
In this post, we will introduce some of the improvements of the MQTT broker cluster scalability. We will mostly focus on the database engine that EMQX uses internally and how we improved it in EMQX 5.0.
Before we start, you should know how data is replicated in the EMQX cluster: EMQX Broker stores the runtime information about the topics and clients in Mnesia database, which helps replicate this data across the cluster.
What is Mnesia?
Let's discuss in more detail what Mnesia is, and how it works. Mnesia is an open-source database management system developed by Ericsson corporation as part of Open Telecom Platform. Originally, it was intended to handle configuration and runtime data in the ISP-grade telecom switches. Up to version 4.3, EMQX used it to store all kinds of runtime data, such as topics, routes, ACL rules, alarms and much more.
You are probably familiar with databases such as MySQL, Postgres, MongoDB, and in-memory stores like Redis and Memcached. Mnesia, on the other hand, remains relatively obscure. Nonetheless, it is unique in many ways, partly because it combines a lot of the features of the above products into a single neat application.
We'll start with a rather academic definition: Mnesia is an embedded, distributed, transactional, NoSQL database. That's quite a mouthful! So, let's unwrap what it all means.
Embedded
Let's start with the "embedded" part. The most widely used databases like MySQL and Postgres use a client-server model: the database runs in a separate process, oftentimes on a dedicated server, and the business applications interact with it by sending requests over the network or a UNIX domain socket and waiting for replies. This model is convenient in many regards, because it allows you to separate the business logic from the storage and manage them separately. However, it also has some downsides: interacting with the remote process inevitably adds latency to each request.
In contrast, embedded databases run in the same process as the business application. One notable example of an embedded database is SQLite. Mnesia also falls into this category: it runs in the same process as the rest of the EMQX applications. Reading data from a Mnesia table can be as fast as reading a local variable, so we can read from the database in hot spots without hurting performance.
Distributed
Previously we mentioned that Mnesia is a distributed database. It means the tables are replicated across different physical locations by the network. The type of distributed database where nodes don't share any physical resources, like RAM or disk, and coordination is done on the application level is called shared-nothing architecture (SN). This approach is often preferred because it doesn't require any specialized hardware and can scale horizontally.
Mnesia application, running alongside EMQX, helps to replicate the table updates across all nodes in the cluster over the Erlang distribution protocol. It means the business applications can read the updated data locally. It also helps with the fault-tolerance: the data is safe, as long as at least one node in the cluster is alive. EMQX relies on this feature to replicate the routing information across the cluster.
Transactional
Mnesia supports ACID transactions, which is a rather unique feature for an embedded database. It means multiple read and update operations can be grouped together. A Mnesia transaction is atomic (it must either be complete in its entirety or have no effect whatsoever), consistent (although the guarantees are laxer than in Postgres, for example), isolated (it does not affect other transactions) and durable. All these guarantees are preserved across the entire cluster.
EMQX uses Mnesia transactions in the places where data consistency is critical.
NoSQL
The traditional relational databases use a special query language called SQL to interact with the database. Often ORM is used to speed up the development. Mnesia, on the other hand, doesn't have a specialized query language: it uses Erlang (or Elixir) as a query language, so there is no need for an ORM. It operates with the Erlang terms directly, which makes integration with the business logic very smooth.
