Prerequisites
Install libraries:
pip install requests parsel google-search-results
Basic knowledge scraping with CSS selectors
CSS selectors declare which part of the markup a style applies to thus allowing to extract data from matching tags and attributes.
If you haven't scraped with CSS selectors, there's a dedicated blog post of mine about how to use CSS selectors when web-scraping that covers what it is, pros and cons, and why they're matter from a web-scraping perspective.
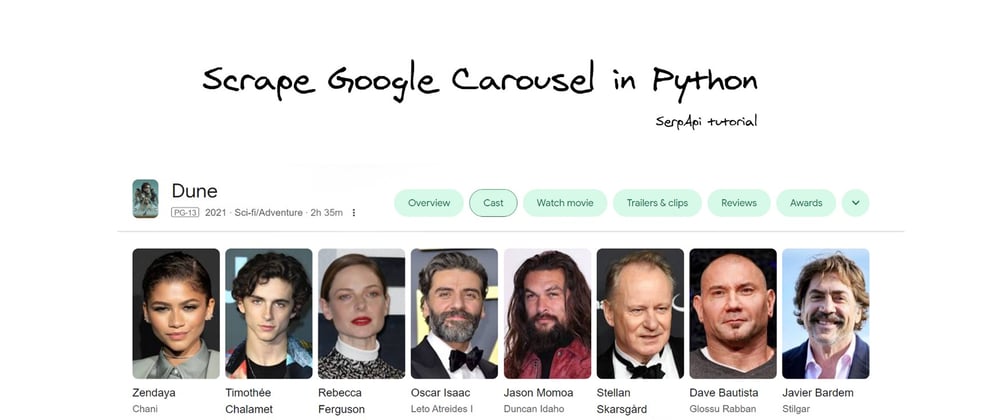
What will be scraped

📌 Note: only such layout will be covered in this blog post. There are at least 3 different Carousel results.
Full Code
import requests, lxml, re, json
from parsel import Selector
# https://docs.python-requests.org/en/master/user/quickstart/#custom-headers
headers = {
"User-agent":
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.83 Safari/537.36"
}
params = {
"q": "dune actors", # search query
"gl": "us", # country to search from
}
def parsel_get_top_carousel():
html = requests.get('https://www.google.com/search', headers=headers, params=params)
selector = Selector(text=html.text)
carousel_name = selector.css(".yKMVIe::text").get()
all_script_tags = selector.css("script::text").getall()
data = {f"{carousel_name}": []}
decoded_thumbnails = []
for _id in selector.css("img.d7ENZc::attr(id)").getall():
# https://regex101.com/r/YGtoJn/1
thumbnails = re.findall(r"var\s?s=\'([^']+)\'\;var\s?ii\=\['{_id}'\];".format(_id=_id), str(all_script_tags))
thumbnail = [
bytes(bytes(img, "ascii").decode("unicode-escape"), "ascii").decode("unicode-escape") for img in thumbnails
]
decoded_thumbnails.append("".join(thumbnail))
for result, image in zip(selector.css('.QjXCXd.X8kvh'), decoded_thumbnails):
title = result.css(".JjtOHd::text").get()
link = f"https://www.google.com{result.css('.QjXCXd div a::attr(href)').get()}"
extensions = result.css(".ellip.AqEFvb::text").getall()
if title and link and extensions is not None:
data[carousel_name].append({
