
Hello 👋,
Recently I took the time to reflect on my last two years at MyUnisoft. I finally told myself that I wasn't writing enough about the difficulties we faced with my team 😊.
Today I decided to write an article about our transition to TypeORM. A choice we made over a year ago with my colleague Alexandre MALAJ who joined a few months after me.
We'll see why and how this choice allowed us to enhance the overall DX for my team 🚀. And that in the end it was a lot of trade-offs, and obviously, far from a perfect solution too.
🔍 The problem
At MyUnisoft we work with a PostgreSQL database with static and dynamic schema (each client is isolated in one schema). And uniquely without counting the duplication of the schemas we have about 500 tables.
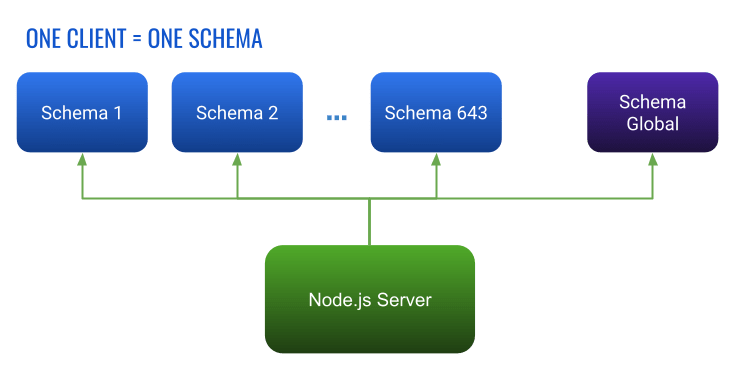
The Node.js stack was split into several services coupled to the database (or to third-party services for some of them). Developers before us were writing raw queries and there were no unit or functional tests 😬. When I took over as lead it was hell to succeed in testing each service properly. Among the painful things 😱:
- strong coupling.
- heavy docker configuration
- complexity to generate business data for our tests.
We had to find a solution to improve and secure our developments while iterating on production releases 😵.
Decentralizing with events wasn’t a possibility since of existing codes and dependencies (and we had no DevOps at the time).
💡 The solution
We started thinking about creating an internal package that would serve as an abstraction to interact with the database. We don't want to go for microservices 😉, so having a package that centralizes all this seems like a good compromise for us.
Among our main objectives:
- Generate a compliant database locally or on Docker.
- Easily generate fake data.
- Built to allow us to carry out our functional and business tests.
- Centralized code review (which also allows us to track changes more easily)
We also had ideas like building a schema in a running database (which could be used for partner API testing and sandboxing).
The question remained whether we should continue writing raw queries or not 😨. I'm not necessarily a big fan of ORMs, but we had a diversity of tables and requirements that made the writing of raw queries complicated at time.
We looked at the different solutions in the ecosystem by checking our constraints with the schemas. After must research, we concluded that TypeORM was viable (other ORM had critical issues).
Far from perfect, but we had to give it a try 💃!
Note: with hindsight, we are now also very interested in Massive.js. This could have been one of our choices.
🐥 Let the story begin
👶 Baby steps
My colleague Alexandre spent several months migrating the database on TypeORM 😮. I helped him by reviewing each table and relations.
We did not opt for a migration script at the time (for us the choice was still too vague).
We have made a gource to illustrate our work:
One of the problems we quickly encountered was that it was not possible to use the ActiveRecord pattern with dynamic schemas 😭. However this is ok for static schema because you can define them with the @Entity decorator.
@Entity({ schema: "sch_interglobal" })
export class JefactureWebhook extends BaseEntity {}
The management of datasources (connection) by schema/client was a bit infernal. We created our abstraction on top of TypeORM to handle all this properly and regarding our schema initialization requirements.
One of our encounters being quite complicated has been to clone a schema when we add a new client on the fly 🐝(that's something we do in our tests, in the authentication service for example).
We were able to achieve this by using the @EventSubscriber decorator on a static table we use to register new customers’ information.
