This article was written by Aaron Xie and was originally published at Educative, Inc.
Many shudder at the thought of a coding interview. It can be stressful, grueling, and challenging. Oftentimes, it can be a struggle simply to know what topics to prepare. However today, you will be introduced to the primary data structures and algorithms that are tested in a coding interview. After reading this article, you should have a good idea of what you need to prepare for to land your dream job.
We will cover the following:
- Why should you learn data structures and algorithms?
- Understanding Big O notation
- Important data structures to learn
- Important algorithms to learn
- Other topics to cover
- How to ace your next coding interview
- Resources
Why should you learn data structures and algorithms?
The coding interview tests for your problem-solving abilities and understanding of computer science concepts. Usually, you are given about 30 - 45 minutes to solve one complex problem, but sometimes you will be given a few easier technical problems to solve.
This is where data structures and algorithms come in. These interviews will test you on topics such as linked lists, queues, sorting, searching, and much more, so it’s crucial to prepare. Not only do companies want to test your technical knowledge, but they also want to evaluate your problem-solving skills. If you get the job, you will often face bugs that you need to fix, and companies want to make sure that you can overcome these obstacles. Furthermore, you will often use specific data structures and algorithms to optimize your code so that it runs as efficiently as possible.
Understanding Big O notation
Big O notation is an asymptotic analysis that describes how long an algorithm takes to perform. In other words, it's used to talk about how efficient or complex an algorithm is.
Big O describes the execution time, or run time, of an algorithm relative to its input $N$ as the input increases. Though we can analyze an algorithm's efficiency using average-case and best-case, we typically use worst-case with Big O notation.
Today, you will learn about time complexity, but take note that space complexity is also an important concept to understand. Runtime complexity can be a difficult concept to grasp at first, so let's look at some examples
$O(1)$
public int findInt(int[] arr) {
return arr[0];
}
$O(1)$ describes an algorithm that always runs at a constant time no matter its input. The function will execute at the same time no matter if the array holds a thousand integers or one integer because it only takes one "step".
$O(N)$
public int func(int[] arr) {
for (int i = 1; i <= arr.length; i++) {
System.out.println(i);
}
}
$O(N)$ describes an algorithm whose runtime will increase linearly relative to the input $N$. The function above will take $N$ steps for $N$ values stored in the array. For example, if the array length is 1, the function will take 1 "step" to run, whereas if the array length is 1000, the function will take 1000 "steps" to run.
In the example provided, the array length is the input size, and the number of iterations is the runtime.
$O(N^2)$
public int func(int[] arr) {
for (int i = 1; i <= arr.length; i++) {
for (int i = 1; i <= arr.length; i++) {
System.out.println(i);
}
}
}
$O(N^2)$ describes a function whose runtime is proportional to the square of the input size. This runtime occurs when there is a nested loop such that the outer loop runs $N$ times, and the inner loop runs $N$ times for each iteration by the outer loop such that the function takes $N^2$ steps.
Some rules to remember
Ignore constants: When using Big O notation, you always drop the constants. So, even if the runtime complexity is $O(2N)$, we call it $O(N)$.
Drop less dominant terms: You only keep the most dominant term when talking Big O. For example, $O(N^3 + 50N +1 7)$ is simply $O(N^3)$. Here's the rule of thumb: $O(1)$ < $O(logN)$ < $O(N)$ < $O(NlogN)$ < $O(N^2)$ < $O(2^N)$ < $O(N!)$.
Want to read more about Big O notation? Check out our What is Big-O Notation article.

Important data structures to learn
In simplest terms, data structures are ways to organize and store data in a computer so that it be accessed and modified. You will learn the basics of the important data structures that are tested in the coding interview.
Arrays
An array is a collection of items of the same variable type that are stored sequentially in memory. It's one of the most popular and simple data structures and often used to implement other data structures.
Each item in an array is indexed starting with 0, and each item is known as an element. It's also important to note that in Java, you cannot change the size of an array. For dynamic sizes, it's recommended to use a List.

In the example above:
The length of the array is 5
The value at index 3 is 1
In Java, all values in this array must be an integer type
Initializing an array in Java:
int[] intArray = new int[14];
intArray[3] = 5;
intArray[4] = 3;
intArray[13] = 14;
// Indexes with no value are null
Common interview questions:
Find first non-repeating integer in an array
Rearrange array in decreasing order
Right rotate the array by one index
Maximum sum subarray using divide and conquer
Linked lists
A linked list is a linear sequence of nodes that are linked together. Each node contains a value and a pointer to the next node in the list. Unlike arrays, linked lists do not have indexes, so you must start at the first node and traverse through each node until you get to the $n$th node. At the end, the last node will point to a null value.
The first node is called the head, and the last node is called the tail. Below visualizes a singly linked list.

