Ever since I started my job as a data analyst, I have heard many times from many different people that the most time-consuming task in data science is cleaning the data. And after a little more than a month in this new job, I can totally concur. However, python pandas library is making it smoother than I thought.
A little about pandas
Pandas is a an open source data analysis library that allows for intuitive data manipulation. It's based on two primary data structures:
It's a one-dimensional array capable of holding any type of data or python objects. I like to think of it as a column in Excel.
Series are by default indexed with integers (0 to n) but we can also define our own index.
It's a 2-dimensional labeled data structure with columns of potentially different types. I like to think of it as different series put together (or as a spreadsheet in excel). Dataframes are the most commonly used data types in pandas.
This 10 minutes to pandas article in the documentation explains everything you need to know to start with pandas!
Surprise! It's JSON nested objects...
It was not a good surprise. I had retrieved 178 pages of data from an API (I talk about this here) and I thought I had to write some code for each nested field I was interested in.
Indeed, my data looked like a shelf of russian dolls, some of them containing smaller dolls, and some of them not.

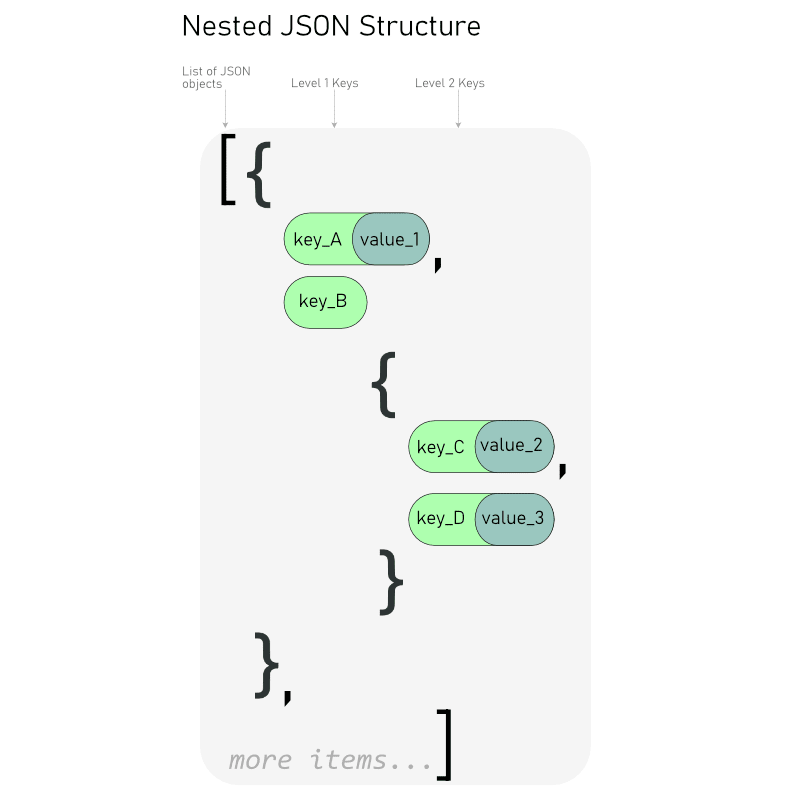
I was only interested in keys that were at different levels in the JSON. This seemed like a long and tenuous work.
The solution : pandas.json_normalize
Pandas offers a function to easily flatten nested JSON objects and select the keys we care about in 3 simple steps:
- Make a python list of the keys we care about. We can accesss nested objects with the dot notation
- Put the unserialized JSON Object to our function json_normalize
- Filter the dataframe we obtain with the list of keys
And voilà!
Since I had multiple files to clean that way, I wrote a function to automate the process throughout my code:
FIELDS = ['list of keys I care about']
def clean_data(data):
table = pd.DataFrame()
for i in range(len(data) - 1):
df = pd.json_normalize(data[i + 1])
df = df[FIELDS]
table = table.append(df)
return table
This function allowed me to clean the data I had retrieved and prepare clear dataframes for analysis in just a couple lines of code! 🙌





Top comments (1)
I tried this function and I got KeyError: 1