@EventSubscriber()
export default class Sub_GroupeMembre {
listenTo() {
return Entities.schInterglobal.GroupeMembre;
}
async afterInsert(event: UpdateEvent) {
const { idGroupeMembre } = event.entity!;
const queryManager = datasources.get("default")!;
await queryManager.query(
`SELECT clone_schema('sch1', 'sch${idGroupeMembre}')`
);
const connection = await (new DataSource({})).initialize();
datasources.set(`sch${idGroupeMembre}`, connection);
}
}
The tricky part was to build an SQL script to properly clone a schema with all tables, relations, foreign keys etc.. But after many difficulties we still managed to get out of it 😅.
📜 Blueprints
When I started this project I was inspired by Lucid which is the ORM of the Adonis.js framework.
By the way, Lucid was one of our choices, but like many of Harminder's packages, it is sometimes difficult to use them outside of Adonis (which is not a criticism, it is sometimes understandable when the goal is to build a great DX for a framework).
But I was quite a fan of Lucid's factory API so we built an equivalent with TypeORM that we called "Blueprint".
Here is an example of a blueprint:
new Blueprint<IConnectorLogs>(ConnectorLogsEntity, (faker) => {
return {
severity: faker.helpers.arrayElement(
Object.values(connectorLogSeverities)
),
message: faker.lorem.sentence(5),
public: faker.datatype.boolean(),
requestId: faker.datatype.uuid(),
readedAt: null,
createdAt: faker.date.past(),
thirdPartyId: String(faker.datatype.number({
min: 1, max: 10
})),
idSociete: null
};
});
The callback includes the faker lib as well as internal custom functions to generate accounting data. You can use this blueprint to generate data like this:
const user = await Blueprints.sch.ConnectorLogs
.merge({ readedAt: new Date() })
.create();
The API is similar but it appears our objectives and TypeORM forced us to make different choices.
ES6 Proxy usage
You may have noticed but something is weird with this API. Every time you hit Blueprints.sch it triggers an ES6 proxy trap that will return a new instance of a given Blueprint.
It was quite satisfying for me to manage to use a Proxy for a real need and at the same time manage to return the right type with TypeScript.
import * as schBlueprints from "./sch/index";
import { Blueprint, EntityBlueprint } from "../blueprint";
// CONSTANTS
const kProxyHandler = {
get(obj: any, prop: any) {
return prop in obj ? obj[prop].build() : null;
}
};
type EmulateBlueprint<T> = T extends Blueprint<infer E, infer S> ?
EntityBlueprint<E, S> : never;
type DeepEmulateBlueprint<Blueprints> = {
[name in keyof Blueprints]: EmulateBlueprint<Blueprints[name]>;
}
export const sch = new Proxy(
schBlueprints, kProxyHandler
) as DeepEmulateBlueprint<typeof schBlueprints>;
📟 Seeder
We worked from the beginning of the project to build a relatively simple seeding API. The idea was mainly to be able to generate the static data required for our services to work properly.
Here's an example of one simple seed script that generates static data with a blueprint:
export default async function run(options: SeederRunOptions) {
const { seeder } = options;
await seeder.lock("sch_global.profil");
await sch.PersPhysique
.with("doubleAuthRecoveryCodes", 6)
.createMany(10);
seeder.emit("loadedTable", tableName);
}
When we generate a new database locally or in Docker we can see the execution of all the seeds:

🌀 Docker and testcontainers
When Tony Gorez was still working with us at MyUnisoft he was one of the first to work around how we can set up our tests inside a Docker and run them in our GitLab CI.
The execution of our tests was relatively long (time to build the Docker etc). That's when he told us about something a friend had recommended to him: testcontainers for Node.js.
Once set up but what a magical feeling... The execution of our tests was faster by a ratio of 4x. Tony has been a great help and his work has allowed us to build the foundation of the tests for our services.
