
Intro
I've stumbled upon to quite a few questions on StackOverflow (shows only [bs4] tag but there's more in other tags)/other forums about extracting data from Google Scholar with and without API solution so that's why I decided to write DIY scripts and API solution which in this case is SerpApi plus to show the differences.
Every DIY example will be followed by a SerpApi example. Sometimes there'll be very few differences, however, under the hood (bypassing blocks) might be happening a lot of things in SerpApi examples.
If you found a bug while using SerpApi, you can open an issue at our public-roadmap.
Prerequisites
Basic knowledge scraping with CSS selectors
If you haven't scraped with CSS selectors, there's a dedicated blog post of mine about how to use CSS selectors when web-scraping that covers what it is, pros and cons, and why they're matter from a web-scraping perspective.
CSS selectors declare which part of the markup a style applies to thus allowing to extract data from matching tags and attributes.
Install libraries:
$ pip install requests parsel lxml beautifulsoup4 google-search-results
google-search-results is a SerpApi web-scraping package. SerpApi is a paid API that bypasses blocks (for example, IP blocks and CAPTCHA) from search engines.
In some cases, there're Parsel examples and in some examples in BeautifulSoup. People might used to BeautifulSoup however in some cases Parsel is quite handy. One basic example is handling None values. It's handled by the parsel, not on the client end via try/except or something else as you would do with BeautifulSoup. More in the code below.
💡 Did you know that parsel converts every CSS query to XPath under the hood using cssselect package?
Reduce the chance of being blocked
There's a chance that a request might be blocked. Have a look at how to reduce the chance of being blocked while web-scraping, there are eleven methods to bypass blocks from most websites and some of them will be covered in this blog post.
A few examples of bypassing blocks:
- proxy:
#https://docs.python-requests.org/en/master/user/advanced/#proxies
proxies = {
'http': os.getenv('HTTP_PROXY') # Or just type without os.getenv()
}
- browser automation such as
seleniumorplaywright. Adding proxy toseleniumorplaywright. - render HTML page with Python library such
requests-HTML.
SelectorGadgets extension
For the most part throughout this post, I was using select_one() or select() bs4 methods or css() parsel method to grab data from CSS selectors along with the help of SelectorGadge Chrome extension to pick CSS selectors by clicking on the desired HTML element in the browser.
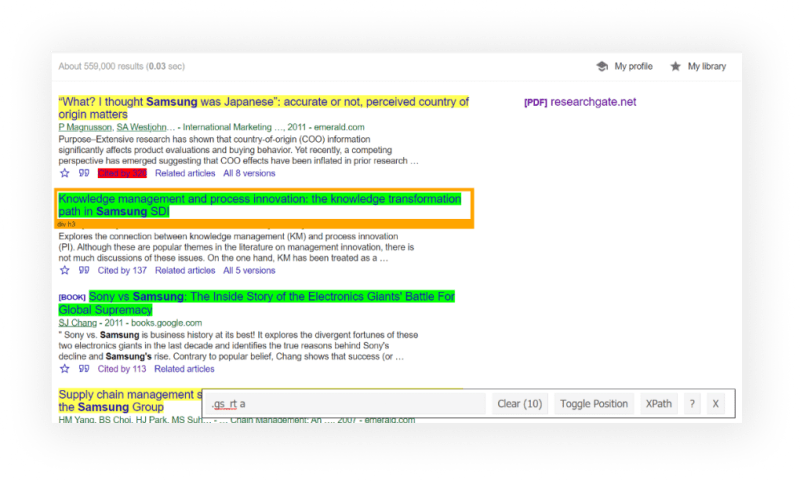
| Color | Explanation |
|---|---|
| 🔴 | excludes from search. |
| 🟡 | shows what be extracted. |
| 🟢 | included in the search. |
Scrape Google Scholar Organic Search Results
from bs4 import BeautifulSoup
import requests, lxml, os, json
def scrape_one_google_scholar_page():
# https://requests.readthedocs.io/en/latest/user/quickstart/#custom-headers
headers = {
'User-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36'
}
# https://requests.readthedocs.io/en/latest/user/quickstart/#passing-parameters-in-urls
params = {
'q': 'samsung', # search query
'hl': 'en' # language of the search
}
html = requests.get('https://scholar.google.com/scholar', headers=headers, params=params).text
soup = BeautifulSoup(html, 'lxml')
# JSON data will be collected here
data = []
# Container where all needed data is located
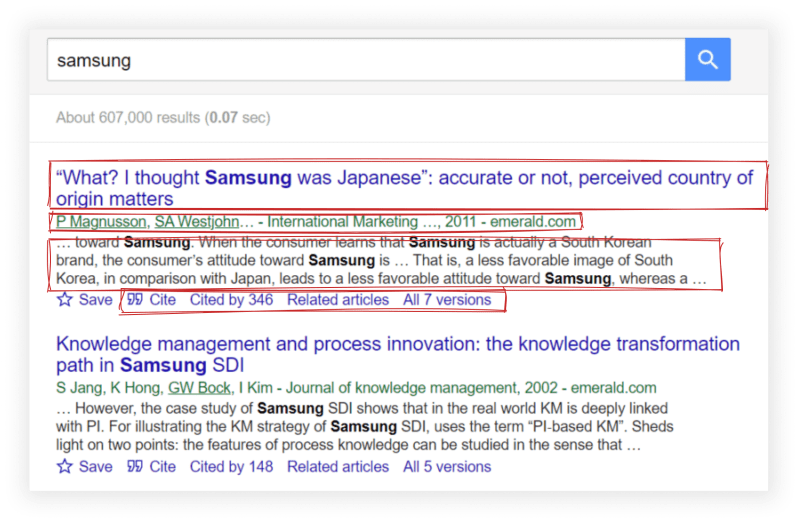
for result in soup.select('.gs_r.gs_or.gs_scl'):
title = result.select_one('.gs_rt').text
title_link = result.select_one('.gs_rt a')['href']
publication_info = result.select_one('.gs_a').text
snippet = result.select_one('.gs_rs').text
cited_by = result.select_one('#gs_res_ccl_mid .gs_nph+ a')['href']
try:
pdf_link = result.select_one('.gs_or_ggsm a:nth-child(1)')['href']
except:
pdf_link = None
data.append({
'title': title,
'title_link': title_link,
'publication_info': publication_info,
'snippet': snippet,
'cited_by': f'https://scholar.google.com{cited_by}',
'related_articles': f'https://scholar.google.com{related_articles}',
'all_article_versions': f'https://scholar.google.com{all_article_versions}',
"pdf_link": pdf_link
})
print(json.dumps(data, indent = 2, ensure_ascii = False))
# Part of the JSON Output:
'''
[
{
"title": "“What? I thought Samsung was Japanese”: accurate or not, perceived country of origin matters",
"title_link": "https://www.emerald.com/insight/content/doi/10.1108/02651331111167589/full/html",
"publication_info": "P Magnusson, SA Westjohn… - International Marketing …, 2011 - emerald.com",
"snippet": "Purpose–Extensive research has shown that country‐of‐origin (COO) information significantly affects product evaluations and buying behavior. Yet recently, a competing perspective has emerged suggesting that COO effects have been inflated in prior research …",
"cited_by": "https://scholar.google.com/scholar?cites=341074171610121811&as_sdt=2005&sciodt=0,5&hl=en",
"related_articles": "https://scholar.google.com/scholar?q=related:U8bh6Ca9uwQJ:scholar.google.com/&scioq=samsung&hl=en&as_sdt=0,5",
"all_article_versions": "https://scholar.google.com/scholar?cluster=341074171610121811&hl=en&as_sdt=0,5"
}
]
'''
Scrape Google Scholar Organic Search Results with Pagination
from bs4 import BeautifulSoup
import requests, lxml, os, json
def google_scholar_pagination():
# https://requests.readthedocs.io/en/latest/user/quickstart/#custom-headers
headers = {
'User-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36'
}
# https://requests.readthedocs.io/en/latest/user/quickstart/#passing-parameters-in-urls
params = {
'q': 'samsung medical center seoul semiconductor element simulation x-ray fetch',
'hl': 'en', # language of the search
'start': 0 # page number ⚠
}
# JSON data will be collected here
data = []
while True:
html = requests.get('https://scholar.google.com/scholar', headers=headers, params=params).text
selector = Selector(text=html)
print(f'extrecting {params["start"] + 10} page...')
