
Author: Pier Bover
Date: Oct 30th, 2020
Today, in the final article of the Core FQL series, we're going to take an in-depth look at the Join() function and its multiple uses.
This series assumes you have a grasp on the basics. If you're new to FaunaDB and/or FQL here's my introductory series on FQL.
In this article:
- Introduction
- Which robot parts are manufactured on Vulcan?
- What is a SetRef?
- Using Join() with Lambda()
- Using multiple joins
- Using Join() with Range()
- Replicating SQL joins in FQL
Introduction
It's important to clarify that Join() is not really related to SQL joins. In FQL, the Join() function allows you to query an index with the results of another index and get your data as efficiently as possible.
We'll be working with this data model:
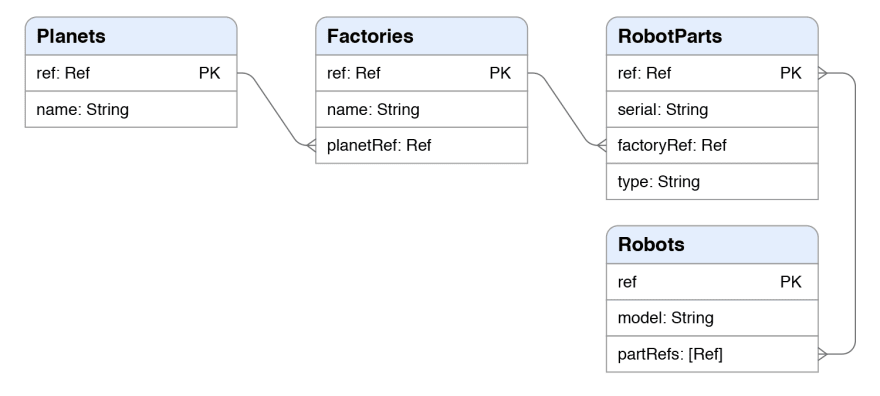
Each RobotPart belongs to a specific Factory, and each Factory belongs to a specific Planet. Each Robot can “have” one or more RobotParts.
Let's ignore our robots for now and create these collections:
> CreateCollection({
name: "Planets"
})
> CreateCollection({
name: "Factories"
})
> CreateCollection({
name: "RobotParts"
})
Also, create these two indexes to query our data:
> CreateIndex({
name: "Factories_by_planetRef",
source: Collection("Factories"),
terms: [
{field: ["data", "planetRef"]}
]
})
> CreateIndex({
name: "RobotParts_by_factoryRef",
source: Collection("RobotParts"),
terms: [
{field: ["data", "factoryRef"]}
]
})
Finally, let's create some documents. We'll specify reference ids so the article is easier to follow, but generally you do not need to do that when creating documents.
> Create(
Ref(Collection("Planets"), "1"),
{
data: {
name: "Vulcan"
}
}
)
> Create(
Ref(Collection("Factories"), "1"),
{
data: {
name: "Robot Corp",
planetRef: Ref(Collection("Planets"), "1")
}
}
)
> Create(
Ref(Collection("Factories"), "2"),
{
data: {
name: "AGC Industries",
planetRef: Ref(Collection("Planets"), "1")
}
}
)
> Create(
Ref(Collection("RobotParts"), "1"),
{
data: {
serial: "Rygen 4",
factoryRef: Ref(Collection("Factories"), "1"),
type: "CPU"
}
}
)
> Create(
Ref(Collection("RobotParts"), "2"),
{
data: {
serial: "Zaphire 4",
factoryRef: Ref(Collection("Factories"), "2"),
type: "CPU"
}
}
)
> Create(
Ref(Collection("RobotParts"), "3"),
{
data: {
serial: "X92",
factoryRef: Ref(Collection("Factories"), "1"),
type: "SENSOR"
}
}
)
Let's test our indexes to see if everything is working as expected:
> Paginate(
Match(
Index("Factories_by_planetRef"),
Ref(Collection("Planets"), "1")
)
)
{
data: [
Ref(Collection("Factories"), "1"),
Ref(Collection("Factories"), "2")
]
}
> Paginate(
Match(
Index("RobotParts_by_factoryRef"),
Ref(Collection("Factories"), "1")
)
)
{
data: [
Ref(Collection("RobotParts"), "1"),
Ref(Collection("RobotParts"), "3")
]
}
Which robot parts are manufactured on Vulcan?
