![Cover image for REST API vs. GraphQL [comparison]](https://media.dev.to/cdn-cgi/image/width=1000,height=420,fit=cover,gravity=auto,format=auto/https%3A%2F%2Fdev-to-uploads.s3.amazonaws.com%2Fi%2F6841lwfyrmqm0kacndnv.png)
This article was originally published at https://www.blog.duomly.com/rest-api-vs-graphql-comparison/
Into to REST API vs. GraphQL
Since GraphQL was presented as a revolutionary alternative to RESTful API in 2015, there is a discussion between both solutions' supporters and opponents. As everything, RESTful API and GraphQL both have pros and cons, which need to be considered selecting proper solutions for the next project.
And as always, the choice should depend on the type of project that you are building. For some kind on the application, RESTful API will be a justified solution, when for the other type, GraphQL will be much better.
In this article, I’d like to explain what is RESTful API, and what is GraphQL deeper. Next, I’d like to go through the most significant differences between them.
Let’s start!
What is REST API?
REST API is a software architectural style or design pattern for API presented in 2000 by Roy Fielding. REST stands for Representational State Transfer, which means that the server transfers a representation of the state of the requested resource to the client after the API is called.
To make things clear, first, let me explain what an API is.
API is an application program interface used for communication between two software, mostly backend and frontend part of the application, but not only. Sometimes API interacts between two backends or backend and frontend of totally different applications.
REST API communicates using HTTP requests with GET, POST, PUT and DELETE methods, to manage data, mostly used in web services development. With REST API, we are sending the request from one software to resource URI, and then the second software resends resources as JSON, XML, or HTML.
In RESTful API, everything is considered a resource, which means an object about which API can provide information. Consider Twitter, where resources can be, for example, a user or a tweet.
Let’s take a look at the graphic representation of how REST API works and what happens in the call background.
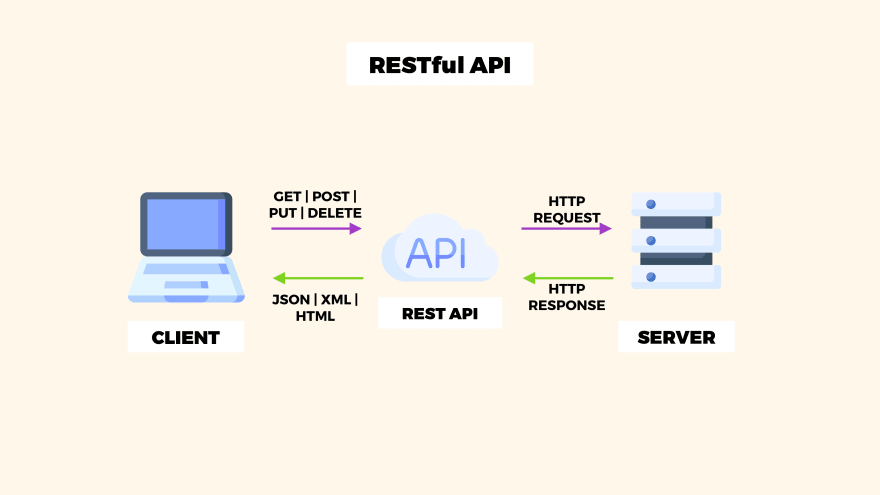
In the image, you can see that client is sending the request using one of the REST API methods, next server response with JSON, XML, or HTML data.
To make the API fully RESTful, we need to think about the set of constraints when we create it. Let’s go through the set of rules that help create the RESTful API that will be easy to use and understand.
REST API constraints
Let’s go through 6 RESTful API constraints now.
-
Uniform interface - this constraint divides for 4 elements:
- URI standard is used to identify the resource;
- manipulation of data should be defined by available methods (GET, PUT, POST, DELETE);
- self-descriptive messages;
- hyperlinks and URI templates to decouple the client from a specific URI structure;
- Stateless - every interaction between server and client should be stateless. It means that the server doesn’t store any data about the previous HTTP request, and it takes every request as new. If the application requires authentication to perform some data, the next calls should have all the required information to fulfill the request, like authorization or authentication details.
- Client-server - client and server part of the application should be independent, and the only common thing for the connections should be API’s URI.
- Cacheable - caching in REST API should be applied whenever it’s possible. It can be implemented on the client or server-side.
- Layered system - REST allows us to put the number of servers between the client sending the request and the server responding to the request. For example, user authentication can be performed on a different server then getting user orders.