# Container where all needed data is located
for result in selector.css('.gs_r.gs_or.gs_scl'):
title = result.css('.gs_rt').xpath('normalize-space()').get()
title_link = result.css('.gs_rt a::attr(href)').get()
publication_info = result.css('.gs_a').xpath('normalize-space()').get()
snippet = result.css('.gs_rs').xpath('normalize-space()').get()
cited_by_link = result.css('.gs_or_btn.gs_nph+ a::attr(href)').get()
data.append({
'page_num': params['start'] + 10, # 0 -> 1 page. 70 in the output = 7th page
'title': title,
'title_link': title_link,
'publication_info': publication_info,
'snippet': snippet,
'cited_by_link': f'https://scholar.google.com{cited_by_link}',
})
# check if the "next" button is present
if selector.css('.gs_ico_nav_next').get():
params['start'] += 10
else:
break
print(json.dumps(data, indent = 2, ensure_ascii = False))
google_scholar_pagination()
# Part of the output:
'''
extrecting 10 page...
extrecting 20 page...
extrecting 30 page...
extrecting 40 page...
extrecting 50 page...
extrecting 60 page...
extrecting 70 page...
extrecting 80 page...
extrecting 90 page...
[
{
"page_num": 10,
"title": "Comparative analysis of root canal filling debris and smear layer removal efficacy using various root canal activation systems during endodontic retreatment",
"title_link": "https://www.mdpi.com/891414",
"publication_info": "SY Park, MK Kang, HW Choi, WJ Shon - Medicina, 2020 - mdpi.com",
"snippet": "… According to a recent study, the GentleWave System was effective in retrieving separated … Energy dispersive X-ray spectroscopy (EDX) may be used for the microchemical analysis of …",
"cited_by_link": "https://scholar.google.com/scholar?cites=5221326408196954356&as_sdt=2005&sciodt=0,5&hl=en"
},
{
"page_num": 90,
"title": "Αυτόματη δημιουργία ερωτήσεων/ασκήσεων για εκπαιδευτικό σύστημα διδασκαλίας τεχνητής νοημοσύνης",
"title_link": "http://nemertes.lis.upatras.gr/jspui/handle/10889/9424",
"publication_info": "Ν Νταλιακούρας - 2016 - nemertes.lis.upatras.gr",
"snippet": "Στόχος της διπλωματικής είναι ο σχεδιασμός ,η ανάπτυξη και υλοποίηση ενός συστήματος παραγωγής ερωτήσεων/ασκήσεων από κείμενα φυσικής γλώσσας. Κύριος στόχος των …",
"cited_by_link": "https://scholar.google.com/scholar?q=related:1ovrKI-7xtUJ:scholar.google.com/&scioq=samsung+medical+center+seoul+semiconductor+element+simulation+x-ray+fetch&hl=en&as_sdt=0,5",
}
]
'''
Scrape Google Scholar Organic Results using SerpApi with Pagination
# Docs: https://serpapi.com/google-scholar-organic-results
from serpapi import GoogleScholarSearch
from urllib.parse import urlsplit, parse_qsl
import os, json
def serpapi_scrape_google_scholar_organic_results():
params = {
# https://docs.python.org/3/library/os.html
'api_key': os.getenv('API_KEY'), # serpapi api key
'engine': 'google_scholar', # serpapi parsing engine
'q': 'blizzard activision ser var server', # search query
'hl': 'en', # language
'start': 0 # first page
}
search = GoogleSearch(params) # where data extracts on the backend
organic_results_data = []
while True:
results = search.get_dict() # JSON -> Python dict
print(f'Currently extracting page #{results["serpapi_pagination"]["current"]}..')
for result in results['organic_results']:
position = result['position']
title = result['title']
publication_info_summary = result['publication_info']['summary']
result_id = result['result_id']
link = result.get('link')
result_type = result.get('type')
snippet = result.get('snippet')
try:
file_title = result['resources'][0]['title']
except: file_title = None
try:
file_link = result['resources'][0]['link']
except: file_link = None
try:
file_format = result['resources'][0]['file_format']
except: file_format = None
try:
cited_by_count = int(result['inline_links']['cited_by']['total'])
except: cited_by_count = None
cited_by_id = result.get('inline_links', {}).get('cited_by', {}).get('cites_id', {})
cited_by_link = result.get('inline_links', {}).get('cited_by', {}).get('link', {})
try:
total_versions = int(result['inline_links']['versions']['total'])
except: total_versions = None
all_versions_link = result.get('inline_links', {}).get('versions', {}).get('link', {})
all_versions_id = result.get('inline_links', {}).get('versions', {}).get('cluster_id', {})
organic_results_data.append({
'page_number': results['serpapi_pagination']['current'],
'position': position + 1,
'result_type': result_type,
'title': title,
'link': link,
'result_id': result_id,
'publication_info_summary': publication_info_summary,
'snippet': snippet,
'cited_by_count': cited_by_count,
'cited_by_link': cited_by_link,
'cited_by_id': cited_by_id,
'total_versions': total_versions,
'all_versions_link': all_versions_link,
'all_versions_id': all_versions_id,
'file_format': file_format,
'file_title': file_title,
'file_link': file_link,
})
if 'next' in results.get('serpapi_pagination', {}):
search.params_dict.update(dict(parse_qsl(urlsplit(results['serpapi_pagination']['next']).query)))
else:
break
return organic_results_data
print(json.dumps(serpapi_scrape_google_scholar_organic_results(), indent=2, ensure_ascii=False))
Scrape Google Scholar Cite Results

To make it work we need to create two functions:
- The first one will make a request to Google Scholar and extract all publication IDs.
- The second one will extract citation data.