"title": title,
"link": link,
"extensions": extensions,
"thumbnail": image
})
print(json.dumps(data, indent=2, ensure_ascii=False))
parsel_get_top_carousel()
Output:
{
"Dune": [
{
"title": "Zendaya", ... first results
"link": "https://www.google.com/search?gl=us&q=Zendaya&stick=H4sIAAAAAAAAAONgFuLVT9c3NEzLqko2ii8xUOLSz9U3SElJM7So0BLKTrbST8vMyQUTVsmJxSWLWNmjUvNSEisTAY7G9vs7AAAA&sa=X&ved=2ahUKEwjp99fw1972AhXXXM0KHeWoAX4Q9OUBegQIAxAC",
"extensions": [
"Chani"
],
"thumbnail": "data:image/jpeg;base64,/9j/4AAQSkZJRgABAQAAAQABAAD/2wCEAAkGBwgHBgkIBwgKCgkLDRYPDQwMDRsUFRAWIB0iIiAdHx8kKDQsJCYxJx8fLT0tMTU3Ojo6Iys/RD84QzQ5OjcBCgoKDQwNGg8PGjclHyU3Nzc3Nzc3Nzc3Nzc3Nzc3Nzc3Nzc3Nzc3Nzc3Nzc3Nzc3Nzc3Nzc3Nzc3Nzc3Nzc3N//AABEIAL0AfgMBIgACEQEDEQH/xAAbAAACAgMBAAAAAAAAAAAAAAAEBQMGAAEHAv/EAD4QAAIBAwIDBQUFBwIHAQAAAAECAwAEEQUhEjFRBhMiQWEycYGRoRRSscHRFSMzQmLw8UPhBzRygpKy0iT/xAAZAQACAwEAAAAAAAAAAAAAAAAAAQIDBAX/xAAhEQACAwEAAgIDAQAAAAAAAAAAAQIDESESMQRBE1FSYf/aAAwDAQACEQMRAD8A5xW61W6AMrKysoAzFZyoee6WJSQONgcYB8/fSm5vriUlcd2OmaAHElzDH/EkUfGhZtTgT+GS59BSyPuwczIW6771PJb28hBiDRLjk/P4b70aPAn9rR94AqHhPMnypirKwBXcHketV6a0eLxDxoOZA5e/pU0NoZVVlbKZ5DOQfTrS0MHorKAQXtuyc54WHhYDcj9aNU8WxGCOY6HpT0WHqsrdaoAysrKygDK35VqsoAygtSuWhXu4v4jef3R1qa7uPs8fEuC3IZpMJQGMr+Ns5OetA8PKxO2SqnA5s5wBWd0Q2ONSOoIrTySSsWdjny9K1GyKT3is2ehxSALSFnysckjAjLbZxTC20w4Ae4QgHIjWX8siobM28kYAhlAHMq+Afif8/jWNBC8oUsysh9nnj3GotksDDb2kfDxXBR+QAXAO2P7xXow20TrIWQrj2k9lh/UPz236Vu1V5V4QRIoPIrvWrmApgKOJGyeADbGOnx/vFIZKkaxlTAr8DEbnf4H/AH+teO0tqunTQtbBg/COM5yHPrUFtI8E0ZD926sFYMdjjr6dabavObxgzgHbcKcAnzpemS9oVW1wlzHxpseRXoalpRIWtLoyxJhQcOo/A01ikSWNZEOVbkasT0qaw9VlZWUxGDet+lZivEriOJnbkBQAp1SfimwpHh2x+dCLHxY8874rJZC0jSON2JNbijeVuFSCT60ho8qo4uXLrtUgh3I3OB5CjbTT3LDvZI1H3TJg/KrVZ6QXsyp8R4lKODy35VBzSLIwbKpBDNGUV943GVyDhvf/AHtkUZFaPxcaJlR4k4+a74Kn3HPyq0RaJEYo4SMiLiK58gSD+VNLXRy6lihLM5Y7egB/GoOaLFWyoC0eIkkk8OA5889Rj+9qIBkeMzpkOM5B+90/GrJ+xW5hSBGuxxsfX61kWl8fCzpgEZOcf2M4qLsRJVvSrui3ZXC4cDiwB+f98qg1dJY41ZWYAD2lbIHx8vjVqaxiiEjcSPkblRnGOQFINXljIZWjKkDG4I/z9aFPWEoYisGbvz4m4XGxOOY6/