On my side I worked on an internal abstraction allowing everyone not to lose time on setup:
require("dotenv").config();
const testcontainers = require("@myunisoft/testcontainers");
module.exports = async function globalSetup() {
await testcontainers.start({
containers: new Set(["postgres", "redis"]),
pgInitOptions: {
seedsOptions: {
tables: [
"sch_interglobal/groupeMembre",
"sch_global/thirdPartyApiCategory"
]
}
}
});
};
📦 Difficulties with a package 😱
Not everything in the process goes smoothly 😕. In the beginning, it was really difficult to manage the versioning. We used to use npm link a lot to work with our local projects but it was far from perfect (it was more like hell 😈).
And by the way, you have to be very careful with everything related to NPM peerDependencies (especially with TypeScript). If you use a version of typeorm in the package, you necessarily must use the same one in the service otherwise you will have problems with types that do not match.
"peerDependencies": {
"@myunisoft/postgre-installer": "^1.12.1"
}
We had the same issue with our internal Fastify plugin. It cost us a few days sometimes the time to understand that we had screwed up well on the subject 🙈.
In the end, after some stabilizations, we could release new versions very quickly.
I'm not necessarily completely satisfied with the DX on this subject at the moment and I'm thinking of improving it with automatic releases using our commits.
Others APIs
I couldn't even cover everything because this project is so large. For example, we have a snapshot API that allows us to save and delete data during our tests...
Speaking of tests, it is always difficult to give you examples without being boring. But there too the work was colossal.
I would like to underline the work of Cédric Lionnet who has always been at the forefront when it came to solidifying our tests.
💸 Hard work pays off
After one year of hard work the project is starting to be actively used by the whole team across all HTTP services 😍. Everyone starts to actively contribute (and a dozen developers on a project is a pretty interesting strike force ⚡).
Sure we had a lot of issues but we managed to solve them one by one 💪 (I'm not even talking about the migration to TypeORM 3.x 😭).
But thanks to our effort, we are finally able to significantly improve the testing within our Node.js services. We can also start to work in localhost whereas before, developers used remote environments.
In two years we have managed to recreate a healthy development environment with good practices and unit and functional testing on almost all our projects.
📢 My take on TypeORM
If I were in the same situation tomorrow I would probably try another way/solution (like Massive.js). For example, TypeORM poor performance will probably be a topic in the future for my team.
As I said at the beginning, I'm not a fan of ORMs and in the context of personal projects, I do without them almost all the time.
However, I must admit that we succeeded with TypeORM and that the result is not too bad either. There is probably no silver bullet 🤷.
🙇 Conclusion
Many engineers would have given up at the beginning thinking that it would not be worth the energy to fight 😰.
It's a bit simple to always want to start from scratch 😝. For me it was a challenge, to face reality which is sometimes hard to accept and forces us to make different choices 😉.
It was also a great team effort with a lot of trusts 👯. We had invested a lot and as a lead I was afraid I had made the wrong choice. But with Alexandre it is always a pleasure to see that today all this pays off.
I'm not quoting everyone but thanks to those who actively helped and worked on the project especially in the early stage.
Thanks for reading and as usual see you soon for a new article 😘




Oldest comments (3)
This is impressive usage of TypeORM. Have you tried e.g. MikroORM or Prisma?
What do you mean by viable? TypeORM is often known as slowly developed and poorly maintained [1] [2]
Prisma does not have great PostgreSQL schema support. MikroORM at the time we started had also major issues with schemas (most of them has been solved since in 4.x and 5.x). I looked into it recently and there are concerns when you'r not dealing static and know schemas from the start.
There is also probably debate round what's right with the usage of schema on PostgreSQL (however in my case I had no choice from the beginning ¯_(ツ)_/¯). From my experience I would argue that requesting dynamic schemas is a bad idea.
TypeORM is still maintained (sure compared to Mikro it's quite ridiculous.. but really no big deal). And yes performance is going to be a major issue for us at some point (mostly around memory usage and also cold start for testing).
Currently our services are so powerful that they often have to be restricted. So the gains for my team were not on performance improvement.
Thanks for the reply. Glad you found right tool :)