Extracting IDs is nesseccery as it will be passed to the request URL in the second function otherwise we can't understand from which publication to extract citations.
from parsel import Selector
import requests, json
params = {
'q': 'blizzard', # search query
'hl': 'en' # language of the search
}
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36',
'referer': f"https://scholar.google.com/scholar?hl={params['hl']}&q={params['q']}"
}
# extracting citation ID from individual title
def parsel_get_cite_ids():
html = requests.get('https://scholar.google.com/scholar', params=params, headers=headers)
soup = Selector(text=html.text)
# returns a list of publication ID's -> U8bh6Ca9uwQJ
return soup.css('.gs_r.gs_or.gs_scl::attr(data-cid)').getall()
# extracting citattion data (MLA, APA...)
def parsel_scrape_cite_results():
citations = []
for cite_id in parsel_get_cite_ids():
html = requests.get(f'https://scholar.google.com/scholar?output=cite&q=info:{cite_id}:scholar.google.com', headers=headers)
selector = Selector(text=html.text)
# citations table
if selector.css('#gs_citt').get():
for result in selector.css('tr'):
institution = result.xpath('th/text()').get()
citation = result.xpath('td div/text()').get()
citations.append({'institution': institution, 'citation': citation})
return citations
print(json.dumps(parsel_scrape_cite_results(), indent=2, ensure_ascii=False))
# Part of the output:
'''
[
{
"institution": "MLA",
"citation": "King, Simon, et al. "The blizzard challenge 2008." (2008)."
}, ... other citations
{
"institution": "Vancouver",
"citation": "King S, Clark RA, Mayo C, Karaiskos V. The blizzard challenge 2008."
}
]
'''
Scrape Google Scholar Cite Results using SerpApi
# Docs: https://serpapi.com/google-scholar-cite-api
import json, os
from serpapi import GoogleScholarSearch
def organic_results():
params = {
# https://docs.python.org/3/library/os.html
'api_key': os.getenv('API_KEY'), # serpapi api key
'engine': 'google_scholar', # serpapi parsing engine
'q': 'blizzard', # search query
'hl': 'en' # language
}
search = GoogleScholarSearch(params)
results = search.get_dict()
return [result['result_id'] for result in results['organic_results']]
def cite_results():
citations = []
for citation_id in organic_results():
params = {
# https://docs.python.org/3/library/os.html
'api_key': os.getenv('API_KEY'),
'engine': 'google_scholar_cite',
'q': citation_id
}
search = GoogleScholarSearch(params)
results = search.get_dict()
for result in results['citations']:
institution = result['title']
citation = result['snippet']
citations.append({
'institution': institution,
'citations': citation
})
return citations
print(json.dumps(cite_results(), indent=2, ensure_ascii=False))
# Part of the output:
'''
[
{
"institution": "MLA",
"citation": "King, Simon, et al. "The blizzard challenge 2008." (2008)."
}, ... other citations
{
"institution": "Vancouver",
"citation": "King S, Clark RA, Mayo C, Karaiskos V. The blizzard challenge 2008."
}
]
'''
Scrape Google Scholar Profiles Results with Pagination
from parsel import Selector
import requests, json, re
def scrape_all_authors():
params = {
'view_op': 'search_authors', # author results
'mauthors': 'blizzard', # search query
'hl': 'en', # language of the search
'astart': 0 # page number
}
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36'
}
data = []
while True:
html = requests.get('https://scholar.google.com/citations', params=params, headers=headers, timeout=30)
soup = Selector(text=html.text)
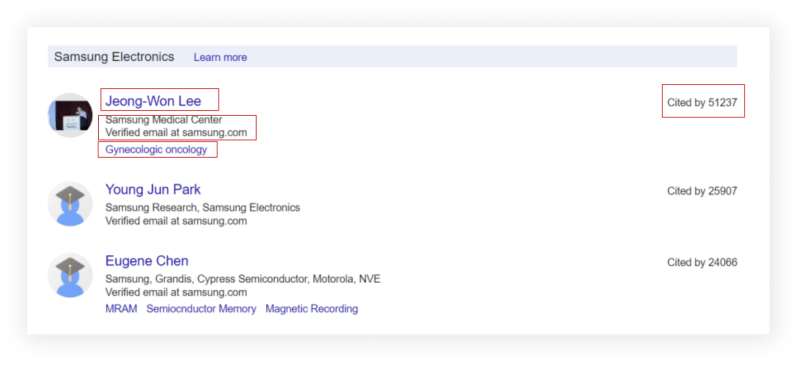
for author in soup.css('.gs_ai_chpr'):
name = author.css('.gs_ai_name a').xpath('normalize-space()').get()
link = f'https://scholar.google.com{author.css(".gs_ai_name a::attr(href)").get()}'
affiliations = author.css('.gs_ai_aff').xpath('normalize-space()').get()
email = author.css('.gs_ai_eml').xpath('normalize-space()').get()
try:
cited_by = re.search(r'\d+', author.css('.gs_ai_cby::text').get()).group() # Cited by 17143 -> 17143
except: cited_by = None
data.append({
'name': name,
'link': link,
'affiliations': affiliations,
'email': email,
'cited_by': cited_by
})
# check if the next arrow button is active by checking 'onclick' attribute
if soup.css('.gsc_pgn button.gs_btnPR::attr(onclick)').get():
# extracting next page token and passing to 'after_author' query URL parameter
params['after_author'] = re.search(r'after_author\\x3d(.*)\\x26', str(soup.css('.gsc_pgn button.gs_btnPR::attr(onclick)').get())).group(1) # -> XB0HAMS9__8J
params['astart'] += 10
else:
break
print(json.dumps(data, indent=2, ensure_ascii=False))
# Part of the output:
'''
[
{
"name": "Adam Lobel",
"link": "https://scholar.google.com/citations?hl=en&user=_xwYD2sAAAAJ",
"affiliations": "Blizzard Entertainment",
"email": "Verified email at AdamLobel.com",
"cited_by": "3357"
},
{
"name": "Vladimir Ivanov",
"link": "https://scholar.google.com/citations?hl=en&user=rddjbZcAAAAJ",
"affiliations": "Blizzard Entertainment",
"email": "",
"cited_by": null
}
]
Scrape Google Scholar Profiles using SerpApi
# Docs: https://serpapi.com/google-scholar-profiles-api
from serpapi import GoogleSearch
import os
def serpapi_scrape_all_authors():
params = {
# https://docs.python.org/3/library/os.html
'api_key': os.getenv('API_KEY'), # SerpApi API key
'engine': 'google_scholar_profiles', # profile results search engine
'mauthors': 'blizzard' # search query
}
search = GoogleSearch(params)
profile_results_data = []
profiles_is_present = True
while profiles_is_present:
profile_results = search.get_dict()
for profile in profile_results['profiles']:
print(f'Currently extracting {profile["name"]} with {profile["author_id"]} ID.')
