Indexing is a way to improve reading performance, but it also makes writing performance worse, so consider using indexes in your application based on your use cases.
To demonstrate, I will use an orders table with 10 million records:
create table orders (
id serial primary key,
total integer, -- unit: usd
user_id integer,
created_at date
);
Then generate:
total: random number in range (1 - 10k)
user_id: random number in range (1 - 100k)
created_at: random date in range (2002 - 2022) (20 years)
The orders table should look like this:
id | total | user_id | created_at
----+-------+---------+------------
1 | 7492 | 9968 | 2021-03-20
2 | 3084 | 81839 | 2008-03-20
3 | 3523 | 85845 | 2018-12-22
...
Without index:
Let's use explain analyze to see the query plan for this query:
explain analyze select sum(total) from orders
where extract(year from created_at) = 2013;

The query will be executed following this plan, in inside-out order:
Finalize Aggregate
└── Gather
└── Partial Aggregate
└── Parallel Seq Scan
So the PostgreSQL will do a Sequential Scan in parallel with 2 workers, then for each worker, it will do a Partial Aggregation (sum function) and then Gather the results from workers and then does a Finalized Aggregation (sum function).
In Parallel Seq Scan node, it does 3 loops, for each loop, scans 3,333,333 rows (= 3,166,526 + 166,807)
To understand how Partial Aggregate work together with Finalize Aggregate, read more about PARALLEL-AGGREGATION and PARALLEL-SEQ-SCAN
With index:
An index is designed for a specific query, so let's consider two ways of creating the index for two different queries but they serve the same purpose.
Using index on an expression:
Now create an index on created_at column, because we use the extract(year from created_at) expression on the query, so we need to use that expression on the index too (read more about indexes on expression):
create index my_index on orders (extract(year from created_at));
explain analyze select sum(total) from orders
where extract(year from created_at) = 2013;

Aggregate
└── Bitmap Heap Scan
└── Bitmap Index Scan
Now it uses my_index for the scan, and the execution time is reduced from 1441.190ms to 227.388ms (84,22%), that is significant.
Using index on a column:
There is another way to calculate the total value of orders in 2013 using between operator
explain analyze select sum(total) from orders
where created_at between '2013-01-01' and '2013-12-31';
with this query we just need to create the index on created_at column:
create index my_index_2 on orders(created_at);

