SQLAlchemy is the most widely used ORM in Python based application; its backend neutral and offers complete flexibility to build any complex SQL expression.
Today, we will try to showcase few of the unexplored or advance usage of the ORM which will be of great advantage in different scenarios.
Scenario 1:
Let’s consider you have a table called project and want to filter a data based on key project_id, task_id and component_id taken together which are present in subset of dataframe called project_to_retrieve.
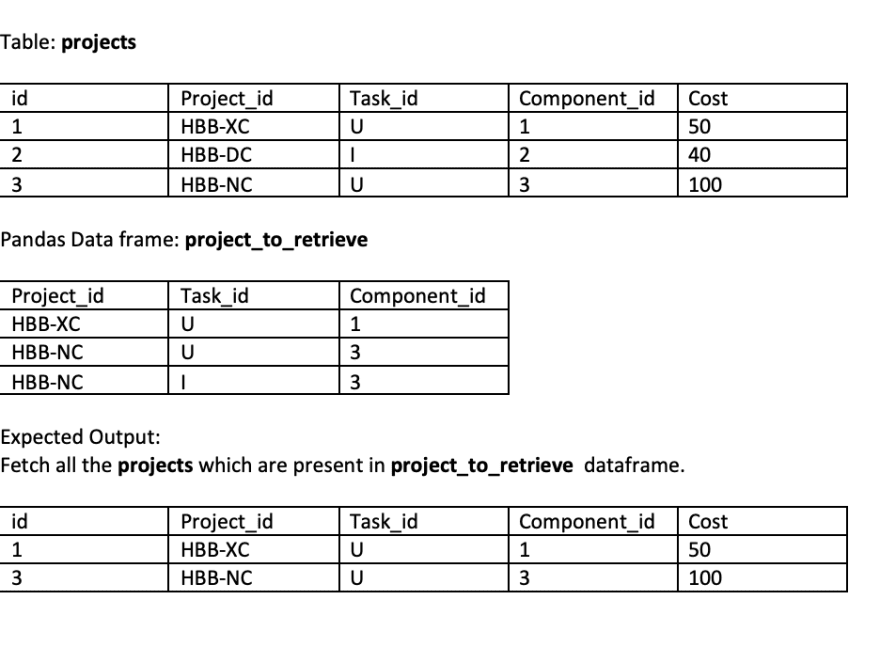
Hint: produce a composite IN construct
Solution:
# Connect To An SqLite Database
from sqlalchemy import create_engine
engine = create_engine(f'sqlite:///demo.db')
# Create a Project Table
from sqlalchemy import MetaData
meta = MetaData()
from sqlalchemy import Table, Column, Integer, String, MetaData
projects_table = Table(
'projects', meta,
Column('id', Integer, primary_key = True, autoincrement=True),
Column('project_id', Integer),
Column('task_id', Integer),
Column('component_id', Integer),
Column('cost', Integer),
)
meta.create_all(engine)
# Add Project Details
conn = engine.connect()
conn.execute(projects_table.insert(), [
{'project_id':'HBB-XC', 'task_id' : 'U', 'component_id' : 1, 'cost' : 50},
{'project_id':'HBB-DC', 'task_id' : 'I', 'component_id' : 2, 'cost' : 40},
{'project_id':'HBB-NC', 'task_id' : 'U', 'component_id' : 3, 'cost' : 100},
])
view_projects_data = projects_table.select()
result = conn.execute(view_projects_data)
print(f"Projects Tables Data: ")
for row in result:
print ("{} \t {}\t {} \t {} \t {}".format(row[0],row[1], row[2], row[3], row[4]))
# Subset of data to retrieve
import pandas as pd
data = [['HBB-XC', 'U', 1], ['HBB-NC', 'U', 3], ['HBB-NC', 'I', 3] ]
project_to_retrieve = pd.DataFrame(data,
columns=['project_id', 'task_id', 'component_id']
)
print(f"Projects To Retrieve: ")
print(project_to_retrieve.head(5))
# Solution Query
from sqlalchemy import tuple_
from sqlalchemy.sql import select
active_projects = select(
projects_table
).where(
tuple_(
projects_table.c.project_id,
projects_table.c.task_id,
projects_table.c.component_id
).in_(
project_to_retrieve[
["project_id", "task_id", "component_id"]
]
.to_records(index=False)
.tolist()
)
)
result = conn.execute(active_projects)
print(f"Active Projects Output: ")
for row in result:
print ("{}\t {} \t {} \t {}".format(row[0],row[1], row[2], row[3]))
Explanation:
Here If we split the code its divided into data preparation stage from line1-50 and and the query to retrieve data from line 51-76
In first part we have first created an engine to connect to an sqlite database named as demo, then we have ingested few of the records using SQLAlchemy ORM core insert statements. And finally we have created and pandas dataframe projects_to_retrieve which needs to retrieve active projects from projects table.
