Author: Brecht De Rooms
Date: Feb 22nd, 2021
Introduction
In our first article, we got our first taste of Fauna relational modeling using the data model for a DVD rental business (adapted from a popular Postgres tutorial). In this chapter, we’ll continue adapting this borrowed data model to learn how Fauna can query many-to-many collections in a normalized fashion.
Modelling many-to-many relationships in Fauna
Typically, a film has multiple categories, and a category has multiple films, so let’s slightly adapt the model again (in green) to turn it into a many-to-many relation.

Storing the many-to-many relation
Before we can add relations, we need to add some categories. Let’s make the category collection with the following FQL statement.
CreateCollection({name: "category"})
And add some categories
Do(
Create(Collection("category"), {
data: {
"name": "Horror"
}
}),
Create(Collection("category"), {
data: {
"name": "Documentary"
}
})
)
We used the Do function to execute both statements in one transaction. We now have three documents, but no link between them.

In a traditional relational database, we would probably opt for an association/junction table to model this relation in a normalized fashion.

Since Fauna is a combination of a relational and document model, there are many possible ways to model this:
- Model the relation with an association table (similar to the Postgres approach)
- Store an array of category references in the film document.
- Duplicate references and store on both sides.
- Embed the category document in the film document
- Duplicate data and embed in both directions
The trade-offs between different solutions typically boil down to whether you are optimizing for writes or reads, and the degree of flexibility you desire. We'll look at these other approaches later, but first, let's assume that we don't have any users yet and thus don't know which common access patterns we need to optimize.
If we don’t know what the future will bring, an association table is a safe choice. Similar to the Postgres approach, we’ll create a collection film_category where each document will store a reference to both a film and a category. Joining a film with a category will require us to go through that relation document.