wC3yqXTJ+7nMDbBuQ8gfT0oO6CiQmI+HOxFRLKyyK49pTmtCMzLNzrK0jB1VhyYZFbpkTYobUSRZy9McqJqK6jEsfdkbNt9KAK6RuFXBB5cNMLeOXKJGOBSOYOOL1P6UBCG2Kjf86tGmWkkiRlURmU5zjlVc5YiyuOsbaJpIUqyu4YjfhAAz76vWm6VEsWOEZPl60s0iHugOYx5VarEDC1z7Jts6cK0kQ22iAyg43wRnpmnyaKgjGEA2wTUtooXBFHCYg7/AEFTh66Vz3eCqfSI+DHB8MUh1SwZVIJAQcgm2fjV2lk4huc7Uiv8MTtULedRKrvs5vqVs0LhgzRoxxnPn69aSXw8IjvPHGQSCd8fGr3q1mZVdAgZG6iqhdWNzGeCZC/DyyCTj5YNTrmmgsgUnVgp8QjVSNlK7cXvpURzq2azbRmMkIFxvjHL191VqeMqSRuPfWyEtRgsjjHVk3HaRN/SKmqDT/8Akov+mp6tKQY3B8hWd8W2qCvcSl5FRebHAoAAtccbhtsscedXPsxHjA5Cq59jkttXFtOFJ9pSDkHPSrVp00dqvFKSqjoCc/Cs1z30aqVj6XS0t/CpAp3ZJwgVTbXtdbR4VrZwvIEt4j8KdWHa3TX2k72Ijquc/Ksbrl+jd+SP7LpaDwijOAdcVXrTWLWYAwXCMDuN6P8AtZI501LPZBx3qGjxZXY8+lLLq350Pc6xDaLxSyDby9arerduHZu7sYlJPN23+QptefoSfh7HFxBjO1Jbq3GTlQaF+x63qyia4u+4jYZCk4+grTWGo2Kr/wDtSdRzVyfpVbrz7LVZv0Kb7SreduIoDjfBGa592hgjinZEAymfD511ZVL5zjJ54NUG+s1vu2NtaOp4HnAkwP5eZ+gNaKJNPpR8iKaWCjSyTaBWG6Eii8VfO0tqXsrm3j0uO1s7WESwyAjO2NsAbVQ6002/ljuGO+n8Us0Xip7JVa7gD+yZFB3xtmhxW3PChOcbVa+oqTxjy+sJrXUrITyGQhnRCeYAzsevlRimO3uEe6i4kztnlTLWoxPp2l3o/iDDNjzzvn5GmVjp8GoWipLsG6Desfli6bvDZPBLcdqNKgBj/Z8UgHMty/WgZ+0ehXkfClq0UxYAKnFg/EZ/CrJJ2Ds4pFmtlJcHIL+L/FNNL7NrBMkotx3yni4weHB6jHKmp15wi4W70remyRN4oJLiNvNXGSBXQ9Fdri2TDcWBnIrF0W1iQXM6s0yqQvE7EfIk1mhBbaV41GxBx6Zqixp+i+tNIVa5ah5Tx8Z88L5VTbp9VgaW40nS3e2hGXkzw+nM8x7vnXWLeOJ2cSqrK4KsCOYoK97KQSSGWCONc/01KqSzorY/SOSvr+uXaM/7PEYRNzHPIDz57scmmOgXeqalIUZLheE+Lvtiv4Zroi9meIgScPCABhV6UaLCO1hwq4AqU7FnEQhW96yufZjbQ+P2iNzSHR9Inue1U19bkD7OAc46jFWbVpMIal7KWpKzSISrOWJ5YO4AH0qlN+Lw0SS1b9C7/iPM1poBUsQ90yRkem5P/qK5Wrda6D/xZvUmbT7aNgeHjdvTkAPxrndbfjQ8Kzn/ACp+VgLUN2cRgdam5b0JcPxPjpWgznR7N3ueyluZRETHbpkKc8A22z5HGDjy+OAX2au/CEPlXOtG1y60hJ47cI0VwMSK4z8VP8p9RVi7P6us1wXC935Yz6Vmtr4zXTavJHYtMkSRQGpwkEXDkDNU/R7rZd6tFrccS7GsS5xm2cd6hfrMpGBnAoXTPFdA+RGKk1x0+0QxswywJrxpEluk/dyvjByQOdGAgxjwMffTWwuQYdyKXX09mHPBJhf6sCs0yaC7Ev2eQOiEeNTkZ6UlqYSSkujslCM0l1SYYODXq4u+AEBuVJr+8HAcmnKW8CuHj1ijVZMkjNOtNvLHTdOid7m3WN1/eSO4AB6E+VVqZjI5kPsrvXNpG45Gf7zFvnWiqrzXSi+7xfB/201ptW1Jk+zxxpbMY42GC+OnEDgrncdOu9V6srCa2pYsOfJ69YLQMwxIaOoS5XD560xENM9BfFyyZxxDI94pZUkMrQypKntIcik1qGnj06joOoMpEb8xVzsrw8K7865lpl3HcxJPCcHp09Kt1ld/aLde6OJV9dq59sOnRrs4WPULS11VAtz3gK8mjkKEfEUri7HRLLx6ZqF3byjzldplPvDH8CKWPqWuWz4NpARn2lkzt8aMjutclAeIur9EkXFJRkvTL4x8/SH1v2btjHxani/cHnIuEz6Lk/XNMwyW8IjgiWNByVAAB8KqwXWZsm9mZSPvSH8qjW1upZwkl9KU81jJGfjScf8ASTraWsZ3MjXVwUjcBlPiPkKDuogSE5+tHdwsSARgIB5Cl9zKsQZmNQXvhBvgl7R3KWOlzkEAleFfedhXOxTHtRrP7R1AQRH9xCxyfvN/tSyujVHxicy6flLhusrVZmrSoGoe7xkb0T5UHcjElAENZWVugAnT72Wyl44zlT7S9auuj6xG+JYX9GXp76oNT2rXEMiyQhs4yCBnNVzgmWQm4s7PCPttqrIckbqQdxUlv+0IMiOAOfI5xVO7Hdp4zKtvMQj9CefurptjeIwV1I3rDNSg8OlVNtamAwxapPs9uiKfMnemEFg0XikPLyFME1EeztQd/fxohPEPWq29JuUn7AdRuVgjZicVWJnmvpgqA8HkKKuHk1G5AUErnwr+dHW9qsACru38xqSfiRzyOZT6UJNRv4AnDPF+8RlbZhnzFLq6ELJBqF9cld+ER5+JP51SNWtzb38hA8EniH510a3sUcuxZNoErKysqZAHoe8HI0SKgvPZBoADrdMrHQdVvwDbWUpU/wAzDhH1p1a9hrtiPtdwkXVUUk/WjQKrGhkkVBzYgVbk0GRYpJ4HZ+4CYQDmG4uIn3EL/wCVSaj2YstIs1uA80k/GFUuRgfAe6mcffvbRT2jtHLFuCN+JfMEcj7qjLqGn1FYvdK+0fvYMxXKb7bZP6+tEaX201HTP3F3EZeA4znBFWcQC8i7022ZfvQON/erf/VJtS0eK8lCyiWCZf8AUa2cg+/hBrOmnx9NWNdQQvb25uCBFbMCdgCedPbR7y5jWS+8LvyiU5x7z1oHQOzNlZkTyajbySD2T3Uox8ODPxq46fa2kcnEXaZxy4LeXA+agfWqrF/KLq3/AEySws/s8Ayv7xude51K+FMFvoPU004rdQAYpS/qQv0GaCuFPC2Fxnc4pV0OT1+hW/JUVkfYju1CxcC777nqT51XtUs7NVjlv7cyIoIOGKkfKrVLCT5Uj1yIyQd0mzNsvvrd6OdusGg7G2Wo2Ed1aPNbmVeJAW4xjy5/rSq87E6pC2Ie6nXqDwn5H9a6pbwCGFEHJFCivXdqaWgUS07JaaMcNoX9ZXJp1adn7GBgUtYVYeaoKcIgGyjFTKuOVPSJBFbxxjAUZrU9tHP4WHi6jyohyI1yedB37FYO5UlXkGXYc1WkM5/2odprxYVYGGPPD6nlmmHZ5jGvdEbHlnyrxqloftsplQIF4eFfMAg4B+VebGYQFT93n7qkDLJFaRwTGaFMqfaXHL1pujBkBXl9KWafd97bd4q7FuCPPmf0/So4NUL6jNa2UM0wjByyxseNhz4dsbfj7qy20eT2Jrp+T4rJDn7QsQ8RwK2l2JCOE/OvHCsnDKu6vtv5Hy+YrccURYlcK3nTh8eK99I2fJlLkeIIXxbnc1sgVuNcdK3JgDbyrQZgSaFG2H0pNPbBtUs4QM8coYj+lfFn5gU8chQWPIfWlOlH7Z2gmm/lgi4V97HnQBYcYFeDzqVhXiojIEUCsZuEZr0BgULOxJxTImmmSJZbq4bEUQzmgbC+imLzTsoeQ8RBPIeQoftO7cFtZqcRsDI/9WMYH5/AUgKmMZ4iTQhhGuXAkv7ll3BQAH0yKUW8cl3dd1ECQeZr1Plu9kZiS0Z/P9KYWkYiWMLsZAFJ6ZIGakAXf3M1vZiPTo2kuCpht1XG333/AL6DrTTstfW2iswuYHVjEYyigcfMHIB58qXadGXvJbziwY2aGNMbKqkj6nenU8iSP3E0McsZ2Idc0gPWl38N5dyRj93FdlnhXzXB3B9QSD/3HpRk0Tkd6oPGpww9arOuWsOlJBqVopV7WXvEj4iVGRggZ5AjIq4XDFZsj/UTiPvFAAC3TqRnape9Zts+vOt3AV4gSN+oqFhwRjhOCcb+/wDzQAPdSmQ90NgPa/Ss7NR5kvZvvS8Ofd/mvfdBY+IZqTsyvDp2fNpGJpDGp514bnXs868NzpAf/9k="
