Hey everyone, I am a Senior Data Engineer (MLOps) at FreshBooks. We are currently working on transitioning to fully automated end-to-end ML pipelines. And I want to share some ideas, solutions, and challenges we are dealing with during this journey.
A starting point
We are already building training pipelines with Vertex AI.
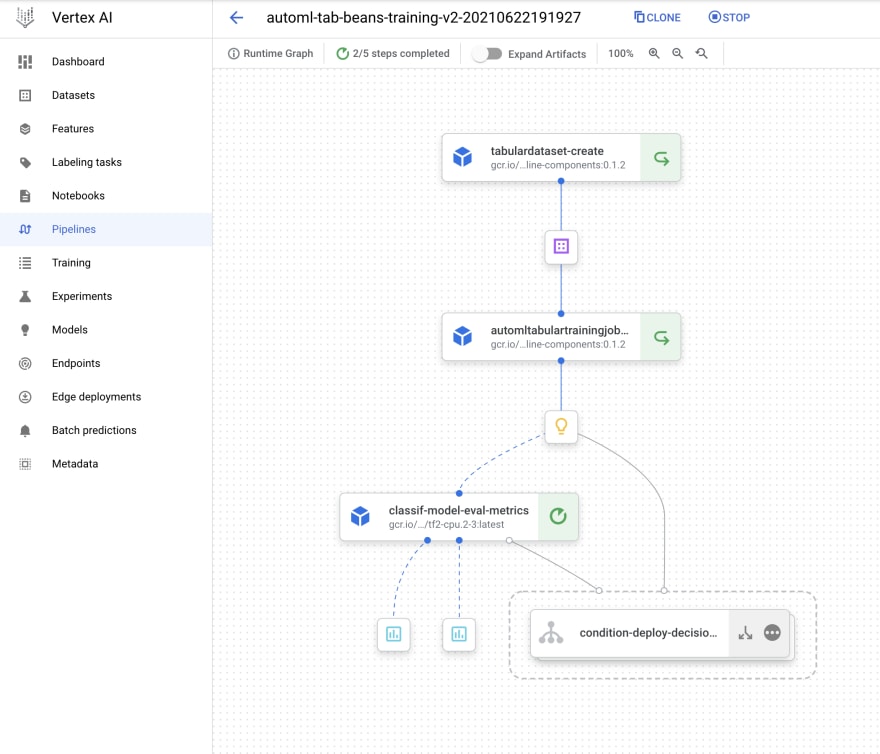
Example of Vertex AI pipeline from the GC blog article
That works pretty well. We can include into our pipelines data preparation steps, train several models and choose the best one, dump metadata, send notifications, etc. The Vertex AI pipelines are great themselves, but most of the processes during development and maintaining them are manual.
What's the issue here? Say we already have not just a couple of pipelines but a couple dozen. We probably already have a list of our favourite components which are used in most pipelines and say a bug was fixed in one of them. In this scenario we would need to rebuild all the related pipelines, check them locally, then deploy and check them in a real environment. What if we forgot to rebuild something? Or part of a pipeline was broken after the update? Things become trickier... In addition, all these routine operations take some time.
How can we do better?
Okay, we definitely need some automation here.
Illustration of CI/CD from synopsys
CI/CD practices are widely used in typical software development. And we can use it in our case as well.
To start doing it we need:
- Some CI/CD tool, to build and run all the processes. Yeah, we can write some custom scripts for this goal, but there are a lot of stable solutions that we can use.
- Automated tests, to check if everything works fine. Spreading changes without quality control is probably not a good idea.
GitHub Actions
GitHub Actions was a good choice for us since we already store all sources in GitHub, making it easy to start working with. There is secret storage and a marketplace with prebuilt actions. You do not need to set up any infrastructure, everything is provided by GitHub for free (with limitations). Alongside that is a mature modern tool that provides many ways of customization, like self-hosted runners and reusable workflows.
Tests
What about tests? Let's firstly answer what we want to test. So, a Vertex AI pipeline is a set of components organized as a DAG. Each component can be presented as a small containerized application. We can test such applications as any other software with Unit tests. Also, we can build a simple isolated pipeline(s) just for one target component to be sure it is configured and built well, and works in the Vertex AI environment. These can be our integration tests for components.
