Introduction:
Scrapy is a free and open-source web-crawling framework written in Python programming language. Designed for web scraping, it can also be used to extract data using APIs or as general-purpose web automation.
The best part about Scrapy is its speed. Since it is asynchronous, Scrapy can make multiple requests parallelly. This increases efficiency, which makes Scrapy memory and CPU efficient compared to conventional tools like Selenium, python-requests, JAVA JSoup, or rest-assured.
One of the limitations of Scrapy is that it cannot process JavaScript. To overcome this limitation, we can use JS rendering engines like Playwright, Splash, and Selenium. Splash is a JavaScript rendering engine with an HTTP API.
Now you may ask why use Splash with Scrapy. As we already have so many JS rendering engines. Because both Scrapy and Splash both are designed based on an event-driven twisted network protocol. Also Splash is very light weight and is capable of processing multiple pages in parallel. In my experience, Splash complements Scrapy's ability to crawl the web without hampering its performance.
In this blog, we will learn how we can exploit Splash for web crawling/automation.
Setup:
As this is an advanced tutorial, it is assumed that you have already worked on Python3 and Scrapy framework and have the setup ready on your machine. Now, the easiest way to set up Splash is through Docker.
Let us download and install Docker from the Docker official website. Once Docker is set up, we can pull the Splash image using the following command in the terminal.

Docker should be running in your system now. But before we can use it in our Scrapy framework, we need to install the python Scrapy-Splash dependency using Pip.
Then we need to add the Splash middleware settings into the settings.py file of our Scrapy project. The most important setting to modify is the DOWNLOADER_MIDDLEWARES. It should look like this:
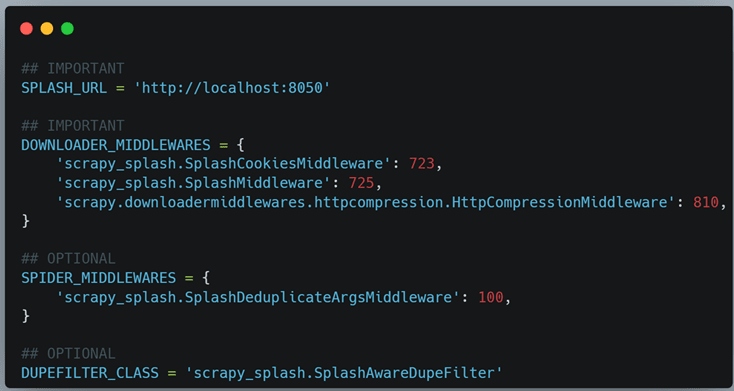
These settings will allow the Scrapy engine to communicate seamlessly with Splash. Please note that the SPIDER_MIDDLEWARES and DUPEFILTER_CLASS are optional as they help us avoid duplicate requests.
Usage:
We need to be able to tell the Scrapy engine when to use Splash for a particular request. The Scrapy-Splash package we just installed comes with a handy method called SplashRequest that does just that. Whenever we wish to invoke Splash and use its JS rendering capabilities, we can call SplashRequest instead of the usual Request.
Scrapy-Splash shares its features with other headless browsers, like, performing certain actions and modifying its working before returning the HTML response. One can configure Splash to do these actions by passing arguments or using Lua Scripts. This can be done with the args argument of the SplashRequest class.
We can also run custom JS code by passing it within the args dictionary. Here is an example:
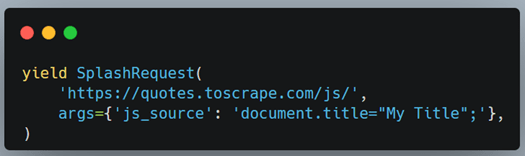
The SplashRequest call returns an object of the Scrapy Response class and can be used to grab data and perform required actions. This means that we can easily swap any Request call with SplashRequest and the rest of the code will not be affected.
Here is a list of some of the actions that can be performed using Splash (apart from custom JS execution):
- Wait for page elements to load
- Scroll the page
- Click on page elements
- Turn of images or use Adblock rules to make rendering faster
- Take screenshots
While the first four actions can only be performed using Lua script, and are out of scope for this tutorial, let us see how we can take screenshots and save them into a file. Our SplashRequest call should look something like this.
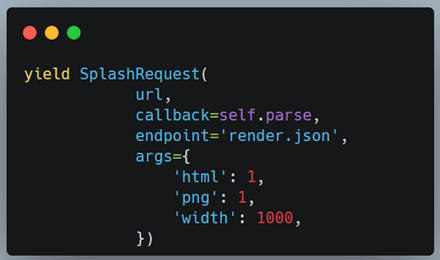
And here is the parse method that is being referenced (in the callback argument):
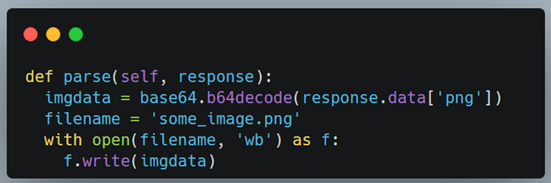
We are grabbing the 'png' attribute of the response and converting it into a base64 format, finally, this can be written to a file.
Data extraction and storage with Scrapy:
Either it's a simple scrapy Request or a SplashRequest, the process to extract data from the Response remains the same. As it uses lxml to build the HTML DOM tree, we can use traditional tools like XPath, CSS selector to grab HTML text, attribute values, etc. For the simplicity of this tutorial, we will build a spider that can crawl all the pages on this website and grab the data onto a file. This data will include information like quotes text, quote author, and tags. Let us see how we can extract data using XP_ath._
Just like we can perform all major actions on Selenium, via the driver, here the response variable can be used to perform various tasks like drabbing an element and extracting data from it. To get all the quotes on a page, we use the following XPath:
//div[@class="quote"]
Here's the rest of the code:
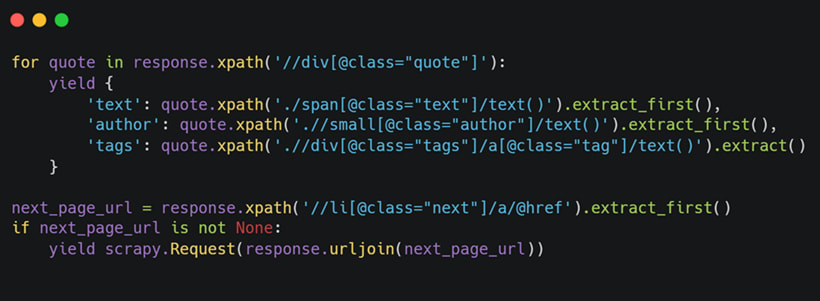
We are not only extracting data from the webpage but also intuitively following all the pagination links.
Executing this code took less than 5 seconds. Performing a similar task on something like selenium would take at least 50 seconds. Since there is no dependency on a web browser, along with an asynchronous approach, this speeds up the process quite a bit.
Let's see how data is extracted when we run this code. The first image show a sample terminal output of the scraping process,

