
The Next Big Thing
OpenAI has opened its Image Generation API for commercial use. DALL-E enters a new round of development, becomes more stable, and allows products based on it to earn.
Microsoft would receive it at the forefront - link
Canva is already announce their own integration - link
What is DALL-E?
The current beta version of DALL-E is not the first one. The previous version was announced by OpenAI in January 2021. Although much has not changed under the hood, the possibilities have expanded significantly, and still, there are important changes. The new version, like the previous one, is based on a multimodal implementation of GPT-3 (Generative Pre-trained Transformer). The methods for validating the results remain the same and use CLIP (Contrastive Language-Image Pre-training) to filter and select the most appropriate generated image. What has changed from the most significantly thing is the reduction in the number of input parameters to run the algorithm from 12 billion parameters down to 3.5 billion parameters. And most importantly, DALL-E 2 uses a diffusion model conditioned on CLIP image embeddings, which, during inference, are generated from CLIP text embeddings by a prior model.
Hands-on experience
Let's jump to practice and try the OpenAI model and find out if is it so good.
First things first, there is nothing free in this world and for each request to DALL-E, you would need also to pay. Image models with the highest resolution 1024x1024 would cost you $0.020 each, but OpenAI has provided an option for us developers who want to try something new and is giving out a grant of $18 to play. I also want to note that OpenAI is not available in all countries, look for your country in the list - link.
You will not stay long on the OpenAI portal, here you only need to register and generate a key for authorization on the API. I think it took me no more than 3 minutes.
In the next step, let's write a simple script to make requests and get information from the API. I chose what was close at hand and decided to write in JS (Python and direct API requests are also available)
Create NPM project
npm init
Install openai package
npm i openai
Lets create index.js and add couple lines of code
import { Configuration, OpenAIApi } from "openai"
const prompt = process.env.DALLE_PROMPT
const configuration = new Configuration({
apiKey: process.env.DALLE_API_KEY
})
const openai = new OpenAIApi(configuration)
const response = await openai.createImage({
prompt,
n: 1,
size: "1024x1024",
response_format: "url"
})
response.data.data.forEach(img => console.log(img.url))
Environment variable
DALLE_API_KEY - API key generated on OpenAI portal
DALLE_PROMPT - prompt for model based on which it would generate image
Thats all, you are ready to challenge the machine learning models developed by OpenAI that was trained on at least 400 million pairs of images with text captions, which is configured by 3.5 billion parameters with only setting 2 environment variable.
Here is a documentation for more details what else you could configure - link
Hints, tricks and limitations
Officially, DALL-E is still in beta and is being actively developed. Therefore, it cannot always correctly interpret your requests, and sometimes it gives the same pictures for requests that are different in meaning. E.g.
prompt - cat is riding dog

prompt - dog is riding cat

Another thing that is not so good in detail, check the cat's faces in the “cat is riding dog” & “dog is riding cat” images. Looks creepy, is not it?)
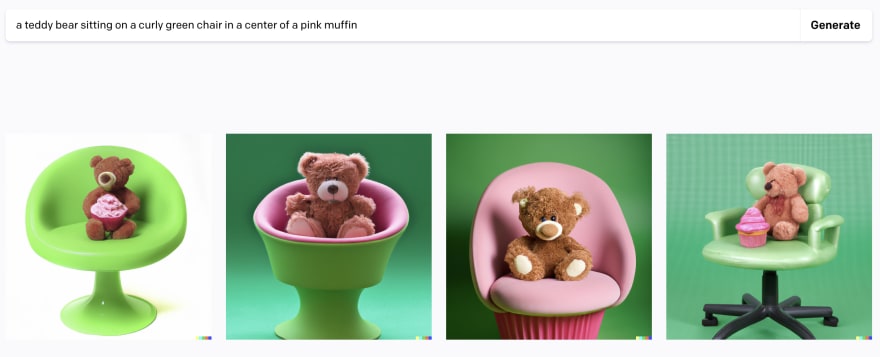
But what can I say for sure, the more details you give, the better the algorithm will cope, and the brighter and more interesting the picture will be. Give info about colors (yellow, green, etc), art types (digital, oil paint, photorealistic, etc), shapes & forms (round, square, etc), and so on. He will miss all the overabundance of description or objects, but if you perform several regenerations, he will still find a way to arrange them. Check example below
prompt - a teddy bear sitting on a curly green chair in a center of a pink muffin
Conclusion
So who was it for? Many, seeing graphic design platform at the beginning they will say that this is definitely for designers, but it seems to me that this is far and not only. This thing is definitely for creativity, for creating new digital things. But in addition to the final visual result that you will see, you also need to understand how we came to it. As DAL-E was created, he conquered a new peak of text-to-speech technologies. Those developments and the approaches that he used can now be used in other areas and products. It is definitely worth trying and creating your own masterpiece.
DALL-E page - https://openai.com/dall-e-2/
Play in browser - https://labs.openai.com/





Latest comments (1)
Great and useful masterpiece! Thanks!