Back in April I contacted dev.to whether there was an API available or not. I needed that API because back then (and now!) I thought that the content was worth saving as reference. I coded a simple python scraper and converted the plain text to an PDF because those are more readable to me. I started running this program on my raspberry pi.
My data store grew and grew, but I never read anything. It was pointless, and decided to pull the plug on it. At least, I thought I pulled the plug. I remember disabling the cronjob, but today I was messing some more with cronjobs and found out was running ever since. I think this scraper has been running for at least 7 months.
Editors note: The reason why the plug wasnt pulled is because my SD card was in read-only mode. This means that I could make changes, which would only live in thee RAM. When the RPI was rebooted, the data disappeared. This renders this data useless, because it is data what got scraped to some point in time + the days while the pi was running.
Note that the data is only the raw text of the articles, not the comments and such. Discuss topics weren't really a thing in April.
Disclaimer: those numbers are probably not 100% accurate as it was just a quick script
First of all I decided to get some basic statistics on the dataset:
| Category | Statistic |
|---|---|
| Amount of articles | 1759 |
| Total size | 196608 bytes |
| Amount of authors | 793 |
Then I was wondering who were the top 10 posters:
| Who | Amount of posts |
|---|---|
| Ben Halpern | 128 |
| Vaidehi Joshi | 30 |
| Beekey Cheung | 25 |
| Walker Harrison | 24 |
| edA | 22 |
| K. 👓 | 21 |
| Ken W Alger | 19 |
| Phil Nash | 18 |
| Ryan Palo | 16 |
| dev.to staff | 16 |
And for fun I checked a few terms whether how much they existed in unique article titles. Note for words like 'go' it is taken into account that it could have other meanings and thus those were handpicked.
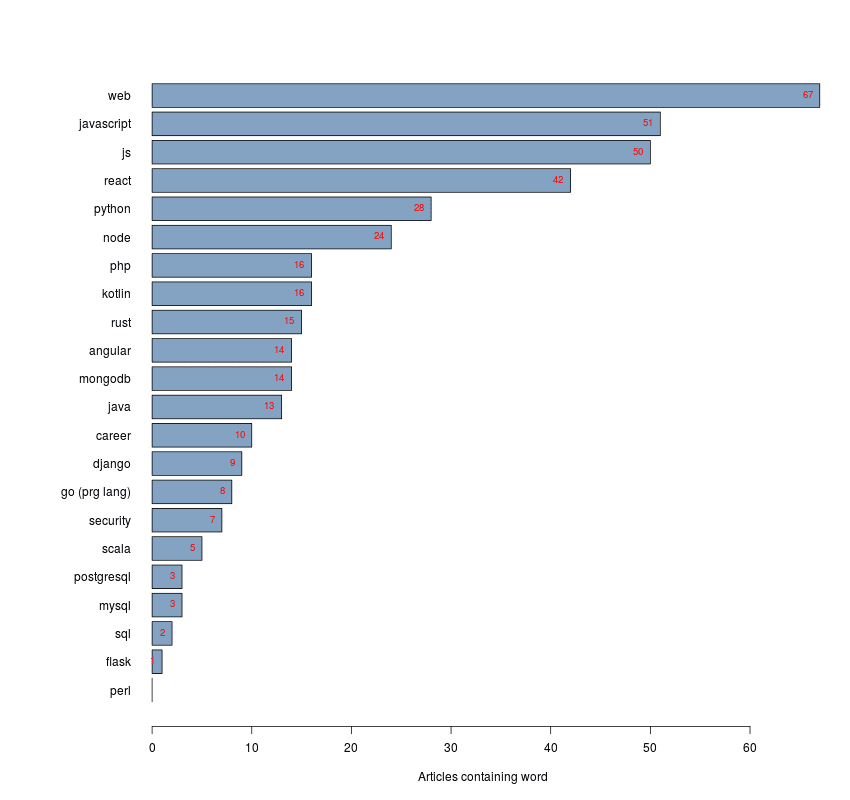
For now I will turn my scraper off, but I will keep this corpus to practise some text mining on. If you have ideas on what to do with this data, please share!





Top comments (5)
@walker looks like you got top 5 ;)
These are some cool stats. Thank you for sharing!
Hi! Can you share the code?
Sure, the code was part of a bigger plan but never actually finished it for some reason. Turns out the PDF generation was not even implemented yet.
gist.github.com/EngineerCoding/f68...
Oh, also we'll get that API out soon... 😓