Finalize Aggregate
└── Gather
└── Partial Aggregate
└── Parallel Bitmap Heap Scan
└── Bitmap Index Scan
With this pair of index - query, it turns on the parallel workers and reduced from 1441.190ms to 179.813ms (87,52%).
What are Bitmap Index Scan and Bitmap Heap Scan?
Let's take a look on the table layout and page layout:
"Every table and index is stored as an array of pages." - Ref
"All indexes in PostgreSQL are secondary indexes, meaning t hat each index is stored separately from the table's main data area (which is called the table's
heapin PostgreSQL terminology)." - Ref
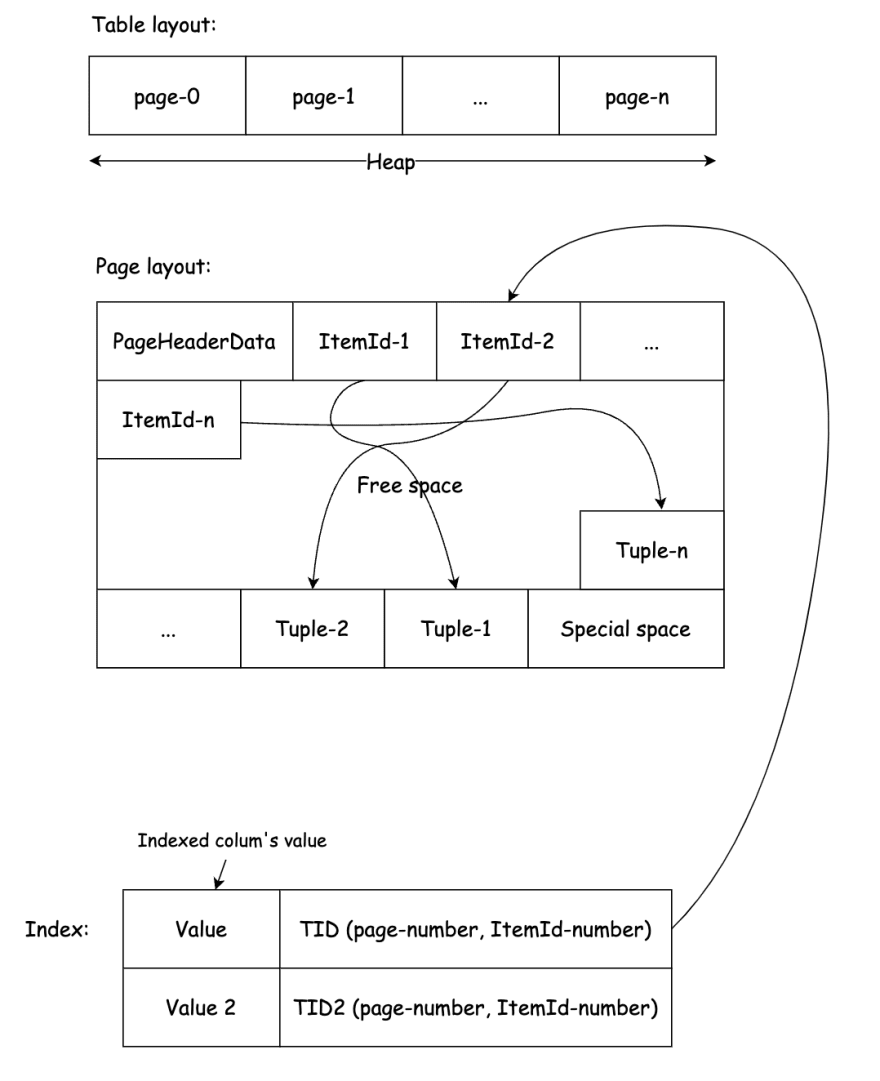
As the page layout is explained in bufpage.h:
-
ItemIdorLinePointer: logical offset that point to the actual data (Tuple - a row/record in table) within that page. New data (and its pointer) will be added into free space. The page is full when free space is full. -
TID(Tuple identifier) orItemPointer: a pair of (page/block number,LinePointernumber) that points to aLinePointer/ItemIdin a page.
Bitmap Index Scan: Scan on the index and create the bitmap. Bitmap is an array of bits that shows which page to be fetched. First, the PostgreSQL will scan the index to find values that match the condition, then turn the bit on the corresponding page on the bitmap to 1.
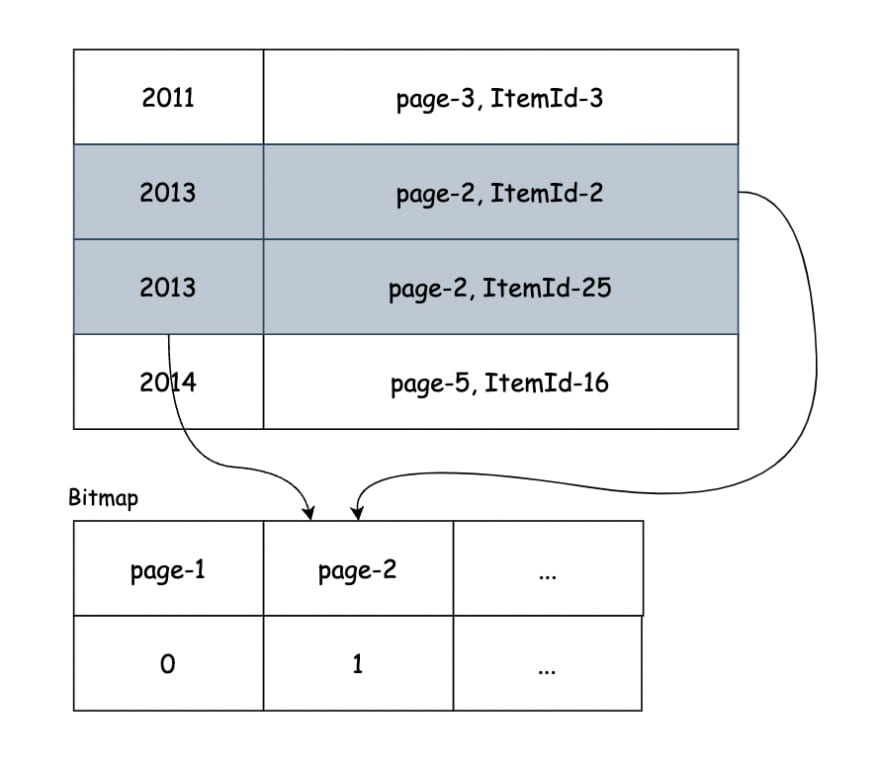
Bitmap Heap Scan: based on the created bitmap, it will do a sequential disk read to the heap to retrieve pages wich are marked 1, then from that pages the Recheck Cond will remove all the rows that do not match with the condition.
For each matched row on the index, if the PostgreSQL do a random IO access to the disk to fetch the entire row, it will be very slow because random I/O access is way slower than sequential I/O access.
So with the bitmap, it will read data in bulk (sequential IO access) and make sure the matched pages are not read multiple times.
Adding more column to the index (Multicolumn indexes):
On the example above, we see Bitmap Heap Scan, to improve the speed we can add both created and total into the index to make an Index Only Scan
drop index my_index_2;
create index my_index_2 on orders(created_at, total);