A linked list has a number of useful applications:
Implement stacks, queues, and hash tables
Create directories
Polynomial representation and arithmetic operations
Dynamic memory allocation
Basic implementation of a linked list in Java:
import java.io.*;
// Java program to implement
// a Singly Linked List
public class LinkedList {
Node head; // head of list
// Linked list Node.
// This inner class is made static
// so that main() can access it
static class Node {
int data;
Node next;
// Constructor
Node(int d)
{
data = d;
next = null;
}
}
// Method to insert a new node
public static LinkedList insert(LinkedList list, int data)
{
// Create a new node with given data
Node new_node = new Node(data);
new_node.next = null;
// If the Linked List is empty,
// then make the new node as head
if (list.head == null) {
list.head = new_node;
}
else {
// Else traverse till the last node
// and insert the new_node there
Node last = list.head;
while (last.next != null) {
last = last.next;
}
// Insert the new_node at last node
last.next = new_node;
}
// Return the list by head
return list;
}
// Method to print the LinkedList.
public static void printList(LinkedList list)
{
Node currNode = list.head;
System.out.print("LinkedList: ");
// Traverse through the LinkedList
while (currNode != null) {
// Print the data at current node
System.out.print(currNode.data + " ");
// Go to next node
currNode = currNode.next;
}
}
// Driver code
public static void main(String[] args)
{
/* Start with the empty list. */
LinkedList list = new LinkedList();
//
// ******INSERTION******
//
// Insert the values
list = insert(list, 1);
list = insert(list, 2);
list = insert(list, 3);
list = insert(list, 4);
list = insert(list, 5);
list = insert(list, 6);
list = insert(list, 7);
list = insert(list, 8);
// Print the LinkedList
printList(list);
}
}
Common interview questions:
Reverse a linked list
Find the middle value in a linked list
Remove loop in a linked list
Stacks
Stacks are linear data structures in a LIFO (last-in, first-out) order. Now, what does that mean? Imagine a stack of plates. The last plate that you put on top of the stack is the first one you take out. Stacks work that way: the last value you add is the first one you remove.
Think of a stack like a collection of items that we can add to and remove from. The most common functions in a stack are push, pop, isEmpty, and peek.

A stack has a number of useful applications:
Backtracking to a previous state
Expression evaluation and conversion
Common interview questions:
Use stack to check for balanced parenthesis
Implement two stacks in an array
Next greater element using a stack
Queues
Queues are very similar to stacks in that they both are linear data structures with dynamic size. However, queues are FIFO (first-in, first-out) data structures. To visualize this data structure, imagine you are lining up for a roller coaster. The first people that line up get to leave the line for the ride.
In this data structure, elements enter from the "back" and leave from the "front." The standard functions in a queue are enqueue, dequeue, rear, front, and isFull.