But this is of no use unless we can store this scraped data into a file or database. Let's see how that's done.
Scrapy allows us to store scraped data in .csv or .json files without writing any additional code and we can enable this feature with the "-o" parameter. For example:
This will store all the scraped data into a file called "output.json". Here's a snapshot of the output file.

Scrapy Architecture:
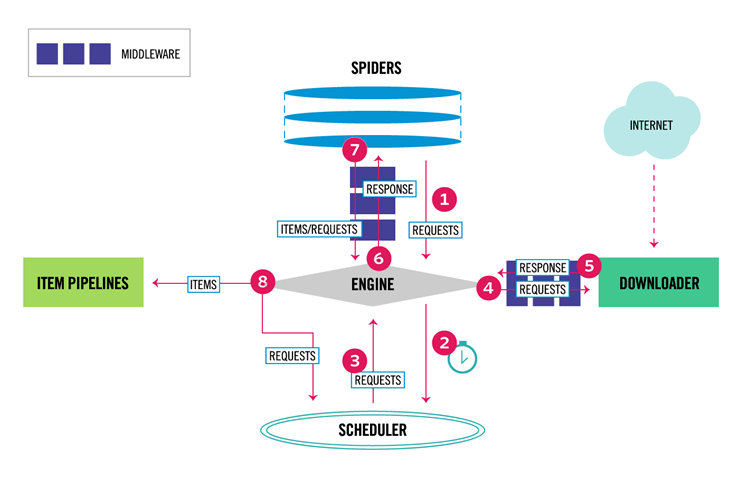
The above diagram shows the official architecture of the scrapy framework.
User agent rotation:
User agents are used to identifying themselves on the website. It tells the server some necessary details like browser name, version, etc. Let us look at how to set custom user agents using Scrapy Splash. The SplashRequest call has the optional headers parameter to provide custom headers. This is used to provide custom user agents in a dictionary structure.
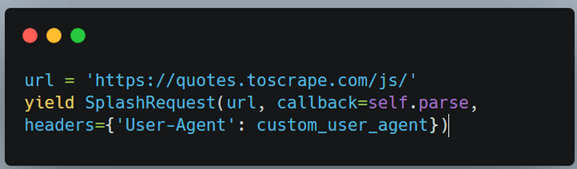
The above snippet demonstrates this in a quite simple and easy to understand manner. Let us say we have a list of user-agents in a file. We can use the python random choice to set the new user-agent into the headers if we want to set a new user-agent with every request. It is important to note that one can use the Scrapy-user-agents package to get an updated list of user-agents instead of maintaining one locally.
Conclusion:
One thing to note is that Scrapy is not a test automation tool like selenium, etc. Although third-party frameworks can be used alongside Scrapy to perform test automation, it was never designed for that purpose. It should be used for efficient and fast API or Web automation, web crawling, and other similar tasks.
Also, Splash can be used alongside Scrapy to process requests where rendering JS is necessary. In my experience we can use tools like Selenium along with Scrapy too, but that drastically slows it down. Splash is the best choice for JS rendering in Scrapy because both are developed by the same company. As Scrapy is written in Python, it is quite easy to learn and extremely popular among the Data Mining, Data Science community.
References:
- https://python.plainenglish.io/rotating-user-agent-with-scrapy-78ca141969fe
- https://github.com/scrapinghub/splash
- https://scrapeops.io/python-scrapy-playbook/scrapy-splash/
- https://splash.readthedocs.io/en/stable/index.html
- https://www.zyte.com/blog/handling-javascript-in-scrapy-with-splash/
- https://scrapy.org/
- https://docs.scrapy.org/en/latest/
- https://github.com/scrapy/scrapy
- https://www.analyticsvidhya.com/blog/2017/07/web-scraping-in-python-using-scrapy
Disclaimers:
Although web crawling is important in a variety of fields, please note that web crawling must be done ethically, and we must ensure that the script runs in accordance with the Terms of Use, etc of the website(s) being crawled.
This is a personal blog. The views and opinions expressed here are only those of the author and do not represent those of any organization or any individual with whom the author may be associated, professionally or personally.





Latest comments (0)