- Code-on-demand (optional) - this constraint is options, but instead of JSON or XML, REST API can respond with executable code like UI widget code which can be rendered.
Anatomy of the REST API request
A REST API request can consist of 4 elements, but not each of them is required. Each API call needs an endpoint, which is the URL we request for. An endpoint consists of root-endpoint and path which determines the resource we are asking for.
Let’s take a look at the example.
https://jsonplaceholder.typicode.com/posts/:id
The next element required for the REST API call is the method. In this step, you have to consider what action will be performed. There are four most commonly used methods in the REST API:
GET - to get data from the server
POST - to create a new element
PUT - to update data
DELETE - to delete element
The next two elements of the REST API calls are not required, but very useful. Headers are used to pass additional data for different purposes like authentication or content type. And the last element is the body, which contains data that we want to send to the server.
Now, it’s time to go deeper into GraphQL.
What is GraphQL?
GraphQL was released in 2015 by Facebook, and it’s an open-source query language that helps us design, create, and consume API more efficiently. It’s strong competition for REST API.
In GraphQL, we send queries to the server and return JSON formatted data to the client. It was designed to solve issues with flexibility and efficiency, which sometimes happen with REST API.
When we define those queries, we are defining the shape of data that we will get as a response. We don’t need to ask for everything in the GraphQL query; we can select the data that will be useful in a particular call and get just the resources we need.
Another feature of GraphQL is the hierarchical nature, which means that data in the queries and responses reflect natural relationships between the objects. If user is related to orders, we can ask for the user's orders inside the user object.
How GraphQL works?
When we are using GraphQL, we need to define schemas, which are models of data that can be requested. The schema describes what fields the object has with the types, and it also defines what kind of queries can be sent.
When we have schemas defined, we can compare it with the queries to ensure that we will get the server's response.
When the GraphQL query is sent to the server, it’s interpreted against the schema and resolves the client's data.
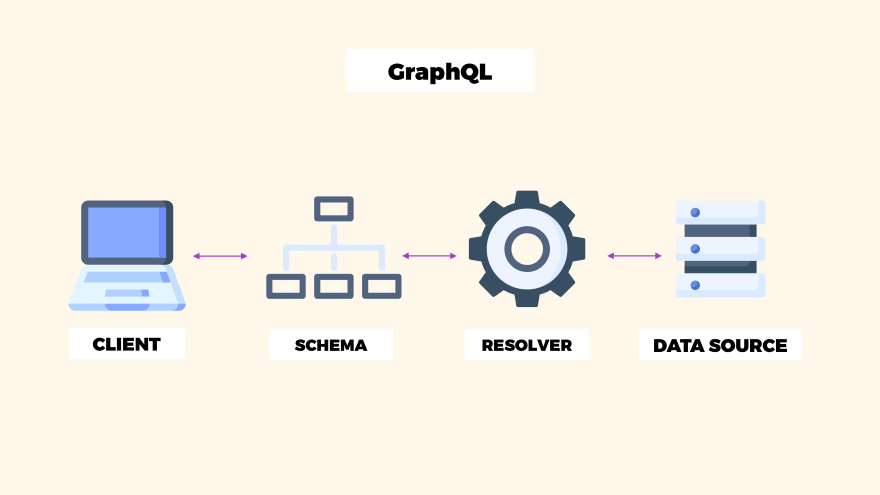
In the image above, you can see that the query is sent from the client, and it’s validated to the schema, then it’s resolved with the data source and returned to the client.
GraphQL may have three basic types of operations:
query - to read data
mutation - to save data
subscription - to receive real-time data
When we have an overview of REST API and GraphQL, let’s go throng the differences between both technologies, so we will be able to draw some conclusions.
Differences between REST and GraphQL
Let’s take a look at the differences between REST API and GraphQL.
1. Amount of endpoints
In REST API, there are multiple endpoints, and we are fetching resources by calling different paths for different kinds of data. For example, when we are calling http://api.com/users we call users resource, but we cannot call the same endpoint to get all the comments that the user wrote on the blog. For that, we have to call another endpoint http://api.com/users/:id/comments.
In GraphQL, there is just one endpoint; usually, it’s http://api.com/graphql. Requests are defined based on the queries or mutations. We can ask for different resources on the same endpoint, just chaining the query.
2. Data fetching
RESTful API is susceptible for over and under fetching, which is a very common issue with this API architecture.