A queue has a number of useful applications:
When a resource is shared by multiple consumers
Create directories
When data is transferring asynchronously between two resources
Common interview questions:
Reverse first kth elements of a queue
Generate binary numbers from 1 to n using a queue
Graphs
A graph is a collection of vertices (nodes) that are connected by edges, creating a network.
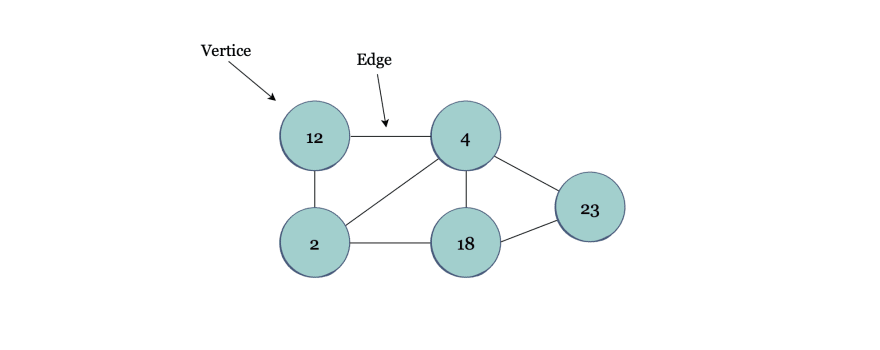
In the example above, the set of vertices are (12, 2, 4, 18, 23) and the edges are (12-2, 12-4, 2-4, 4-18, 4-23, 18-23, 2-18).
Graphs are very versatile data structures that can solve a plethora of real-world problems. Graphs are often used in social networks like LinkedIn or Facebook. With GraphQL on the rise, data is being organized as graphs, or networks.
Basic implementation of a graph:
import java.util.*;
class Graph {
// A utility function to add an edge in an
// undirected graph
static void addEdge(ArrayList<ArrayList<Integer> > adj,
int u, int v)
{
adj.get(u).add(v);
adj.get(v).add(u);
}
// A utility function to print the adjacency list
// representation of graph
static void printGraph(ArrayList<ArrayList<Integer> > adj)
{
for (int i = 0; i < adj.size(); i++) {
System.out.println("\nAdjacency list of vertex" + i);
for (int j = 0; j < adj.get(i).size(); j++) {
System.out.print(" -> "+adj.get(i).get(j));
}
System.out.println();
}
}
// Driver Code
public static void main(String[] args)
{
// Creating a graph with 5 vertices
int V = 5;
ArrayList<ArrayList<Integer> > adj
= new ArrayList<ArrayList<Integer> >(V);
for (int i = 0; i < V; i++)
adj.add(new ArrayList<Integer>());
// Adding edges one by one
addEdge(adj, 0, 1);
addEdge(adj, 0, 4);
addEdge(adj, 1, 2);
addEdge(adj, 1, 3);
addEdge(adj, 1, 4);
addEdge(adj, 2, 3);
addEdge(adj, 3, 4);
printGraph(adj);
}
}
Common interview questions:
Find shortest path between two vertices
Check if a path exists between two vertices
Find "mother vertex" in a graph
Hash tables
What's hashing?
Before we dive into hash tables, it's essential to understand what hashing is.
Hashing is the process of assigning an object into a unique index, known as a key. Each object is identified using a key-value pair, and the collection of objects is known as a dictionary.
A hash table is implemented by storing elements in an array and identifying them through a key. A hash function takes in a key and returns an index for which the value is stored.
So, whenever you input the key into the hash function, it will always return the same index, which will identify the associated element. Furthermore, if the hash function ever receives a unique key that returns an already used index, you can create a chain of elements with a linked list.
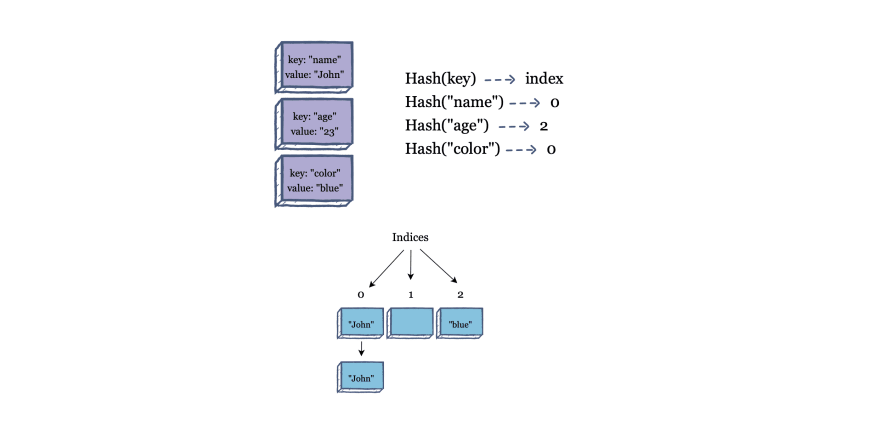
A hash table has a number of useful applications:
When a resource is shared by multiple consumers
Password verification
Linking file name and path
Common interview questions:
Find symmetric pairs in an array
Union and intersection of lists using hashing
Binary search tree
A binary search tree is a binary tree data structure made up of nodes. The nodes are arranged with the following properties:
The left subnode always contains values less than the parent node.
The right subnode always contains values greater than the parent node.
Both subnodes will also be binary search trees.
Binary search trees are used in many search applications and also used to determine objects that need to be rendered in a 3D game. This data structure is widely used in engineer projects because hierarchical data is so common.
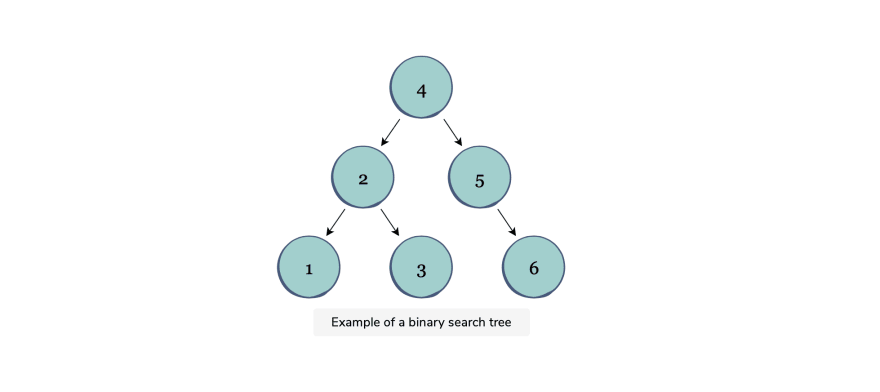
Common operations:
Search - searches for an element
Insert - inserts an element in the tree
Pre-order traversal - traverses the tree in a pre-order way
In-order traversal - traverses the tree in an in-order way
Post-order traversal - traverses the tree in a post-order way
Common interview questions:
Find kth maximum value in a binary search tree
Find the minimum value in a binary search tree
Traverse a given directory using breadth first search
Keep the learning going.
Learn the most asked interview questions without scrubbing through videos or grinding through hundreds of questions. Educative's text-based courses are easy to skim and feature live coding environments - making learning quick and efficient.
Grokking the Coding Interview: Patterns for Coding Questions