thumbnail = profile['thumbnail']
name = profile['name']
link = profile['link']
author_id = profile['author_id']
affiliations = profile['affiliations']
email = profile.get('email')
cited_by = profile.get('cited_by')
interests = profile.get('interests')
profile_results_data.append({
'thumbnail': thumbnail,
'name': name,
'link': link,
'author_id': author_id,
'email': email,
'affiliations': affiliations,
'cited_by': cited_by,
'interests': interests
})
# # check if the next page is present in 'serpapi_pagination' dict key
if 'next' in profile_results['pagination']:
# split URL in parts as a dict() and update search 'params' variable to a new page
search.params_dict.update(dict(parse_qsl(urlsplit(profile_results['pagination']['next']).query)))
else:
profiles_is_present = False
return profile_results_data
print(json.dumps(serpapi_scrape_all_authors(), indent=2))
# Part of the output:
'''
[
{
"thumbnail": "https://scholar.googleusercontent.com/citations?view_op=small_photo&user=_xwYD2sAAAAJ&citpid=3",
"name": "Adam Lobel",
"link": "https://scholar.google.com/citations?hl=en&user=_xwYD2sAAAAJ",
"author_id": "_xwYD2sAAAAJ",
"email": "Verified email at AdamLobel.com",
"affiliations": "Blizzard Entertainment",
"cited_by": 3357,
"interests": [
{
"title": "Gaming",
"serpapi_link": "https://serpapi.com/search.json?engine=google_scholar_profiles&hl=en&mauthors=label%3Agaming",
"link": "https://scholar.google.com/citations?hl=en&view_op=search_authors&mauthors=label:gaming"
},
{
"title": "Emotion regulation",
"serpapi_link": "https://serpapi.com/search.json?engine=google_scholar_profiles&hl=en&mauthors=label%3Aemotion_regulation",
"link": "https://scholar.google.com/citations?hl=en&view_op=search_authors&mauthors=label:emotion_regulation"
}
]
},
{
"thumbnail": "https://scholar.google.com/citations/images/avatar_scholar_56.png",
"name": "Vladimir Ivanov",
"link": "https://scholar.google.com/citations?hl=en&user=rddjbZcAAAAJ",
"author_id": "rddjbZcAAAAJ",
"email": null,
"affiliations": "Blizzard Entertainment",
"cited_by": null,
"interests": [
{
"title": "Machine Learning",
"serpapi_link": "https://serpapi.com/search.json?after_author=tHCJAID___8J&engine=google_scholar_profiles&hl=en&mauthors=label%3Amachine_learning",
"link": "https://scholar.google.com/citations?hl=en&view_op=search_authors&mauthors=label:machine_learning"
},
{
"title": "Reinforcement Learning",
"serpapi_link": "https://serpapi.com/search.json?after_author=tHCJAID___8J&engine=google_scholar_profiles&hl=en&mauthors=label%3Areinforcement_learning",
"link": "https://scholar.google.com/citations?hl=en&view_op=search_authors&mauthors=label:reinforcement_learning"
},
{
"title": "Computer Vision",
"serpapi_link": "https://serpapi.com/search.json?after_author=tHCJAID___8J&engine=google_scholar_profiles&hl=en&mauthors=label%3Acomputer_vision",
"link": "https://scholar.google.com/citations?hl=en&view_op=search_authors&mauthors=label:computer_vision"
},
{
"title": "Cinematics",
"serpapi_link": "https://serpapi.com/search.json?after_author=tHCJAID___8J&engine=google_scholar_profiles&hl=en&mauthors=label%3Acinematics",
"link": "https://scholar.google.com/citations?hl=en&view_op=search_authors&mauthors=label:cinematics"
}
]
}
]
'''
Scrape Google Scholar Author Info
from parsel import Selector
import requests, os, json
def parsel_scrape_author_co_authors():
params = {
'user': '_xwYD2sAAAAJ', # user-id
'hl': 'en' # language
}
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36'
}
html = requests.get('https://scholar.google.com/citations', params=params, headers=headers, timeout=30)
selector = Selector(text=html.text)
author_info = {}
author_info['name'] = selector.css('#gsc_prf_in::text').get()
author_info['affiliation'] = selector.css('#gsc_prf_inw+ .gsc_prf_il::text').get()
author_info['email'] = selector.css('#gsc_prf_inw+ .gsc_prf_il::text').get()
author_info['website'] = selector.css('.gsc_prf_ila::attr(href)').get()
author_info['interests'] = selector.css('#gsc_prf_int .gs_ibl::text').getall(),
author_info['thumbnail'] = selector.css('#gsc_prf_pup-img::attr(src)').get()
print(json.dumps(author_info, indent=2, ensure_ascii=False))
parsel_scrape_author_co_authors()
# Output:
'''
{
"name": "Adam Lobel",
"affiliation": "Blizzard Entertainment",
"email": "Blizzard Entertainment",
"website": "https://twitter.com/GrowingUpGaming",
"interests": [
[
"Gaming",
"Emotion regulation"
]
],
"thumbnail": "https://scholar.googleusercontent.com/citations?view_op=view_photo&user=_xwYD2sAAAAJ&citpid=3"
}
'''
Scrape Google Scholar Author Info using SerpApi
# Docs: https://serpapi.com/google-scholar-author-api
import os, json
from serpapi import GoogleScholarSearch
def serpapi_scrape_author_info():
params = {
# https://docs.python.org/3/library/os.html
'api_key': os.getenv('API_KEY'),
"engine": "google_scholar_author",
"hl": "en",
"author_id": "_xwYD2sAAAAJ"
}
search = GoogleScholarSearch(params)
results = search.get_dict()
print(json.dumps(results['author'], indent=2, ensure_ascii=False))
serpapi_scrape_author_info()
'''
{
"name": "Adam Lobel",
"affiliations": "Blizzard Entertainment",
"email": "Verified email at AdamLobel.com",
"website": "https://twitter.com/GrowingUpGaming",
"interests": [
{
"title": "Gaming",
"link": "https://scholar.google.com/citations?view_op=search_authors&hl=en&mauthors=label:gaming",
"serpapi_link": "https://serpapi.com/search.json?engine=google_scholar_profiles&hl=en&mauthors=label%3Agaming"
},
{
"title": "Emotion regulation",
"link": "https://scholar.google.com/citations?view_op=search_authors&hl=en&mauthors=label:emotion_regulation",
"serpapi_link": "https://serpapi.com/search.json?engine=google_scholar_profiles&hl=en&mauthors=label%3Aemotion_regulation"
}
],
"thumbnail": "https://scholar.googleusercontent.com/citations?view_op=view_photo&user=_xwYD2sAAAAJ&citpid=3"
}
'''
Scrape Google Scholar All Author Articles
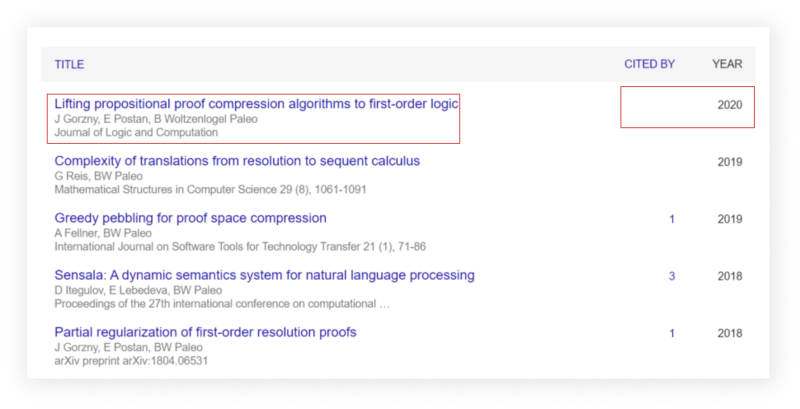
from parsel import Selector
import requests, os, json
def parsel_scrape_all_author_articles():
params = {
'user': '_xwYD2sAAAAJ', # user-id
'hl': 'en', # language
'gl': 'us', # country to search from
'cstart': 0, # articles page. 0 is the first page
'pagesize': '100' # articles per page
}
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36'
}
all_articles = []
while True:
html = requests.get('https://scholar.google.com/citations', params=params, headers=headers, timeout=30)
selector = Selector(text=html.text)
for index, article in enumerate(selector.css('.gsc_a_tr'), start=1):
article_title = article.css('.gsc_a_at::text').get()
article_link = f"https://scholar.google.com{article.css('.gsc_a_at::attr(href)').get()}"
article_authors = article.css('.gsc_a_at+ .gs_gray::text').get()
article_publication = article.css('.gs_gray+ .gs_gray::text').get()
cited_by_count = article.css('.gsc_a_ac::text').get()
publication_year = article.css('.gsc_a_hc::text').get()
all_articles.append({
'position': index,
'title': article_title,
'link': article_link,
'authors': article_authors,
'publication': article_publication,
'publication_year': publication_year,
'cited_by_count': cited_by_count
})
