We can extract all the text from the PDF file in Java applications by Spire.PDF. We can also extract some texts from the particular page or defined area from the PDF file. In this article, we will show you how to extract text in a PDF file in Java using Free Spire.PDF for Java library.
Dependencies
First of all, we need to add the needed dependencies to add Free Spire.PDF for Java into our Java project. There are two ways to do that.
If we use maven, we need to add the following code to your project's pom.xml file.
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>http://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.pdf.free</artifactId>
<version>2.6.3</version>
</dependency>
</dependencies>
For non-maven projects, download Free Spire.PDF for Java pack from the website and add Spire.Pdf.jar in the lib folder into our project as a dependency.
Firstly, view the sample PDF file.

Extract all texts from the whole PDF. Spire.PDF offers the method of page.extractText() to extract all texts in PDF easily.
import com.spire.pdf.*;
import com.spire.pdf.PdfPageBase;
import java.io.*;
public class extractAllTexts {
public static void main(String[] args) throws Exception{
String input = "Sample.pdf";
//Load the PDF file
PdfDocument pdf = new PdfDocument();
pdf.loadFromFile(input);
//Create a new txt file to save the extracted text
String result = "output/extractAllText.txt";
File file=new File(result);
if(!file.exists()){
file.delete();
}
file.createNewFile();
FileWriter fw=new FileWriter(file,true);
BufferedWriter bw=new BufferedWriter(fw);
//Extract text from all the pages on the PDF
PdfPageBase page;
for(int i=0;i<pdf.getPages().getCount();i++){
page=pdf.getPages().get(i);
String text = page.extractText(true);
bw.write(text);
}
bw.flush();
bw.close();
fw.close();
}
}

Extract text from specific area. We could define the special area from a single page of PDF, then to extract the text from this area by page.extractText(new Rectangle2D.Float(80, 200, 500, 200)) method.
import com.spire.pdf.*;
import java.awt.geom.Rectangle2D;
import java.io.*;
public class extractTextFromSpecificArea {
public static void main(String[] args) throws Exception{
String input = "Sample.pdf";
//Load the PDF file
PdfDocument pdf = new PdfDocument();
pdf.loadFromFile(input);
//Create a new txt file to save the extracted text
String result = "output/extractText.txt";
File file=new File(result);
if(!file.exists()){
file.delete();
}
file.createNewFile();
FileWriter fw=new FileWriter(file,true);
BufferedWriter bw=new BufferedWriter(fw);
//Get the first page
PdfPageBase page = pdf.getPages().get(0);
//Extract text from a specific rectangle area within the page
String text = page.extractText(new Rectangle2D.Float(80, 200, 500, 200));
bw.write(text);
bw.flush();
bw.close();
fw.close();
}
}

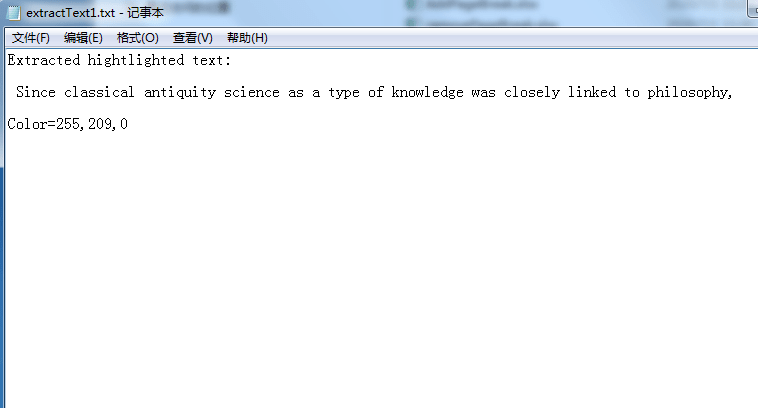
Extract highlighted text from PDF. Some PDF will add the highlighted color for some texts. Spire.PDF offers the method page.extractText(textMarkupAnnotation.getBounds()) to extract the highlighted text from the PDF.
import com.spire.pdf.*;
import java.io.*;import com.spire.pdf.annotations.*;
import com.spire.pdf.graphics.*;
public class extractHighlightedText {
public static void main(String[] args) throws Exception{
String input = "Sample.pdf";
//Load the PDF file
PdfDocument pdf = new PdfDocument();
pdf.loadFromFile(input);
//Create a new txt file to save the extracted text
String result = "output/extractText1.txt";
File file=new File(result);
if(!file.exists()){
file.delete();
}
file.createNewFile();
FileWriter fw=new FileWriter(file,true);
BufferedWriter bw=new BufferedWriter(fw);
bw.write("Extracted highlighted text:");
PdfPageBase page = pdf.getPages().get(0);
for (int i = 0; i < page.getAnnotationsWidget().getCount(); i++) {
if (page.getAnnotationsWidget().get(i) instanceof PdfTextMarkupAnnotationWidget) {
PdfTextMarkupAnnotationWidget textMarkupAnnotation = (PdfTextMarkupAnnotationWidget) page.getAnnotationsWidget().get(i);
bw.write(page.extractText(textMarkupAnnotation.getBounds()));
//Get the highlighted color
PdfRGBColor color = textMarkupAnnotation.getColor();
bw.write("Color="+(color.getR() & 0XFF) +","+(color.getG() & 0XFF)+","+(color.getB() & 0XFF)+"\n");
}
}
bw.flush();
bw.close();
fw.close();
}
}





Top comments (0)