For the pipeline itself, we can add some components inside, to do ML-specific things like model validation. When we run the pipeline in a test environment and all stages of the pipeline are successfully done we can consider it works properly. It will be the integration tests for the pipelines.
Repository structure
There is one more thing we should touch on before writing the CI/CD scripts and that is the organization of code in our repository.
pipelines/
pipeline1.yaml
...
components/
component1/
src/
...
tests/
unit/
...
integration/
test.yaml
config.yaml
There is a folder with pipeline specifications and a folder with components. Each component contains source files, tests, and a configuration.
We also built an MLOps Framework to simplify some routines, that is why you see yaml files instead of the usual json. We probably will publish another article about it.
CI/CD workflows
Looks like everything is ready to bring GitHub Actions to the scene.
To build CI/CD in our case we need to be able:
- run unit tests for a component
- build a component
- build a pipeline
- run pipelines in different environments
In order to not copy-paste almost the same code, we can use the reusable workflows feature of GHA.
test_component.yml - runs unit tests for a component specified by input parameters
name: Test component
on:
# the section defines the workflow as reusable and describes the input parameters
workflow_call:
inputs:
tests_path:
required: true
type: string
jobs:
tests:
# run the job on a fresh ubuntu instance
runs-on: ubuntu-latest
name: "Run tests for the component"
steps:
# get the repo to the instance
- name: Checkout
uses: actions/checkout@v3
# install requirements for the framework
- name: Install python requirements
run: make install
# tun tests using the path to the tests from input parameters
- name: Run tests
run: make test ${{ inputs.tests_path }}
build_component.yml - builds a component specified by input parameters
name: Build component
on:
# the section defines the workflow as reusable and describes the input parameters
workflow_call:
inputs:
component_name:
required: true
type: string
secrets:
WORKLOAD_IDENTITY_PROVIDER:
required: true
SERVICE_ACCOUNT:
required: true
jobs:
build:
# run the job on a fresh ubuntu instance
runs-on: ubuntu-latest
name: "Build the component"
# set permissions necessary for google-github-actions/auth
permissions:
contents: "read"
id-token: "write"
steps:
# get the repo to the instance
- name: Checkout
uses: actions/checkout@v3
# Install docker
- name: Install docker
run: make install_docker
# auth to GCP with workload_identity
# also create credentials_file to use it in the next steps
- id: "auth"
name: "Authenticate to Google Cloud"
uses: "google-github-actions/auth@v0"
with:
token_format: "access_token"
workload_identity_provider: ${{ secrets.WORKLOAD_IDENTITY_PROVIDER }}
service_account: ${{ secrets.SERVICE_ACCOUNT }}
create_credentials_file: true
export_environment_variables: true
# login to GCR with the token from the previous step
- name: Login to GCR
uses: docker/login-action@v2
with:
registry: gcr.io
username: oauth2accesstoken
password: ${{ steps.auth.outputs.access_token }}
# install python requirements
- name: Install requirements
run: make install
# run build component command with input parameters
- name: Build the component
run: make build component ${{ inputs.component_name }}
Since we build components as docker images we have to install docker on the runner and login to GCR. All necessary credentials are stored in the repository secrets.
run_pipeline.yml - run a pipeline specified by input parameters
name: Run pipeline
on:
# the section defines the workflow as reusable and describes the input parameters
workflow_call:
inputs:
pipeline_name:
required: true
type: string
secrets:
WORKLOAD_IDENTITY_PROVIDER:
required: true
SERVICE_ACCOUNT:
required: true
jobs:
build:
# run the job on a fresh ubuntu instance
runs-on: ubuntu-latest
name: "Run pipeline"
# set permissions necessary for google-github-actions/auth
permissions:
contents: "read"
id-token: "write"
steps:
# get the repo to the instance
- name: Checkout
uses: actions/checkout@v3
# auth to GCP with workload_identity
# also create credentials_file and export it to environment variables in order to use it in the next steps
- id: "auth"
name: "Authenticate to Google Cloud"
uses: "google-github-actions/auth@v0"
with:
token_format: "access_token"
workload_identity_provider: ${{ secrets.WORKLOAD_IDENTITY_PROVIDER }}
service_account: ${{ secrets.SERVICE_ACCOUNT }}
create_credentials_file: true
export_environment_variables: true
# install python requirements for framework
- name: Install python dependecies
run: make install
# run "run pipeline" command with input parameters
- name: Run pipeline
run: make run ${{ inputs.pipeline_name }}
build_pipeline.yml looks almost the same so we can skip it and move further.