Important algorithms to learn
Recursion
Recursion is the practice in which a function calls itself directly or indirectly. The corresponding function that is called is known as the recursive function. While recursion is often associated as an algorithm, it may help to understand it as a way or methodology to solve a problem.
So why is recursion useful? Or what even is it? Let's look at how we can use recursion to calculate factorials as an example.
public static long factorial(int number){
//base case - factorial of 0 or 1 is 1
if(number <=1){
return 1;
}
return number*factorial(number - 1);
}
In the example above, the function starts at a number $n$. When the function is called, it will call $factorial(n - 1)$. Say the $n$ value is 4; the function will return
$4 * factorial(3) -> 4 * 3 * factorial(2) -> 4 * 3 * 2 * factorial(1)$
Once $n = 1$, the function will return $factorial(1) = 1$, and we get $factorial(4)$ equal to $4 * 3 * 2 * 1$, which is 24.
Here, you can see the power of recursion. It’s a widely used practice of solving a complex problem by breaking it into smaller instances of the problem until we can solve it. Using recursion, you can simplify a lot of complex problems that would be difficult otherwise.
Need more explanation? Read our What is Recursion? Edpresso shot here.
Bubble sort
Bubble sort is a simple sorting algorithm that swaps adjacent elements if they are in an incorrect order. The algorithm will iterate through an array multiple times until the elements are in the correct order.
Say, we have an array as seen below.

As the algorithm scans the array from left to right for the first iteration, starting at index 0, it compares index $i$ with index $i + 1$. At index 1, it will see that 11 is greater than 6 and swap the two.

As the algorithm continues scanning for the first iteration, it will see that 13 is greater than 10 and swap the two.
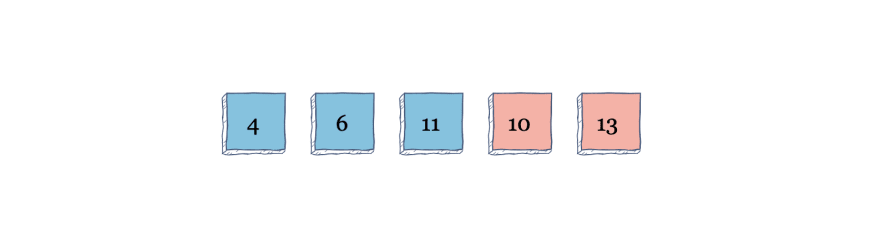
Next, it will go through the array for its second iteration. It will swap the values in index 2 and 3 when it sees that 11 is greater than 10.

The algorithm will scan the array for the third iteration, and because it does not need to make any more swaps for the third iteration, the algorithm will end.