# this selector is checking for the .class that contains: 'There are no articles in this profile.'
# example link: https://scholar.google.com/citations?user=VjJm3zYAAAAJ&hl=en&cstart=500&pagesize=100
if selector.css('.gsc_a_e').get():
break
else:
params['cstart'] += 100 # paginate to the next page
# [:-1] doesn't pick last element which is not we want and don't contain any data.
print(json.dumps(all_articles[:-1], indent=2, ensure_ascii=False))
parsel_scrape_all_author_articles()
# Part of the output:
'''
[
{
"position": 1,
"title": "The benefits of playing video games.",
"link": "https://scholar.google.com/citations?view_op=view_citation&hl=en&user=_xwYD2sAAAAJ&pagesize=100&citation_for_view=_xwYD2sAAAAJ:u5HHmVD_uO8C",
"authors": "I Granic, A Lobel, RCME Engels",
"publication": "American psychologist 69 (1), 66",
"publication_year": "2014",
"cited_by_count": "2669"
},
{
"position": 23,
"title": "The Relation Between Gaming and the Development of Emotion Regulation Skills",
"link": "https://scholar.google.com/citations?view_op=view_citation&hl=en&user=_xwYD2sAAAAJ&pagesize=100&citation_for_view=_xwYD2sAAAAJ:ufrVoPGSRksC",
"authors": "A Lobel",
"publication": null,
"publication_year": null,
"cited_by_count": null
}
]
'''
Scrape Google Scholar All Author Articles using SerpApi
# Docs: https://serpapi.com/google-scholar-author-api
from serpapi import GoogleScholarSearch
from urllib.parse import urlsplit, parse_qsl
import os, json
def serpapi_scrape_articles():
params = {
# https://docs.python.org/3/library/os.html
'api_key': os.getenv('API_KEY'), # your serpapi api key
'engine': 'google_scholar_author', # serpapi parsing engine
'hl': 'en', # language of the search
'author_id': '_xwYD2sAAAAJ', # author ID
'start': '0', # page number: 0 - first, 1 second and so on.
'num': '100' # number of articles per page
}
search = GoogleScholarSearch(params)
all_articles = []
while True:
results = search.get_dict()
for article in results['articles']:
title = article.get('title')
link = article.get('link')
authors = article.get('authors')
publication = article.get('publication')
citation_id = article.get('citation_id')
year = article.get('year')
cited_by_count = article.get('cited_by').get('value')
all_articles.append({
'title': title,
'link': link,
'authors': authors,
'publication': publication,
'citation_id': citation_id,
'cited_by_count': cited_by_count,
'year': year
})
# check if the next page is present in 'serpapi_pagination' dict key
if 'next' in results.get('serpapi_pagination', []):
# split URL in parts as a dict() and update 'search' variable to a new page
search.params_dict.update(dict(parse_qsl(urlsplit(results['serpapi_pagination']['next']).query)))
else:
break
print(json.dumps(all_articles, indent=2, ensure_ascii=False))
serpapi_scrape_articles()
# Part of the output:
'''
[
{
"title": "The benefits of playing video games.",
"link": "https://scholar.google.com/citations?view_op=view_citation&hl=en&user=_xwYD2sAAAAJ&pagesize=100&citation_for_view=_xwYD2sAAAAJ:u5HHmVD_uO8C",
"authors": "I Granic, A Lobel, RCME Engels",
"publication": "American psychologist 69 (1), 66, 2014",
"citation_id": "_xwYD2sAAAAJ:u5HHmVD_uO8C",
"cited_by_count": 2669,
"year": "2014"
},
{
"title": "The Relation Between Gaming and the Development of Emotion Regulation Skills",
"link": "https://scholar.google.com/citations?view_op=view_citation&hl=en&user=_xwYD2sAAAAJ&pagesize=100&citation_for_view=_xwYD2sAAAAJ:ufrVoPGSRksC",
"authors": "A Lobel",
"publication": null,
"citation_id": "_xwYD2sAAAAJ:ufrVoPGSRksC",
"cited_by_count": null,
"year": ""
}
]
'''
Scrape Google Scholar Cited by, Graph and Public Access
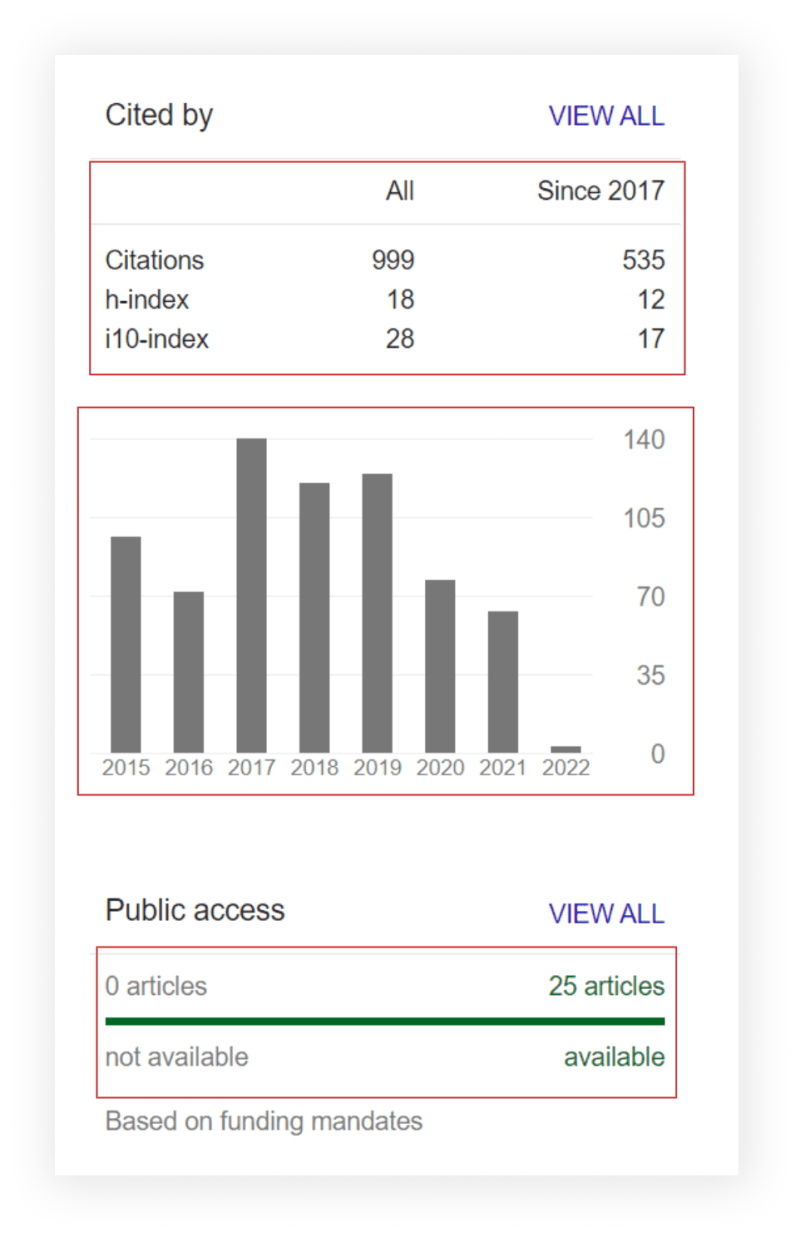
from parsel import Selector
import requests, os, json
def parsel_scrape_author_cited_by_graph():
params = {
'user': '_xwYD2sAAAAJ', # user-id
'hl': 'en' # language
}
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36'
}
html = requests.get('https://scholar.google.com/citations', params=params, headers=headers, timeout=30)
selector = Selector(text=html.text)
data = {
'cited_by': [],
'graph': []
}
since_year = selector.css('.gsc_rsb_sth~ .gsc_rsb_sth+ .gsc_rsb_sth::text').get().lower().replace(' ', '_')
for cited_by_public_access in selector.css('.gsc_rsb'):
data['cited_by'].append({
'citations_all': cited_by_public_access.css('tr:nth-child(1) .gsc_rsb_sc1+ .gsc_rsb_std::text').get(),
f'citations_since_{since_year}': cited_by_public_access.css('tr:nth-child(1) .gsc_rsb_std+ .gsc_rsb_std::text').get(),