Because all the information which the query needs are on the index, so it does not need to fetch data on the heap. 179.813ms (Bitmap Heap Scan) is now reduced to 69.775ms (Index Only Scan).
Column order in an multicolumn index:
We should consider the column order of an index. Let's reverse the order from (created_at, total) to (total, created_at) and try again, we will see the planner will not use the index, it will do a Seq Scan to the whole table instead:
drop index my_index_2;
create index my_index_2 on orders(total, created_at);

With (created_at, total), the index will sort data by created_at first, then sort by total:
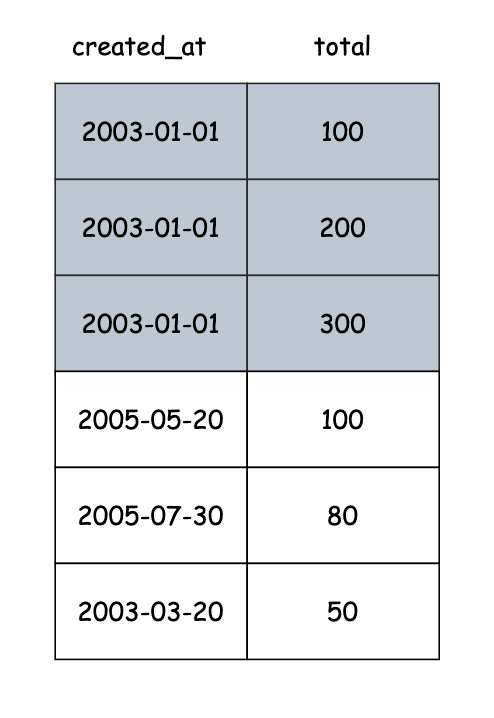
The PostgreSQL will look into the index from left to right. If the query matches the index order, the planner will use the index.
On the query above, the planner will do an analysis first, it will start with the condition -> find all rows with the date in 2013, then do an aggregation (sum) on the found rows. But the total is the first column on the index, not created_at, the planner cannot skip the order.
More column:
Let's drop the my_index_2 and create it again to reorder the columns
drop index my_index_2;
create index my_index_2 on orders(created_at, total);
Let's make an example that need more column. If we want to know who and how much they bought in 2013, the user_id is getting involved.
This is what we want:
sum | user_id
-------+---------
32576 | 1
16119 | 2
18539 | 3
The query:
select sum(total), user_id from orders
where created_at between '2013-01-01' and '2013-12-31' group by user_id;
It will trigger the index my_index_2, but it still needs to read data on the heap to get user_id data.