Great, we have all building blocks that do the main operations. Now we just need to use them in order to build and run pipelines when changes happen. Let's use pipeline1 and component1 from the example above.
build_pipeline1.yml - builds and tests the pipeline1 when it is changed
name: Build pipeline1
on:
# the workflow can be run manually
workflow_dispatch:
# the workflow will be run automatically when a PR is opened to the main branch
# or changes to the PR related to the pipeline are pushed
pull_request:
types: [opened, synchronize, reopened]
branches:
- "main"
paths:
- "pipelines/pipeline1.yaml"
jobs:
build:
# call build_pipeline workflow with target parameters
uses: ./.github/workflows/build_pipeline.yml
with:
pipeline_name: "pipeline1"
secrets:
WORKLOAD_IDENTITY_PROVIDER: ${{ secrets.DEV_WORKLOAD_IDENTITY_PROVIDER }}
SERVICE_ACCOUNT: ${{ secrets.DEV_SERVICE_ACCOUNT }}
tests:
# call run_pipeline workflow with target parameters
# to check it in dev env
# this step requires the previous step to be done successfully
needs: build
uses: ./.github/workflows/run_pipeline.yml
with:
pipeline_name: "pipeline1"
secrets:
WORKLOAD_IDENTITY_PROVIDER: ${{ secrets.DEV_WORKLOAD_IDENTITY_PROVIDER }}
SERVICE_ACCOUNT: ${{ secrets.DEV_SERVICE_ACCOUNT }}
build_component1.yml - builds (and tests) the component1 component when it is changed and builds the related pipeline after this
name: Build component1
on:
# the workflow can be run manually
workflow_dispatch:
# the workflow will be run automatically when a PR is opened to the main branch
# or changes to the PR related to the component1 are pushed
pull_request:
types: [opened, synchronize, reopened]
branches:
- "main"
paths:
- "components/component1/**"
jobs:
tests:
# call test_component workflow with target parameters
uses: ./.github/workflows/test_component.yml
with:
tests_path: components/component1/tests
build:
# call build_component workflow with target parameters
# this step requires the previous step to be done successfully
needs: tests
uses: ./.github/workflows/build_component.yml
with:
component_name: "component1"
secrets:
WORKLOAD_IDENTITY_PROVIDER: ${{ secrets.DEV_WORKLOAD_IDENTITY_PROVIDER }}
SERVICE_ACCOUNT: ${{ secrets.DEV_SERVICE_ACCOUNT }}
integration-tests:
# call run_pipeline workflow with target parameters
# to check the component in dev env
# this step requires the previous step to be done successfully
needs: build
uses: ./.github/workflows/run_pipeline.yml
with:
pipeline_name: "component1-test"
secrets:
WORKLOAD_IDENTITY_PROVIDER: ${{ secrets.DEV_WORKLOAD_IDENTITY_PROVIDER }}
SERVICE_ACCOUNT: ${{ secrets.DEV_SERVICE_ACCOUNT }}
build-pipeline1:
# call build_pipeline workflow with target parameters
# this step requires the previous step to be done successfully
needs: integration-tests
uses: ./.github/workflows/build_pipeline.yml
with:
pipeline_name: "pipeline1"
secrets:
WORKLOAD_IDENTITY_PROVIDER: ${{ secrets.DEV_WORKLOAD_IDENTITY_PROVIDER }}
SERVICE_ACCOUNT: ${{ secrets.DEV_SERVICE_ACCOUNT }}
test-pipeline1:
# call run_pipeline workflow with target parameters
# to check it in dev env
# this step requires the previous step to be done successfully
needs: build-pipeline1
uses: ./.github/workflows/run_pipeline.yml
with:
pipeline_name: "pipeline1"
secrets:
WORKLOAD_IDENTITY_PROVIDER: ${{ secrets.DEV_WORKLOAD_IDENTITY_PROVIDER }}
SERVICE_ACCOUNT: ${{ secrets.DEV_SERVICE_ACCOUNT }}
Conclusion
That is it. When changes come the related workflows will be run by GHA. Tests run, components and pipelines rebuild and if everything goes well we will be able to merge the Pull Request and update these changes to Production by running these workflows manually or adding another step to trigger it automatically.
But, are we happy now?






Top comments (0)