Without using Join(), your first instinct to answer this question might be to do something like this:
> Map(
Paginate(
Match(
Index("Factories_by_planetRef"),
Ref(Collection("Planets"), "1")
)
),
Lambda(
"factoryRef",
Paginate(
Match(
Index("RobotParts_by_factoryRef"),
Var("factoryRef")
)
)
)
)
{
data: [
{
data: [
Ref(Collection("RobotParts"), "1"),
Ref(Collection("RobotParts"), "3")
]
},
{
data: [Ref(Collection("RobotParts"), "2")]
}
]
}
We're first getting all the factories for a given planet. Then, for each factory reference, we're querying the RobotParts_by_factoryRef index.
We can get away with this when working with small collections, but the main issue with this approach is that it doesn't scale well.
What would happen if there were thousands of factories? Well, we'd need to query thousands of indexes to get all the parts for each factory. This can impact performance but also increase our FaunaDB bill by executing a read operation every time we use Paginate() to fetch indexed data.
Let's answer the same question but using Join() instead:
> Paginate(
Join(
Match(
Index("Factories_by_planetRef"),
Ref(Collection("Planets"), "1")
),
Index("RobotParts_by_factoryRef")
)
)
{
data: [
Ref(Collection("RobotParts"), "1"),
Ref(Collection("RobotParts"), "2"),
Ref(Collection("RobotParts"), "3")
]
}
We'll go into more detail a bit later, but how this works is that Join() is using the result of Match() to query the RobotParts_by_factoryRef index. After that, we're only using Paginate() once to fetch data.
Note that our results are much cleaner now. Instead of getting nested pages of data we now have exactly the answer to our question: a list of the parts manufactured on Vulcan.
As usual, if we wanted to get documents instead of references we could simply use Map() with Get():
> Map(
Paginate(
Join(
Match(
Index("Factories_by_planetRef"),
Ref(Collection("Planets"), "1")
),
Index("RobotParts_by_factoryRef")
)
),
Lambda(
"robotPartRef",
Get(Var("robotPartRef"))
)
)
{
data: [
{
ref: Ref(Collection("RobotParts"), "1"),
ts: 1603898541205000,
data: {
serial: "Rygen 4",
factoryRef: Ref(Collection("Factories"), "1"),
type: "CPU"
}
},
{
ref: Ref(Collection("RobotParts"), "2"),
ts: 1603898589080000,
data: {
serial: "Zaphire 4",
factoryRef: Ref(Collection("Factories"), "2"),
type: "CPU"
}
},
{
ref: Ref(Collection("RobotParts"), "3"),
ts: 1603898653913000,
data: {
serial: "X92",
factoryRef: Ref(Collection("Factories"), "1"),
type: "SENSOR"
}
}
]
}
What is a SetRef ?
To be able to understand what Join() does we first need to take a little technical detour.
You've probably seen this type of query multiple times in the documentation, or most of my previous articles:
> Paginate(Match(Index("AllTheThings"))
Let's examine what's happening here in more detail.
First, Index() returns a reference to an index document. To prove this we can use Get() to fetch the actual document of the index:
> Get(Index("AllTheThings"))
{
ref: Index("AllTheThings"),
ts: 1602778923870000,
active: true,
serialized: true,
name: "AllTheThings",
source: Collection("Things"),
partitions: 8
}
Match() still doesn't fetch any data but constructs a Set and returns a reference to it. This is usually simply called a SetRef in the FaunaDB documentation. Again, we can prove this by making this query:
> Match(Index("AllTheThings"))
{
"@set": {
match: Index("AllTheThings")
}
}
Finally, Paginate() actually returns a page of data. If you think about it, SetRef is kinda like a "data recipe" that Paginate() uses to do the data-fetching work.
Let's look at our join example again:
> Paginate(
Join(
Match(
Index("Factories_by_planetRef"),
Ref(Collection("Planets"), "1")
),
Index("RobotParts_by_factoryRef")
)
)
We can now better understand what's going on here.