'h_index_all': cited_by_public_access.css('tr:nth-child(2) .gsc_rsb_sc1+ .gsc_rsb_std::text').get(),
f'h_index_since_{since_year}': cited_by_public_access.css('tr:nth-child(2) .gsc_rsb_std+ .gsc_rsb_std::text').get(),
'i10_index_all': cited_by_public_access.css('tr~ tr+ tr .gsc_rsb_sc1+ .gsc_rsb_std::text').get(),
f'i10_index_since_{since_year}': cited_by_public_access.css('tr~ tr+ tr .gsc_rsb_std+ .gsc_rsb_std::text').get(),
'articles_num': cited_by_public_access.css('.gsc_rsb_m_a:nth-child(1) span::text').get().split(' ')[0],
'articles_link': f"https://scholar.google.com{cited_by_public_access.css('#gsc_lwp_mndt_lnk::attr(href)').get()}"
})
for graph_year, graph_yaer_value in zip(selector.css('.gsc_g_t::text'), selector.css('.gsc_g_al::text')):
data['graph'].append({
'year': graph_year.get(),
'value': int(graph_yaer_value.get())
})
print(json.dumps(data, indent=2, ensure_ascii=False))
parsel_scrape_author_cited_by_graph()
# Output:
'''
{
"cited_by": [
{
"citations_all": "3363",
"citations_since_since_2017": "2769",
"h_index_all": "10",
"h_index_since_since_2017": "10",
"i10_index_all": "11",
"i10_index_since_since_2017": "10",
"articles": {
"available": 1,
"not_available": 0
},
"articles_link": "https://scholar.google.com/citations?view_op=list_mandates&hl=en&user=_xwYD2sAAAAJ"
}
],
"graph": [
{
"year": "2014",
"value": 69
},
{
"year": "2015",
"value": 190
},
{
"year": "2016",
"value": 243
},
{
"year": "2017",
"value": 343
},
{
"year": "2018",
"value": 435
},
{
"year": "2019",
"value": 563
},
{
"year": "2020",
"value": 516
},
{
"year": "2021",
"value": 557
},
{
"year": "2022",
"value": 352
}
]
}
'''
Scrape Google Scholar Author Cited By, Graph and Public Access using SerpApi
# Docs: https://serpapi.com/google-scholar-author-api
import os, json
from serpapi import GoogleScholarSearch
def serpapi_scrape_author_cited_by_graph():
params = {
# https://docs.python.org/3/library/os.html
'api_key': os.getenv('API_KEY'),
'engine': 'google_scholar_author',
'author_id': 'EicYvbwAAAAJ',
'hl': 'en'
}
search = GoogleScholarSearch(params)
results = search.get_dict()
data = {
'cited_by': [],
'public_access': {},
'graph': []
}
data['cited_by'] = results['cited_by']['table']
data['public_access']['link'] = results['public_access']['link']
data['public_access']['articles_available'] = results['public_access']['available']
data['public_access']['articles_not_available'] = results['public_access']['not_available']
data['graph'] = results['cited_by']['graph']
print(json.dumps(data, indent=2, ensure_ascii=False))
serpapi_scrape_author_cited_by_graph()
# Output:
'''
{
"cited_by": [
{
"citations": {
"all": 487128,
"since_2017": 183326
}
},
{
"h_index": {
"all": 319,
"since_2017": 194
}
},
{
"i10_index": {
"all": 1149,
"since_2017": 932
}
}
],
"public_access": {
"link": "https://scholar.google.com/citations?view_op=list_mandates&hl=en&user=EicYvbwAAAAJ",
"articles_available": 522,
"articles_not_available": 32
},
"graph": [
{
"year": 1994,
"citations": 1537
},
{
"year": 1995,
"citations": 1921
},
{
"year": 1996,
"citations": 2202
},
{
"year": 1997,
"citations": 2979
},
{
"year": 1998,
"citations": 3500
},
{
"year": 1999,
"citations": 4187
},
{
"year": 2000,
"citations": 5629
},
{
"year": 2001,
"citations": 6242
},
{
"year": 2002,
"citations": 7213
},
{
"year": 2003,
"citations": 7863
},
{
"year": 2004,
"citations": 8995
},
{
"year": 2005,
"citations": 9889
},
{
"year": 2006,
"citations": 11674
},
{
"year": 2007,
"citations": 12879
},
{
"year": 2008,
"citations": 15212
},
{
"year": 2009,
"citations": 17043
},
{
"year": 2010,
"citations": 18213
},
{
"year": 2011,
"citations": 20568
},
{
"year": 2012,
"citations": 22596
},
{
"year": 2013,
"citations": 25036
},
{
"year": 2014,
"citations": 26488
},
{
"year": 2015,
"citations": 28138
},
{
"year": 2016,
"citations": 28442
},
{
"year": 2017,
"citations": 28817
},
{
"year": 2018,
"citations": 30272
},
{
"year": 2019,
"citations": 31383
},
{
"year": 2020,
"citations": 32410
},
{
"year": 2021,
"citations": 35746
},
{
"year": 2022,
"citations": 24456
}
]
}
'''
Scrape Google Scholar Co-Authors from Author Page
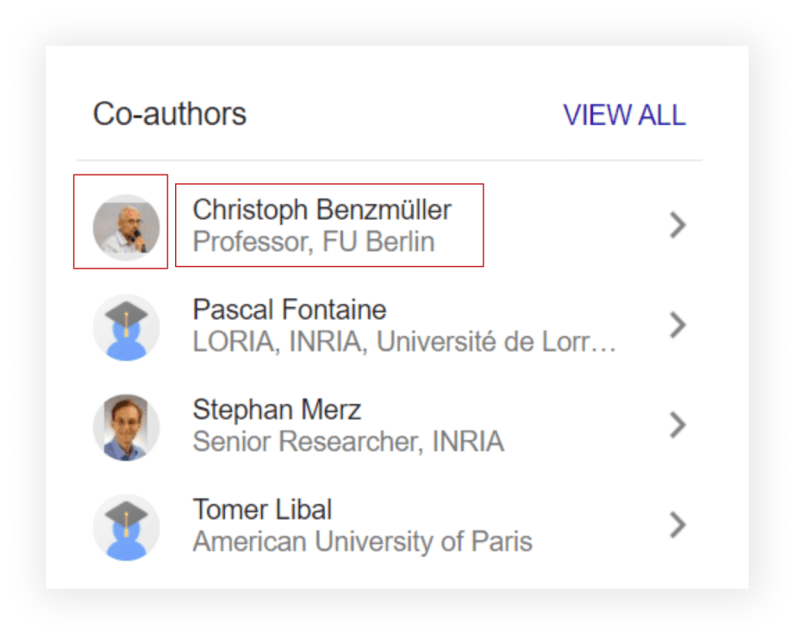
from parsel import Selector
import requests, os, json, re
def parsel_scrape_author_co_authors():
params = {
'user': '_xwYD2sAAAAJ', # user-id
'hl': 'en' # language
}
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36'
}
co_authors = []
html = requests.get('https://scholar.google.com/citations', params=params, headers=headers, timeout=30)
