton and let articles or tweets to be statically generated now time, if they are not included in the build. this can be explained later as I am also working on it.
SEO and Optimization
till here we have not done well on SEO and optimization, for there are lots of things to optimize.
I would recommend using Google's PageSpeed Insights, or easier, using Google's lighthouse tool which you just install as google plugin and can run it by single click
There are couple things we need to do better here
- optimize data fetching
- use next-gen image format (AVIF or WebP)
- details such as adding lang to html, having alt in
<img />tag, etc.
you can check how lighthouse or PageSpeed index does the calculation, and then you can optimize based on them





Top comments (0)