Let’s create the documents for the association collection:
CreateCollection({name: "film_category"})
And add some documents that will serve as an association between film and category documents.
Do(
Create(Collection("film_category"), {
data: {
category_ref: Ref(Collection("category"), "288805203878086151"),
film_ref: Ref(Collection("film"), "288801457307648519")
}
}),
Create(Collection("film_category"), {
data: {
category_ref: Ref(Collection("category"), "288805203878085127"),
film_ref: Ref(Collection("film"), "288801457307648519")
}
})
)
Keeping primary keys unique
Once we create a document linking a film with a category, we need to make sure that we don't accidentally create a duplicate document with the same content.
Although Fauna is schemaless, it does provide uniqueness constraints. We can optionally add uniqueness constraints to our primary keys to ensure that the same primary key does not exist twice. These constraints are enforced transactionally by creating an index on the properties of that specific collection and setting the unique attribute to true. Defining the index below would make sure that the combination of category_ref and film_ref remains unique.
CreateIndex({
name: "unique_film_category",
source: Collection("film_category"),
values: [
{field: ["data", "category_ref"]},
{field: ["data", "film_ref"]}
],
unique: true
})
The uniqueness is determined by the combination of values and terms. For more information, take a look at the docs.
Querying the relation
Let’s start where we left off in the first article. Remember this query?
Map(
Paginate(Documents(Collection("film"))),
Lambda(["filmRef"],
Let({
film: Get(Var("filmRef")),
spokenLang: Get(Select(['data', 'language', 'spoken'], Var("film"))),
subLang: Get(Select(['data', 'language', 'subtitles'], Var("film")))
},
// return a JSON object
)
)
Films and languages had a one-to-many relationship because we needed to get multiple languages for a given film, but not vice versa. So the simplest solution was to store the language references on the film document itself.
In contrast, our film-to-category relation is many-to-many, so we stored the film-category references in a new film_category collection instead of on the film document.
Now, we'll learn how to query both language and category together. Here's a simplified version of how this would look in Postgres:
SELECT * FROM film
JOIN "language" as spol ON spol.language_id = film.spoken_language_id
JOIN "language" as subl ON subl.language_id = film.subtitles_language_id
JOIN film_category ON film.film_id=film_category.film_id
JOIN category ON film_category.category_id=category.category_id
However, since Fauna provides pagination on multiple levels what we’re actually about to implement looks more like this:
SELECT
film.title,
film.description,
film.last_update,
jsonb_agg(to_jsonb(spol)) ->> 0 as spoken_language,
jsonb_agg(to_jsonb(subl)) ->> 0 as subtitle_language,
jsonb_agg(to_jsonb(category))
FROM film
JOIN "language" as spol ON spol.language_id = film.language_id
JOIN "language" as subl ON subl.language_id = film.language_id
JOIN film_category ON film.film_id=film_category.film_id
JOIN category ON film_category.category_id=category.category_id
GROUP BY film.film_id
HAVING COUNT(film_category.category_id) < 64
LIMIT 64
This optimized query is actually much cleaner in FQL. All we need is an index.
Remember, an index's terms define what it matches, while the index's values define what the index returns. In the previous index, we added ‘ref’ as a single value. If we did the same here, only the “film_category” document reference would be returned. Instead, we need the category_ref from within the document's data object, so we’ll add “data”, “category_ref“ as the value to return.
CreateIndex(
{
name: "category_by_film",
source: Collection("film_category"),
terms: [
{
field: ["data", "film_ref"]
}
],
values: [
{
field: ["data", "category_ref"]
}
]
}
)
In the previous query, we stored the film reference in the variable “ref”. To match the index, we’ll use the Match() function and provide it with this film reference as a parameter.
Match(Index("category_by_film"), Var("ref"))
The Match() function returns a set that must be materialized with Paginate (just in case the underlying set is huge).
Paginate(Match(Index("category_by_film"), Var("ref")))
And finally, we’ll Map over the page to Get the reference.
Map(
Paginate(Match(Index("category_by_film"), Var("ref"))),
Lambda("catRef", Get(Var("catRef")))
)
When we insert this into the complete query, we see the pagination on multiple levels appear.
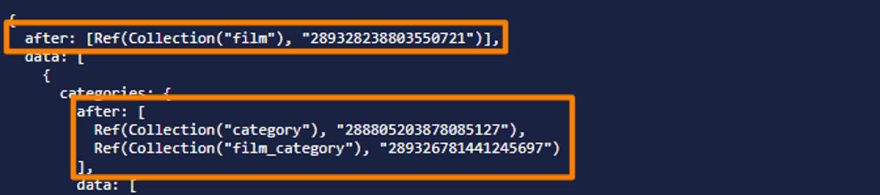
Map(
Paginate(Documents(Collection("film"))),
Lambda(["ref"],
Let({
film: Get(Var("ref")),
spokenLang: Get(Select(['data', 'language', 'spoken'], Var("film"))),
subLang: Get(Select(['data', 'language', 'subtitles'], Var("film"))),
categories: Map(
Paginate(Match(Index("category_by_film"), Var("ref"))),
Lambda("catRef", Get(Var("catRef")))
)
},
{
categories: Var('categories'),
film: Var('film'),
language: {
spoken: Var("spokenLang"),
subtitles: Var("subLang")
}
})
)
)
If we added a size parameter to both Pagination functions and had enough data, we would retrieve cursors on multiple levels, one for the films and one for the categories within each film, allowing us to drill down on both levels independently. For example, in the case of twitter users and their followers, where the numbers of tweets and comments can be very high, a sane pagination strategy is crucial.
Joins vs Map/Get
We have seen in the many-to-many relations that there was a Map/Get pattern on two levels. We can easily come up with queries that go deeper than two levels. In Fauna, such a query would add a nested Map/Get statement while in Postgres we would probably add another join.
The Map/Get pattern looks very similar to an index nested loop made explicit in the query with the difference that in many cases we can take advantage of native Fauna references. A query with multiple nested Map/Get statements is however very different from a multi-join. A Postgres multi-join would typically happen in multiple stages and in between each stage the intermediate format is one big table. In contrast, Fauna’s Map/Get pattern keeps the nested structure and will extend the structure. Instead of a big join in each step, Fauna adds to the document with many tiny loops which is very reminiscent of how graph database and avoids the join monster problem.
We could imagine that a SQL multi-join with three tables looks as follows:

While a simplified visualization of nested Map/Gets in Fauna would look more like this:

This becomes particularly interesting when we are dealing with many joins since such an approach is very parallelizable, avoids a lot of overhead and remains tractable due to the mandatory pagination. Most importantly, it maps extremely well on Object Relational Mappers (ORMs), GraphQL queries or simply the kind of dataformat that many applications require. In essence, Fauna does not suffer from the Object–relational impedance mismatch which brings quite some technical difficulties when applications developed in an object-oriented fashion are served by a relational database such as Postgres.
Using FQL to write a Domain Specific Language
Instead of writing one big query, we could have written a number of functions specific to our application domain or in other words, we could have taken a first (small) step towards building a small Domain Specific Language (DSL) by taking advantage of the host language to split up the query into composable functions.
var SelectAllRefs = (name) =>
Paginate(Documents(Collection(name)))
var GetCatsFromFilmRef = (filmRef) => Map(
Paginate(Match(Index("category_by_film"), filmRef)),
Lambda("catRef", Get(Var("catRef")))
)
var GetLangFromFilm = (film, langType) => Get(
Select(['data', 'language', langType], Var("film"))
)
var GetFilmWithLangsAndCats = (filmRef) => Let(
{
film: Get(filmRef)
},
{
categories: GetCatsFromFilmRef(filmRef),
film: Var('film'),
language: {
spoken: GetLangFromFilm(Var("film"), 'spoken'),
subtitles: GetLangFromFilm(Var("film"), 'subtitles')
}
}
)
var SelectFilmsWithLangsAndCats = () => Map(
SelectAllRefs("film"),
Lambda(["ref"], GetFilmWithLangsAndCats(Var("ref")))
)
The advantages are probably stronger than one would imagine at first and often result in a serious increase in productivity once it “clicks”.
Extensibility
If our application shows an overview of films, we might want to show actors as well. We do not have to restructure the query and since we now have a simplified format of the query, we can easily add a hypothetical GetActorsFromFilmRef() function which would have a similar implementation as we did for categories.
var GetFilmWithLangsCatsActors = (filmRef) => Let(
{
film: Get(filmRef)
},
{
categories: GetCatsFromFilmRef(filmRef),
film: Var('film'),
language: {
spoken: GetLangFromFilm(Var("film"), 'spoken'),
subtitles: GetLangFromFilm(Var("film"), 'subtitles')
},
actors: GetActorsFromFilmRef(filmRef),
}
)
Reusability
When we update a film, we might want to return the film immediately after the update to update the User Interface of the application. To make it easier to reason about our application model, we typically want to ensure that the format aligns with our previous film format. In case we want to return the film together with languages and categories in the same format we can do this in a very elegant way. All we need to do is write the Update statement:
function UpdateFilm(filmRef, description) {
return Update(
filmRef,
{
data: {
description: description
}
}
)
}
And then add the function we already defined to it.
function UpdateFilm(filmRef, description) {
return Do(
Update(
filmRef,
{
data: {
description: description
}
}
),
GetFilmWithLangsAndCats(filmRef)
)
}
If you know that Update already returns the film document upon completion, this might seem inefficient, but it doesn’t matter since Fauna optimizes this and won’t retrieve the same document twice. That means that you can compose without having to think about this performance concern.
Reusability in SQL is definitely possible, but requires error-prone string concatenation where a minor mistake could break the query. When reusability becomes easy, and we have transactions over the full query, there are some very interesting things we can do as we’ll see in the last chapter.
Adaptability
Another aspect is how easy it is to adapt the above FQL statement and make sure that everything that relies upon it is changed as well. For example, if we need to change films and languages to a many-to-many relation, then we simply change the GetLangFromFilm function.
var GetLangFromFilm = (film, langType) => Get(
Select(['data', 'language', langType], Var("film"))
)
But we actually have two types of languages: spoken and subtitles. Taking advantage of the procedural nature of FQL, we can use an If() test to decide which index we need to paginate over.
var GetLangsFromFilm= (film, langType) => Let({
filmRef: Select(['ref'], film),
langIndex: If(
Equals(langType, "spoken"),
Index("spoken_language_by_film"),
Index("subtitles_language_by_film")
)
},
Paginate(Match(Var('langIndex')))
)
We can safely say that we have only touched the languages format and seamlessly introduced pagination for languages. This is one example, but many complex adaptions become easy once we start composing our queries from small adaptable components.
Conclusion
This concludes chapter 2. In the next chapter, we'll dive into uniqueness constraints, referential integrity, optimizations with indexes, and finally compare the normalized approach we implemented with the other 4 mentioned approaches:
- Store an array of category references in the film document.
- Duplicate references and store on both sides.
- Embed the category document in the film document
- Duplicate data and embed in both directions
We’ll briefly look into these modelling strategies, and the different trade-offs and techniques to ensure data correctness even when duplicating data.




Top comments (0)