As you can see, bubble sort can perform poorly when working with a lot more elements, making it primarily used as simply an educational tool. It has a runtime complexity of O($n^2$).
Implementing bubble sort:
public static void bubble_srt(int array[]) {
int n = array.length;
int k;
for (int m = n; m >= 0; m--) {
for (int i = 0; i < n - 1; i++) {
k = i + 1;
if (array[i] > array[k]) {
swapNumbers(i, k, array);
}
}
printNumbers(array);
}
}
Selection sort
Selection sort is an algorithm that splits a collection of elements into sorted and unsorted. During each iteration, the algorithm finds the smallest element in the unsorted group and moves it to the end of the sorted group.
Let's look at an example:

At first, all elements are unsorted. For the first iteration, the algorithm will go through each element and will identify 4 as the smallest value. The algorithm will swap the 11, the first element in the unsorted group with the lowest element in the unsorted group, 4.

Now, the sorted group is index 0, and the unsorted group is index 1 to index 3. For the second iteration, the algorithm will start at index 1 and scan the array, identifying 6 as the lowest value in the unsorted group. It will swap 11 and 6.

The sorted group is now index 0 to index 1, and the unsorted group is index 2 to index 3. For the third iteration, the algorithm will start at index 2, and find 11 as the lowest value. Because 11 is already in the right index, it will not move. With this, the algorithm ends.

Similar to bubble sort, selection sort is often a slow algorithm. It also has a runtime complexity of O($n^2$).
Implementing selection sort:
public static int[] doSelectionSort(int[] arr){
for (int i = 0; i < arr.length - 1; i++)
{
int index = i;
for (int j = i + 1; j < arr.length; j++)
if (arr[j] < arr[index])
index = j;
int smallerNumber = arr[index];
arr[index] = arr[i];
arr[i] = smallerNumber;
}
return arr;
}
}
Insertion Sort
Insertion sort is a simple sorting algorithm that builds the final array by sorting an element one at a time. How does it work?
Examines each element and compare it to the sorted elements on the left
Inserts the item in the correct order for the sorted elements
Let's look at an example.
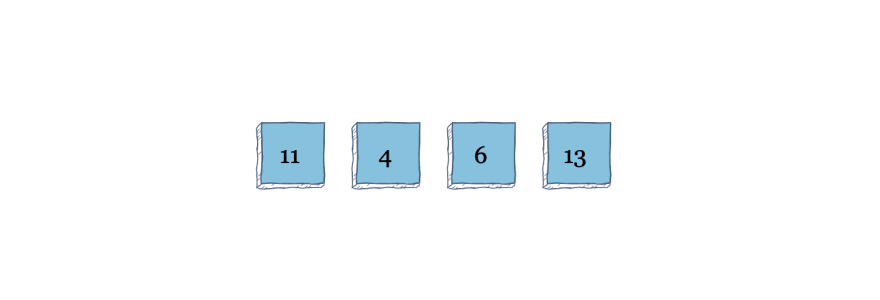
The algorithm starts at index 0 with the value 11. Because there are no elements to the left of 11, it stays where it is. Now, onto index 1. The value to the left of it is 11, which means we swap 11 and 4.
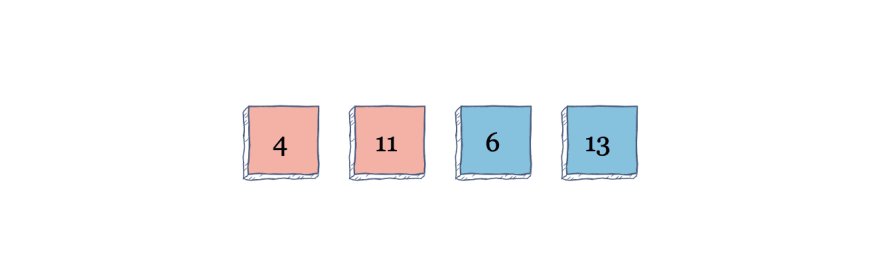
Again, the algorithm looks to the left of 4. Because there is no element to the left of 4, it stays where it is. Next, onto index 2. The element with the value 6 looks to left. Because it's less than 11, the two switch.

The element 6 looks to the left again, but because 4 is less than 6, it stays where it is. Next, we go to the element at index 4. The algorithm looks to the left, but because 11 is less than 13, it stays where it is. Now, the algorithm is done.