Let's add user_id column to the index:
drop index my_index_2;
create index my_index_2 on orders(created_at, user_id, total);
Now Index Only Scan is used because all the information are stored on the index, the execution time is reduced from 326.488ms to 179.271ms:

Column order on the index:
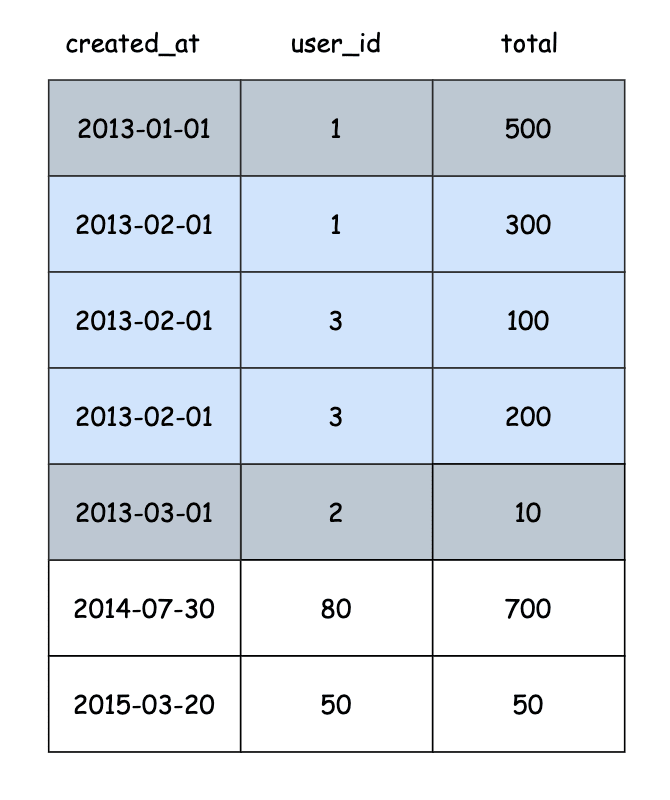
Rows in the index above are sorted by created_at, if two rows has the same created_at value, then it will sort them by user_id, and so on.
If we want to know the date and how much of orders > 2000 usd that a specific user made in 2013:
select total, created_at from orders
where
total > 2000 and
user_id = 2 and
created_at between '2013-01-01' and '2013-12-31';

Although the order in the where clause does not match the order in the index, PostgreSQL is smart enough to handle it. Other database software might not use the index in this case.
Trying other column orders:
drop index my_index_2;
create index my_index_2 on orders(total, user_id, created_at);

What happened? The planner uses Seq Scan instead of Index Only Scan, even there is no function on the query, and the query's column order matches the index, why the planner does not use Index Only Scan?
To find out, use this command to discourage seq scan and try again:
set enable_seqscan = off;

Total cost estimation: 138388.73ms (SeqScan) < 242808.46ms (Index Only Scan), so the planner
thinks seq scan is faster than the index only scan, the estimation can be bad in this case.
To understand more about cost estimation, read more here.
Instead of helping the estimation become more accurate, which is related to many factors that are not the same in your dev/staging/prod mode.
Let's try another orders:
user_id, created_at, total:
drop index my_index_2;
create index my_index_2 on orders(user_id, created_at, total);

user_id, total, created_at:
drop index my_index_2;
create index my_index_2 on orders(user_id, total, created_at);

Wow, just let user_id be the first column, from 168ms, it reduced to 0.112ms ~ 0.188 ms. That is a big improvement.
In my example database, it has 7,998,663 rows that total > 2000, but a specific user only has around 90 ~ 100 rows, so if the index is sorted by user_id first, it will eliminate almost all the cases.
So in the real-world application, we should design the index base on the requirements of the business. Understanding the distribution of the data would be very helpful, and keep in mind that an index is designed only for a specific query.





Latest comments (0)