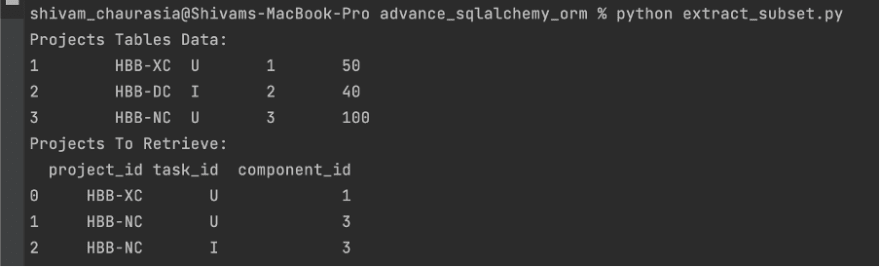
Now, in the second part, we are using tuple_ to retrieve the subset from table. This tuple will generate the composite in structure and will fitler on all the three conditions specified in the query.

Scenario 2:
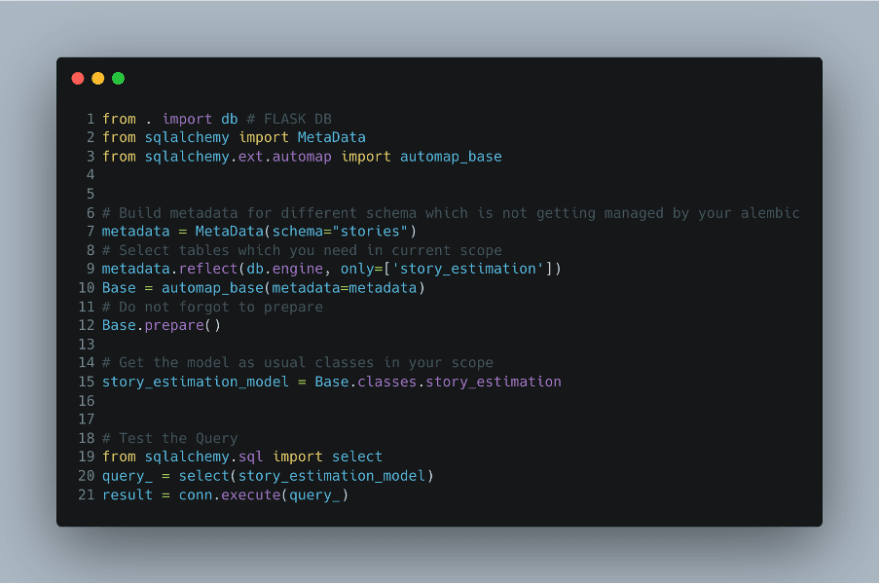
You are working on a certain SQLAlchemy based Flask project TASK_ESTIMATION and have tables TASK which is getting directly managed by your migrations. But you soon realized that you need to use the table STORY_ESTIMATION which reside in different schema STORIES which is not getting managed by your alembic migrations or models.