Overfetching happened in a situation when we have to get more data that we exactly need. For example, when we want to just list users by username, we don’t need to get all data about users; we just need names. In REST API, it’s impossible to get just needed data.
Underfetching is a similar problem, but it happens when one endpoint provides less data that it’s necessary. Imagine a situation when we need to list posts of certain users. We need user data and posts. In that case, we have to call two endpoints for one view.
In GraphQL, we can create the query in a way that provides all the necessary data for a certain view, not too much, not too little. It helps reduce the number of HTTP requests, which improves the application's performance and security.
3.Versioning
When using REST API, you can sometimes realize v1 or v2 in the endpoints, which means that more versions of the API are created. It makes the code less readable and maintainable. In GraphQL, we can easily add new fields to the schema or mark the old ones as deprecated, and as a result, there’s no need for versioning.
Conclusion
Both REST API and GraphQL are great solutions for API, and both have their strengths and weaknesses.
GraphQL allows us to avoid under and over fetching, it’s just with just one endpoint, and it’s very easy to update.
On the other hand, REST API takes advantage of HTTP caching, content types, and status codes. It is still used very ofter in big and small projects, but it’s very important to know how to design and develop REST API, to make it efficient and understandable.
From my point of view, if you are a beginner without great knowledge in REST API, it’s safer to build GraphQL API because it’s easier to make it properly. But if you have time to research and learn, you could think of building your solution with REST.
And what’s your favorite method to build an API?

Thanks for reading,
Anna




Top comments (14)
After many APIs built, I just tried Graphql (Postgraphile). First impression is that I dont think I'll ever want to program another Restful API. I allways liked database design, frontend too. Writing Restful was boring but necessary work. Id do it impatiantly between writing a database and frontend. On this project, it seems I jumped straight from DB to frontend. I absolutely love it that source of the truth is now DB. Even comments there transform to Type comments using codegen. Roles, permissions, almost everything. Loving it so far.
Ill see about other aspects, but for coding itself Graphql (although with Postgraphile), is a clear winner.
Your very short on the GraphQL part. There are some disadvantages compared to REST. For example authentication can be done, but there is no standard way of doing it. Which might mean additional work for clients.
But GraphQL has introspection, which mean you can ask the endpoint which data it can give back, and which queries it has. The best thing is this is on the same endpoint. While similar solutions exist for REST, like Swagger, it's not as usable. And a lot of libraries can use the introspection to generate code.
Another you didn't mention is that GraphQL supports streaming data with subscriptions, altrough its not easy to implement correctly. Especially scaling is hard, and there are some discrepancies between servers and clients on the specifics.
Nice article! I don't have much experience with REST / GraphQL. Recently, working on defining and calling gRPC APIs. I find it very good. GraphQL looks similar in some aspects (like typed, schema...etc.). Being a long time C Programmer, I would prefer gRPC, GraphQL type of things over the REST & JSON :-).
I'm not sure what you meant by "In REST API, it’s impossible to get just needed data". We can create separate endpoints for those tasks. As far as I know, we can use GraphQL to limit the number of endpoints which will help us to cut the maintenance costs for separate endpoints.
Thank you! This is quite a nice content.
Thanks :)
NIce ...
thanks
What I still don’t understand: why does authentication in graphql considered a mutation? I mean, authentication does not save any data to the data persistence layer.
Maybe i do not understand the question correctly. :)
But GraphQL is just a query language.
Think of DB connections, you authenticate, and then you query, they are separate steps. :)
In practical GraphQL context, that usually means authentication headers and belongsTo DB relations in the models.
Hi Sebastian! Thank you for starting the discussion!
Adding more context into the question, what confuses me are why some library (e.g. Django GraphQL JWT django-graphql-jwt.domake.io/en/la... and Apollo Server apollographql.com/blog/setting-up-...) implement the TokenAuth as a mutation (mutation as in GraphQL mutation operation) instead of a GraphQL query operation.
What I understand from the term is "mutation" means change in the data. A TokenAuth operation to generate JWT shouldn't mutate any data, only checking the credentials provided whether it is valid or not, which should be more appropriate to use "query" operation instead.
Update:
Found the answer from here: stackoverflow.com/questions/501893...
An excerpt:
Thank you! Great comparison😊
Thanks <3
I remember when I first learned GraphQL a few years ago before it became popular. I had an interview at a tech company and they had never even heard of GraphQL 😂