selector = Selector(text=html.text)
for result in selector.css('.gsc_rsb_aa'):
co_authors.append({
'name': result.css('.gsc_rsb_a_desc a::text').get(),
'title': result.css('.gsc_rsb_a_ext::text').get(),
'link': f"https://scholar.google.com{result.css('.gsc_rsb_a_desc a::attr(href)').get()}",
'email': result.css('.gsc_rsb_a_ext.gsc_rsb_a_ext2::text').get(),
# https://regex101.com/r/awJNhL/1
# extracting user ID and passing to 'user' URL parameter
'thumbnail': f"https://scholar.googleusercontent.com/citations?view_op=view_photo&user={re.search(r'user=(.*)&', result.css('.gsc_rsb_a_desc a::attr(href)').get()).group(1)}"
})
print(json.dumps(co_authors, indent=2, ensure_ascii=False))
parsel_scrape_author_co_authors()
# Part of the output:
'''
[
{
"name": "Isabela Granic",
"title": "Radboud University Nijmegen",
"link": "https://scholar.google.com/citations?user=4T5cjVIAAAAJ&hl=en",
"email": "Verified email at pwo.ru.nl",
"thumbnail": "https://scholar.googleusercontent.com/citations?view_op=view_photo&user=4T5cjVIAAAAJ"
}, ... other authors
{
"name": "Esther Steenbeek-Planting",
"title": "Postdoctoral researcher Max Planck Institute for Psycholinguistics / Donders Insitute for Brain, Cognition and Behaviour, Centre for Cognition",
"link": "https://scholar.google.com/citations?user=IsC9Le8AAAAJ&hl=en",
"email": "Verified email at donders.ru.nl",
"thumbnail": "https://scholar.googleusercontent.com/citations?view_op=view_photo&user=IsC9Le8AAAAJ"
}
]
'''
Scrape Google Scholar Co-Authors from Author page using SerpApi
# Docs: https://serpapi.com/google-scholar-author-api
from serpapi import GoogleSearch
import os, json
def serpapi_scrape_author_co_author():
params = {
# https://docs.python.org/3/library/os.html
'api_key': os.getenv('API_KEY'),
'engine': 'google_scholar_author',
'hl': 'en',
'author_id': '_xwYD2sAAAAJ'
}
search = GoogleScholarSearch(params)
results = search.get_dict()
print(json.dumps(results['co_authors'], indent=2, ensure_ascii=False))
serpapi_scrape_author_co_author()
# Part of the output:
'''
[
{
"name": "Isabela Granic",
"link": "https://scholar.google.com/citations?user=4T5cjVIAAAAJ&hl=en",
"serpapi_link": "https://serpapi.com/search.json?author_id=4T5cjVIAAAAJ&engine=google_scholar_author&hl=en",
"author_id": "4T5cjVIAAAAJ",
"affiliations": "Radboud University Nijmegen",
"email": "Verified email at pwo.ru.nl",
"thumbnail": "https://scholar.googleusercontent.com/citations?view_op=small_photo&user=4T5cjVIAAAAJ&citpid=4"
}, ... other authors
{
"name": "Esther Steenbeek-Planting",
"link": "https://scholar.google.com/citations?user=IsC9Le8AAAAJ&hl=en",
"serpapi_link": "https://serpapi.com/search.json?author_id=IsC9Le8AAAAJ&engine=google_scholar_author&hl=en",
"author_id": "IsC9Le8AAAAJ",
"affiliations": "Postdoctoral researcher Max Planck Institute for Psycholinguistics / Donders Insitute for Brain, Cognition and Behaviour, Centre for Cognition",
"email": "Verified email at donders.ru.nl",
"thumbnail": "https://scholar.googleusercontent.com/citations?view_op=small_photo&user=IsC9Le8AAAAJ&citpid=2"
}
]
'''
Links
Add a Feature Request💫 or a Bug🐞




Top comments (27)
Thasksful dear Dmitriy for a great post.
I have two problems when scraping profiles:
1_ When I use your code it returns 0 pages (i don't want to use serpapi) or "unusual traffic", I couldn't solve it. ( maybe I have been blocked by google).
2_ I wrote a code that works for me by Urllib, but now I notice a problem that the query just returns a matching case, and doesn't return a substring, for ex. I looking for ecology at Michigan State University, and as a result, it doesn't return "Scott C Stark", but if I write exactly "Tropical_Forest_Ecology" then it returns "Scott C Stark".
How do I solve it that returns any word even in substring?
Hey, @mohammadreza20 🙂
Yes, most likely you get blocked by Google. But I don't have enough context to give a proper answer 🙂
Have a look at
scrape-google-scholar-pycustom backend solution. It usesselenium-stealthunder the hood which bypasses cloudflare captcha, and other captchas (and IP rate limits).It's a package of mine. Note that it's in early alpha. Open issue if you found and bugs.
Without seeing your code I can only give you a very generic answer which wouldn't be helpful. Show code where you have difficulties if you want a deeper answer.
@dmitryzub Thank you for your response.
The question 2 is important for me but i couldn't solve it,
my code:
Hi Dmitriy,
Thank you for your very useful article!