How will you able to bring this tables into your current scope?
Hint: Automap
Solution:
SQLAlchemy has a concept called Database reflection which can be used for reflecting the existing databases without recreating models or managing models from your side.
Scenario 3:
Consider the previous case. You are trying to use an AUTOMAP on below provided tables but suddenly you realized that the tables are not getting reflected from stories schema, what’s wrong in below table ?
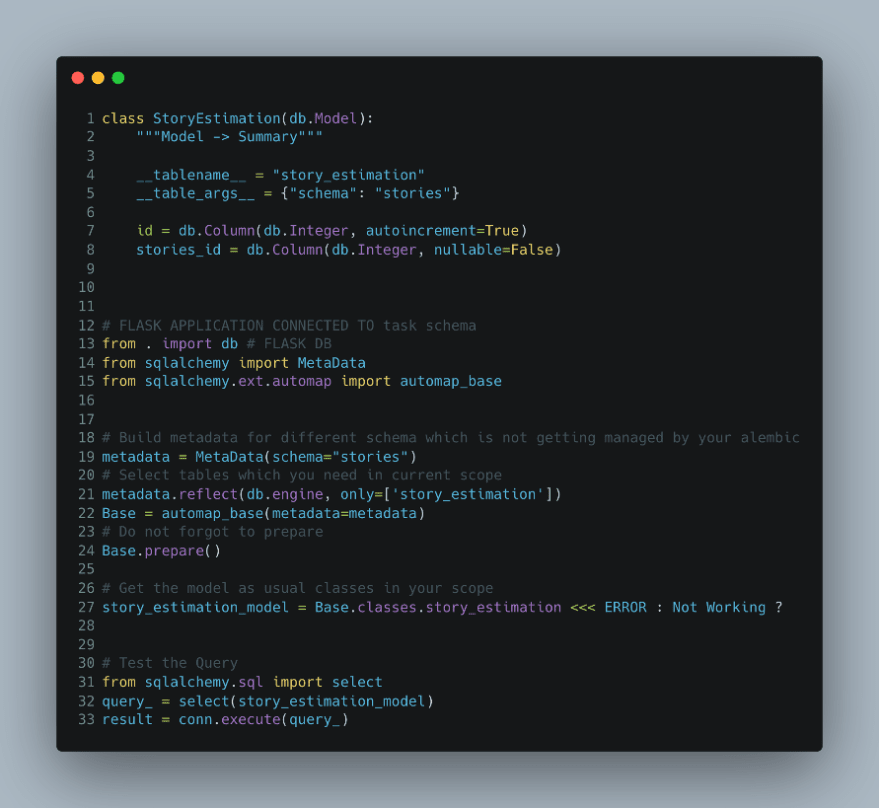
Solution:
For Database reflection to work its necessary that reflected tables is having an primary key.
![]()
In this case the issue is at line 7 where story estimation is not having any primary key. Which will result in error when model is accessed.
The fix for this would be to add a primary key constraint
![]()
Scenario 4:
Let’s consider you were having a list of dict which contains the values of project_id and cost. Using this python dict of list you want to update all the Project table using project_id and updating the cost.
Solution:
In this case we will be using the bindparam to produce bound expression which can be later passed with python list values at the time of execution.

Conclusion:
In this blog we discussed how we can leverage the sqlalchemy capabilities for reflecting existing tables from another schemas or database using AutoMap and the common issues which is often hard to debug for the first-time user of AutoMap.
Also, we have seen a use case where we dynamically filtered the composite conditions in a pandas dataframe using tuple_ expression.
And finally, dynamically binded python values using bindparam which provides options to provide values at a time of execution.
Disclaimers:
This is a personal blog. The views and opinions expressed here are only those of the author and do not represent those of any organization or any individual with whom the author may be associated, professionally or personally.





Latest comments (0)