Insertion sort is almost always more efficient than bubble sort and selection sort, so it's used more often when working with a small number of elements. Similar to the two other sorting algorithms, insertion sort also has a quadratic runtime of O($n^2$).
Implementing insertion sort:
public static int[] doInsertionSort(int[] input){
int temp;
for (int i = 1; i < input.length; i++) {
for(int j = i ; j > 0 ; j--){
if(input[j] < input[j-1]){
temp = input[j];
input[j] = input[j-1];
input[j-1] = temp;
}
}
}
return input;
}
Binary search
Binary search is the most efficient searching algorithm to find an element. The algorithm works by comparing the middle element of an array or list to the target element. If the values are the same, the index of the element will be returned. If not, the list will be cut in half.
If the target value were less than the middle value, the new list would be the left half. If the target value were greater than the middle value, the new list would be the right half.
This process continues where you keep splitting a list and searching one of the halves until the search algorithm finds the target value and returns the position. The runtime complexity of this algorithm is $O(log2n)$. It's important to note that binary search only works if the list is already sorted.
To visualize a binary search, let's say that you have a sorted array with ten elements, and you are looking for an index of 33.

The middle value of this array is 16, and the algorithm compares it to 33. 33 is greater than 16, so the algorithm splits the array and searches in the second half.

The new middle value is 28. Because 33 is greater than 28, the algorithm searches in the second half of the array.

After the array is split once again into the right half, the new middle value is 33. The algorithm sees that the middle value and the target value are the same and returns the position of the element.
Implementing binary search:
int binarySearch(int arr[], int l, int r, int x)
{
if (r >= l) {
int mid = l + (r - l) / 2;
// If the element is present at the
// middle itself
if (arr[mid] == x)
return mid;
// If element is smaller than mid, then
// it can only be present in left subarray
if (arr[mid] > x)
return binarySearch(arr, l, mid - 1, x);
// Else the element can only be present
// in right subarray
return binarySearch(arr, mid + 1, r, x);
}
// We reach here when element is not present
// in array
return -1;
}
Other topics to cover
Keep in mind that the concepts we have covered today are simply an introduction. It’s important that you take a deeper dive into the concepts and practice coding questions. Below are other topics we suggest you familiarize yourself with:
How to ace your next coding interview
Plan ahead: The first thing you should do before anything is to develop a comprehensive plan to study. Identify the topics you feel that you need more practice on and create a schedule that you can stick to. You should be prepared to study consistently. In general, four to six weeks is an excellent timeline to prepare for your interview.
Programming language: Choose a programming language that you feel comfortable using. How easily could you write a solution in 25-or-so minutes using this language? Some popular languages that developers will use are Java, Python, Javascript, or C++.
The company: Before going into any interview, you should study the company. Learning about the company culture and values is incredibly important to make sure that you align with the company and so that you are more prepared on the non-technical aspect of the interview. You should also study the common problems that the company tests for. By doing this, you can do targeted practice to prepare for your interview
Behavioural interview: As much as you might feel like you are ready to tackle the technical interview, you can't forget the behavioral interview. With the behavioral interview, companies want to make sure that you are a good fit for the role and the company. Check out our behavioral interview guide to adequately prepare for the interview.
Now, you should have a good idea of what you need to do before the day of the interview. You have a lot of learning to do, but no worries. If you want to continue the learning, check out the resources provided by Coding Interview or our Python, Java, or Javascript interview preparation courses under our Programming Language Interview series.
Resources
Here's a list of resources for you regarding the coding interview and general computer science topics.
Articles
- Acing the Javascript Interview: Learn how to answer the top Javascript interview questions
- Behavioral Interviews: A guide to answering the behavioral questions in the interview
- Java Interview Prep: Learn 15 popular Java interview questions so that you're more prepared for your next interview





Top comments (4)
The question I ask myself right now: how many companies ask for algorithms in interviews, and how many companies have developers who actually use these algorithms in their daily jobs? I think the difference is pretty big (my experience, at least), and that's the real problem. Development is complex enough, I wouldn't advise beginner to learn all of that.
It's an impressive article, nonetheless!
I'll recommend people to review these topics with some frequency during their career, not only juniors. Because of two reasons, it's easy to forget them (it's not a day to day work), and because there are a lot of topics it becomes a huge task to review them in a few days/weeks before an interview.
Such a thorough and well-written article. Thanks for breaking everything down so comprehensively!
Glad you found it helpful!