Join() is actually producing a SetRef and returning it to Paginate(). It is doing that by combining the SetRef produced by Match() with a reference to an index.
Using Join() with Lambda()
Instead of using a reference to an index, Join() also accepts a lambda function in its second argument. This is useful in a number of scenarios. For example, when we're using indexes that accept multiple filtering terms.
We've already figured out which parts are manufactured on a given planet. Let's now answer the following question: Which CPUs are manufactured on Vulcan?
To answer this we need to create a new index that will allow us to get our parts by factory and also by part type:
> CreateIndex({
name: "RobotParts_by_factoryRef_and_type",
source: Collection("RobotParts"),
terms: [
{field: ["data", "factoryRef"]},
{field: ["data", "type"]}
]
})
We can now use that index in our join operation with Lambda():
> Paginate(
Join(
Match(
Index("Factories_by_planetRef"),
Ref(Collection("Planets"), "1")
),
Lambda(
"factoryRef",
Match(
Index("RobotParts_by_factoryRef_and_type"),
[Var("factoryRef"), "CPU"]
)
)
)
)
{
data: [
Ref(Collection("RobotParts"), "1"),
Ref(Collection("RobotParts"), "2")
]
}
The Lambda() function receives whatever the Factories_by_planetRef index is returning. In this case, the references to the factory documents. We're now able to use Var("factoryRef"), "CPU" with our second index to filter by factory and part type.
Lambda() is also helpful when our first index returns an array of sorted values. Let's create an index that returns the name and reference of the Factories documents:
> CreateIndex({
name: "Factories_by_planetRef_sorted_name",
source: Collection("Factories"),
values: [
{field: ["data", "name"]},
{field: ["ref"]}
],
terms: [
{field: ["data", "planetRef"]}
]
})
Let's query the index to see what it returns when passing the reference of the Vulcan planet:
> Paginate(
Match(
Index("Factories_by_planetRef_sorted_name"),
Ref(Collection("Planets"), "1")
)
)
{
data: [
["AGC Industries", Ref(Collection("Factories"), "2")],
["Robot Corp", Ref(Collection("Factories"), "1")]
]
}
As expected, for each result we're now getting an array of values instead of a document reference.
Let's now use Lambda() to extract the reference for our join operation:
> Paginate(
Join(
Match(
Index("Factories_by_planetRef_sorted_name"),
Ref(Collection("Planets"), "1")
),
Lambda(
["name", "factoryRef"],
Match(
Index("RobotParts_by_factoryRef"),
Var("factoryRef")
)
)
)
)
{
data: [
Ref(Collection("RobotParts"), "1"),
Ref(Collection("RobotParts"), "2"),
Ref(Collection("RobotParts"), "3")
]
}
Using multiple joins
If you've been wondering, yes we can combine multiple joins to answer even more complex questions. While a bit verbose at times, FQL is extremely flexible and powerful.
Let's answer this question: Which robots use CPUs that are manufactured on Vulcan?
It's now time to finally create our robots from our initial data model:
> CreateCollection({
name: "Robots"
})
> CreateIndex({
name: "Robots_by_part",
source: Collection("Robots"),
terms: [
{field: ["data", "partRefs"]}
]
})
> Create(
Ref(Collection("Robots"), "1"),
{
data: {
model: "Z3P0",
partRefs: [
Ref(Collection("RobotParts"), "1"),
Ref(Collection("RobotParts"), "3")
]
}
}
)
Let's test our index to see what it returns:
> Paginate(
Match(
Index("Robots_by_part"),
Ref(Collection("RobotParts"), "1")
)
)
{
data: [Ref(Collection("Robots"), "1")]
}
As you can see, even though partRefs in the robot document is an array, FaunaDB is smart enough to look for the filtering term inside the array instead of comparing the whole array.
We're now ready to combine the previous join (which returned a list of part references manufactured in a planet) with a new one that returns a list of robots:
> Map(
Paginate(
Join(
Join(
Match(
Index("Factories_by_planetRef"),
Ref(Collection("Planets"), "1")
),
Lambda(
"factoryRef",
Match(
Index("RobotParts_by_factoryRef_and_type"),
[Var("factoryRef"), "CPU"]
)
)
),
Index("Robots_by_part")
)
),
Lambda(
"robotRef",
Get(Var("robotRef"))
)
)
{
data: [
{
ref: Ref(Collection("Robots"), "1"),
ts: 1603899351476000,
data: {
model: "Z3P0",
partRefs: [
Ref(Collection("RobotParts"), "1"),
Ref(Collection("RobotParts"), "3")
]
}
}
]
}
Using Join() with Range()
Join() can also be useful in certain scenarios where we want to combine and/or intersect the results of Range() over different indexes of the same collection.