Architecture
In a Mnesia cluster all nodes are equal. Each one of them can store replicas of any table, start transactions and access the tables. The Mnesia cluster uses a full-mesh topology: every node talks to all the other nodes in the cluster. Every transaction is replicated to all the nodes in the cluster, as shown in the picture below:
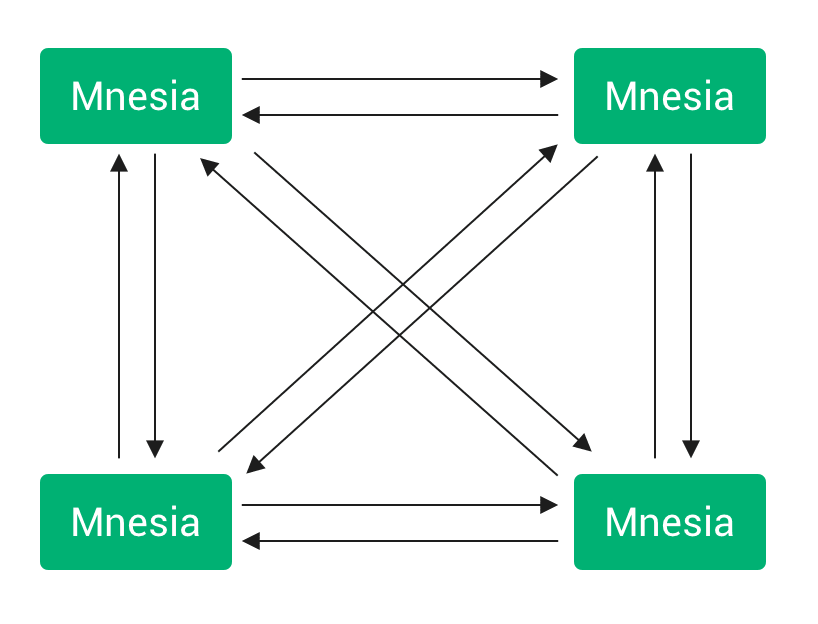
Mnesia cluster
In terms of CAP theorem (Consistency, Availability, Partition-tolerance: pick two), Mnesia defaults to AP.
Challenges
As we discussed above, the Mnesia database has a rather unusual set of features that we make use of in EMQX. Now it's time to talk about the downsides, and why we chose to invest in improving it.
Although Mnesia is hardware-agnostic, it was initially developed with a particular cluster architecture in mind: a collection of servers, interconnected by a fast, low-latency local area network.
Under the ideal conditions, mesh topology can reduce the transaction replication latency: all the communication between the nodes can be done in parallel, without any middlemen. However, it limits the horizontal scalability of the cluster, as the number of links between the nodes grows as a square of the number of nodes. Keeping all the nodes in a perfect sync comes at more and more costly, and the performance of the transactions drops.
Equal nature of the nodes also played along with the traditional cluster paradigm: it made replacing a single node easy, however, the number of nodes that can join the cluster simultaneously was limited.
Now we live in different times: clusters are deployed in geo-redundant cloud environments, everything is dynamic and ephemeral, nodes are running in the auto-scaling groups, and we expect them to come up and down all the time.
As a response to these challenges, we've developed an extension to Mnesia, called Mria.
Introducing Mria
Mria is an open-source extension to Mnesia that adds eventual consistency to the cluster.
Mria moves away from a full-mesh topology to a mesh+star topology. Each node assumes one of the two roles: core or replicant.
Core nodes behave much like regular Mnesia nodes: they are connected in a full mesh, and each node can initiate write transactions, hold locks, etc. Core nodes are expected to be more or less static and persistent.
Replicant nodes, on the other hand, don't participate in the transactions. They connect to one of the core nodes and passively replicate the transactions from it. This means replicant nodes aren't allowed to perform any write operations on their own. They instead ask a core node to update the data on their behalf. At the same time, they have a full local copy of the data, so the read access is just as fast.

Mria cluster
One can think of Mria as a combination of the client-server and embedded database: writes go through a server, but the reads are local.
This cluster topology addresses two problems:
- Horizontal scalability
- It enables cluster autoscaling
Since replicant nodes don't participate in writes, transaction latency doesn't suffer when more replicants are added to the cluster. This allows to create larger EMQX clusters.
Also, replicant nodes are designed to be ephemeral. Adding or removing them won't change the data redundancy, so they can be placed in an autoscaling group, thus enabling better DevOps practices.
In the next post, we will discuss in more detail how to configure EMQX to make full use of Mria.





Top comments (0)