However, whenever using beautifulsoup I can only scrape the first page when scraping a profile for example. Or if I need to scrape citations from a specific author, this only scrapes the first few citations instead of all of them. How can I scrape all the results (in multiple pages using beautifulsoup or SerpApi?
Thanks!
Hi @rafambraga,
Thank you for finding it helpful! Yes, the example I've shown in this blog post scrapes only first profiles page. This blog post is old and needs an upgrade.
I've answered Stackoverflow question about scraping profile results from all pages using both
bs4and SerpApi with example in the online IDE.About citations. I've also written a code snippet to scrape citations in
bs4. Note that examples scrapes only Bibtex data. You need add a few lines of code to scrape all of them.Besides that, there's also a dedicated blog posts on scrape historic Google Scholar results using Python and scrape all Google Scholar Profile, Author Results to CSV with Python and SerpApi.
If you need to scrape profiles from a certain university, there's also a dedicated scrape Google Scholar Profiles from a certain University in Python blog post just about it with a step-by-step explanation 👀
Do you have any recommendations for scraping all pages of an organic search result? I tried adding "start": 0 into the parameters and just manually changing that but it seems to repeat results occasionally. I also tried to follow your Scrape historic Google Scholar results using Python script but keep getting the error KeyError: 'serpapi_pagination'
Thanks for any help you can provide!
@dlittlewood12 Thank you for reaching out!
Most likely you're getting an
KeyError: 'serpapi_pagination'error is that you need to pass yourAPI_KEYtoos.getenv("API_KEY"). In the terminal, typeAPI_KEY=<your-api-key> python your-script-file.pyOr remove it completely and pass api key as a string inside
paramsdict, for example:"api_key": "2132414122asdsadadaa"Let me know if answers your question 🎈
@rafambraga I've just published major updates to this blog post which includes:
And othe changes 🐱👤🐱🏍
Hello Dimitry
I would like to know if there is any parameter (using SerpAPI)
so that we can scrape author profiles with certain minimum number of citations.
Hey @sim777, thank you for your question. SerpApi doesn't has such parameter, and Google Scholar itself (as far as I know) doesn't have it also.
As a workaround you can always do an
ifcondition manually by accessing acited_byhash key from SerpApi response and check if it's bigger or lower to the value you provide. And if condition is true - extract profile.Example code of what I mean:
What parameter can I use in the search query so that I can scrape authors with certain number of citations?
Hey @sim777, I've answered to your question in the response above. I've showed a SerpApi example but you can do the same thing with your own solution without SerpApi 👍
Hi Dmitriy, I noticed that you only scrape the shorted descritions of the papers, but not the entire description. If you look on google scholar search results page, only short excerpt from the abstract, title or authors if there are many is seen ending by a tripple dot (...) The scraper only scrapes this, leaving the rest of the information out. Do you maybe know a solution to this?
Hi, Georg! Thank you reaching out! Unfortunately, only part of the snippet was provided by the Google backend, and as you wrote, this is what scraper scrapes.
To make it work you have to make another request to desired website, check if there's exists the same text as in the snippet from Google Scholar Organic results, and if so, scrape the rest of it.
But this will work if the rest of the text will is on the same website over and over again which in most cases - not. I believe it can be done but it's a tricky task.
All the best,
Dmitriy
@george_z
Hi Dimitriy,
Thank you for the very useful articles!
I was following 'Scrape historic Google Scholar results using Python' article on serpapi.com/blog/scrape-historic-g....
However, whenever I try to call 'cite_results()' I am getting key error: 'citations'. And if I change the query I am getting key error: 'serpapi_pagination'. I also tried to run my script from terminal by running - 'API_KEY=my_api_key python test11.py'. But nothing seems to work especially when I change the query.
Suggestions are highly appreciate.
Thanks.
Hey, @shwetat26 🙂 Thank you for reaching out.
First question, are you actually changing
my_api_keyto your actual API key, and Python filetest11.pyto your actual Python file in theAPI_KEY=my_api_key python test11.pycommand you've shown?It should be something like this:
<your_script.py>to your actual script name.Let me know it makes sense.
Can we scrap the number of citations+year inside the barplot (citation by graph)?
Do you mean value of each individual cell?
@datum_geek the blog post has received major updates including graph extraction if it's something you still need 🙂
Hi @dmitryzub, I facing issues to scrap data on "samsung", for all pages of google scholar. Including title of the publication, authors of the publication, the year, and the full abstract. You code (the first peace) does not work, it reders nothing!
Hi, @datum_geek.
What error do you receive? Pagination, data extraction works as expected without changes. I've just tested in the online IDE that is linked in this post:
Dmitriy, thanks for your tutorial. I'm newbie at python and I already try your script Scrape Google Scholar All Author Articles. I have some questions:
Hey @jayaivan, thank you 🙂
Great questions! We can make a solution for two questions.
Have a look at examples in the online IDE: replit.com/@DimitryZub1/Google-Sch...
We can use
pandasto_csv()method or using Python's build-in context manager and build-incsvlibrary.The main difference is that
pandasis an additional dependency (additional thing to install which leads to larger project storage size), however,pandassimplifies this task a lot.📌Note: I'll be using
json.dumps()at the very end of the code just to show what is being printed (extracted). Delete it if it's unnecessary to you.Using
pandas(don't forget topip installit):Actual example using code in the blog post (the line you're looking for is almost at the end of the script):
Outputs:
Using context manager:
Actual example from the blog post code:
Outputs:
You need a
listof user IDs. Iterate over it at extract the data as already shown in the blog post.Keep in mind that each user = new request. More users = more time to extract data. If it takes a lot of time, think about asynchronous requests as it will speed up things quite a lot.
Iteration over user ID's
listand passinguser_idvalue toparams["user"]which will be passed to search URL:Actual code:
Let me know if any of this makes sense 🙂
Hi, this is very useful article. Definitely reduces the time. I'm planning to get all articles within the last month. Can you tell me how to do that. Below two actions. 1) default display of search is sort by " by relevance". how to set it to "sort by date" 2) there is information on number of days before article published. how to get it?
Hi, @deepeshsagar ! I'm glad that the article helped you somehow!
Use
sortby=pubdatequery parameter which will sort by published date.In articles example the link would look like this:
https://scholar.google.com/citations?hl=en&user=m8dFEawAAAAJ&sortby=pubdateOr you can add a params
dict()to make it more readable and faster to understand:I updated code on replit so you can test in the browser (try to remove
sortbyparam and see the difference in first articles).@deepeshsagar i've just updated blog post and now you're able to extract all available articles from author page. This is possible because of pagination i've added.
🐱👤
Thanks mitry for a great and useful post. I am currently having one problem using your code for "Scrape Google Scholar Organic Results using SerpApi with Pagination". I edited it only, so that it loops thorugh different search terms. However, the code for some reason is not able to get pass the last page of this particular search of one particular query. If I use the code for all the other search terms it works, but for some reason it does not work for only one of the search terms (regardless of the position it has in the loop). The code simply stays forever at saying "Currently extracting page #6" and never adavcnes or ends. I am guessing it has something to do whith what is in the last page, but I havent been able to fix it or identify the problem. Below is a snapshot of what that last page shows. I hope you can help me with this. Thanks!