In case you didn't read it, we explored how to use Range() in a previous article.
To test this let's create a new collection and some documents:
> CreateCollection({
name: "Spaceships"
})
> Create(
Ref(Collection("Spaceships"), "1"),
{
data: {
name: "Interceptor",
maxSpeed: 20,
weight: 100
}
}
)
> Create(
Ref(Collection("Spaceships"), "2"),
{
data: {
name: "Explorer",
maxSpeed: 10,
weight: 200
}
}
)
> Create(
Ref(Collection("Spaceships"), "3"),
{
data: {
name: "Transporter",
maxSpeed: 5,
weight: 1000
}
}
)
First, let's create an index to be able to run a range query involving each ship’s maxSpeed field:
> CreateIndex({
name: "Spaceships_by_maxSpeed",
source: Collection("Spaceships"),
values: [
{field: ["data", "maxSpeed"]},
{field: ["ref"]}
]
})
We can now execute a range query with this index to get the spaceships up to 15 of maxSpeed:
> Paginate(
Range(Match(Index("Spaceships_by_maxSpeed")), [], [15])
)
{
data: [
[5, Ref(Collection("Spaceships"), "3")],
[10, Ref(Collection("Spaceships"), "2")]
]
}
Let's create a second index to be able to execute range queries over the weight field:
> CreateIndex({
name: "Spaceships_by_weight",
source: Collection("Spaceships"),
values: [
{field: ["data", "weight"]},
{field: ["ref"]}
]
})
And this is how we'd get all the spaceships up to 500 of weight:
Paginate(
Range(Match(Index("Spaceships_by_weight")), [], [500])
)
{
data: [
[100, Ref(Collection("Spaceships"), "1")],
[200, Ref(Collection("Spaceships"), "2")]
]
}
If we now wanted to know which ships have up to 15 of maxSeed and also weight up to 500 we could use Intersection() like we saw in a previous article:
> Paginate(
Intersection(
Range(Match(Index("Spaceships_by_maxSpeed")), [], [15]),
Range(Match(Index("Spaceships_by_weight")), [], [500])
)
)
{
data: []
}
Huh? How come we're not getting anything?
The problem is that Intersection() is trying to compare two different sets of results returned by our two indexes. Since these results don't really match, it concludes there is no overlapping data.
Here's a neat trick. We can use Join() to solve this problem by extracting the reference in each case by using a helper index.
> CreateIndex({
name: "Spaceship_by_ref",
source: Collection("Spaceships"),
terms: [
{field: ["ref"]}
]
})
We can now do this:
> Paginate(
Intersection(
Join(
Range(Match(Index("Spaceships_by_maxSpeed")), [], [15]),
Lambda(
["maxSpeed", "ref"],
Match(
Index("Spaceship_by_ref"),
Var("ref")
)
)
),
Join(
Range(Match(Index("Spaceships_by_weight")), [], [500]),
Lambda(
["weight", "ref"],
Match(
Index("Spaceship_by_ref"),
Var("ref")
)
)
)
)
)
{
data: [Ref(Collection("Spaceships"), "2")]
}
We're using the results of our range queries with Join() and our Spaceship_by_ref helper index to produce two sets of references from the Spaceships collection. These references can then be intersected to determine which ships satisfy all our conditions, in this case our Explorer ship. All in one read operation!
Replicating SQL joins in FQL
FaunaDB is so inherently different from relational SQL databases it doesn't make sense to try to directly replicate SQL queries in idiomatic FQL. We can, however, answer the same questions.
Let's see a simple example. Imagine we had a Mechanics table and a Tools table and we executed this query:
SELECT * FROM Mechanics INNER JOIN Tools ON Mechanics.toolId = Tools.id WHERE Mechanics.toolId NOT NULL;
In plain English this query says: Find all the mechanics that have a **toolId, and then return the data of these mechanics and their tool.
To replicate this in FaunaDB let's create this model where each Mechanic has a Tool:

> CreateCollection({
name: "Tools"
})
> Create(
Ref(Collection("Tools"), "1"),
{
data: {
name: "Laser cutter"
}
}
)
> Create(
Ref(Collection("Tools"), "2"),
{
data: {
name: "Robo wrench"
}
}
)
> CreateCollection({
name: "Mechanics"
})
> Create(
Ref(Collection("Mechanics"), "1"),
{
data: {
name: "Anna Laser",
toolRef: Ref(Collection("Tools"), "1")
}
}
)
> Create(
Ref(Collection("Mechanics"), "2"),
{
data: {
name: "Johnny Sparkles",
toolRef: Ref(Collection("Tools"), "2")
}
}
)
Find all the mechanics that do have a tool
If we wanted to know which documents in the Mechanics collection have the toolRef field, we could use a simple index combined with a filter.
To test this out we're obviously going to need at least one mechanic without a toolRef:
> Create(
Ref(Collection("Mechanics"), "3"),
{
data: {
name: "Peter No Tool"
}
}
)
Now, let's create an index with some values:
> CreateIndex({
name: "Mechanics_with_toolRef_name",
source: Collection("Mechanics"),
values: [
{field: ["data", "name"]},
{field: ["data", "toolRef"]},
{field: ["ref"]}
]
})
If we query this index we'll see that Peter No Tool is right there with a null in the toolRef value:
> Paginate(
Match(
Index("Mechanics_with_toolRef_name")
)
)
{
data: [
[
"Anna Laser",
Ref(Collection("Tools"), "1"),
Ref(Collection("Mechanics"), "1")
],
[
"Johnny Sparkles",
Ref(Collection("Tools"), "2"),
Ref(Collection("Mechanics"), "2")
],
[
"Peter No Tool",
null,
Ref(Collection("Mechanics"), "3")
]
]
}
We can simply filter him out by checking that the toolRef value is indeed a reference using the IsRef() function:
> Paginate(
Filter(
Match(Index("Mechanics_with_toolRef_name")),
Lambda(
["name", "toolRef", "ref"],
IsRef(Var("toolRef"))
)
)
)
{
data: [
[
"Anna Laser",
Ref(Collection("Tools"), "1"),
Ref(Collection("Mechanics"), "1")
],
[
"Johnny Sparkles",
Ref(Collection("Tools"), "2"),
Ref(Collection("Mechanics"), "2")
]
]
}
Getting the mechanics and their tool
Ok, we now have filtered the mechanics that do have a toolRef. How can we get both the mechanic and tool data at the same time?
It's really is as simple as iterating the index results with Map() and returning a custom object:
> Map(
Paginate(
Filter(
Match(Index("Mechanics_with_toolRef_name")),
Lambda(
["name", "toolRef", "ref"],
IsRef(Var("toolRef"))
)
)
),
Lambda(
["name", "toolRef", "ref"],
{
mechanicDoc: Get(Var("ref")),
toolDoc: Get(Var("toolRef"))
}
)
)
{
data: [
{
mechanicDoc: {
ref: Ref(Collection("Mechanics"), "1"),
ts: 1603900312780000,
data: {
name: "Anna Laser",
toolRef: Ref(Collection("Tools"), "1")
}
},
toolDoc: {
ref: Ref(Collection("Tools"), "1"),
ts: 1603900232020000,
data: {
name: "Laser cutter"
}
}
},
{
mechanicDoc: {
ref: Ref(Collection("Mechanics"), "2"),
ts: 1603900351375000,
data: {
name: "Johnny Sparkles",
toolRef: Ref(Collection("Tools"), "2")
}
},
toolDoc: {
ref: Ref(Collection("Tools"), "2"),
ts: 1603900270177000,
data: {
name: "Robo wrench"
}
}
}
]
}
Conclusion
This is it. We've reached the fifth and final article in the Core FQL series. If you've made it this far, thanks reading. As always, I hope you learned something valuable!
If you have any questions don't hesitate to hit me up on Twitter: @pierb





Latest comments (0)