}, ... other results
{
"title": "Javier Bardem", ... last results
"link": "https://www.google.com/search?gl=us&q=Javier+Bardem&stick=H4sIAAAAAAAAAONgFuLVT9c3NEzLqko2ii8xUOLUz9U3MDQ3NE7WEspOttJPy8zJBRNWyYnFJYtYeb0SyzJTixScEotSUnMBeUccjEAAAAA&sa=X&ved=2ahUKEwjp99fw1972AhXXXM0KHeWoAX4Q9OUBegQIAxAQ",
"extensions": [
"Stilgar"
],
"thumbnail": "data:image/jpeg;base64,/9j/4AAQSkZJRgABAQAAAQABAAD/2wCEAAkGBwgHBgkIBwgKCgkLDRYPDQwMDRsUFRAWIB0iIiAdHx8kKDQsJCYxJx8fLT0tMTU3Ojo6Iys/RD84QzQ5OjcBCgoKDQwNGg8PGjclHyU3Nzc3Nzc3Nzc3Nzc3Nzc3Nzc3Nzc3Nzc3Nzc3Nzc3Nzc3Nzc3Nzc3Nzc3Nzc3Nzc3N//AABEIAL0AfgMBIgACEQEDEQH/xAAcAAACAgMBAQAAAAAAAAAAAAAGBwQFAQIDAAj/xABBEAACAQMCBAMFBgMFBwUAAAABAgMABBEFIQYSMUETUWEicYGRoQcUMkKx8CPB0RVSYnLhFiQzQ4KS8QhzorLC/8QAGQEAAgMBAAAAAAAAAAAAAAAAAwQBAgUA/8QAJBEAAgICAgIBBQEAAAAAAAAAAAECEQMhEjEEQVETIjJhcSP/2gAMAwEAAhEDEQA/AGXz1kOKjB6yHrS4iHIk8wrPNUcNWwao4nWd+as81RZJggYsThRk461wmknADCDmjxuEfL/I7H51FEplg0gUZNcvGVty4Pop6VWGSw5DLNIGGcYdjsfIjsax/aenQr/x0QY2ycVRtIIotloJY+YcrkHyNaXNz4SDkBeRjhUBxzf0FCWt8XQ2kcn3NHnZRsVGx/r8KpH4rvTbrKcLKwPNGHww93v8j/4BPOl0Gjhb7GJDdXMUwiu1T2h7DpnBPdff+u/lU5ZMjIpQWfHN/FcRW2olzE7Bo5HwpUg53BHw60wNL122kmNpcTxpOGIXYgMOoIPTGCO9THPFumRLDJK0X5avc1ci1YL0xVizdHXmr3NXEvWOap4nWRq2xW3LWQtFB7MAVuBXsVS8Saj9wsWd35WYHkjVuUufLNUlKlZeMbdE281G0sUaS4kVfPO+aDNW43CoyWTLGo9lSxyduo+ooH1nWZbiV/HlJJ/KgwFHkM/rVM96PD5AqKCeYc4OenvpKedvodhiUQxi10yTl7hldXHteIwGT+8VRa1rguJeTlYqh25Gxy4652IIz2x571Ux3CyI3tpt05Bvn9iu8EbTvlVCwM5LyEfhG2f0G1Kykw6Qa3dskWgvcYwqpE0OW3ywPs59+RUdHFjcozf821WYpt3blx8t6q7jWn1O4trQNy6fBL49wBtzcgBG/lnp61BfU59R1aa8ucLHMgQhdvDjGAAvkRuff8qGrCl/qWiOfCmtnk+5yZlJf/lHrgZO+d/6eWdDlXVI5fF5PvsEWcou+AB0ByM42owFna3nDcUqIAgHN1ycEAMcnqcn6Cg3hawbTOJruKZmEq25wT0f21XP1qIzOlHei94b4olkEsaXqyyeIPDSQgBl7/ypiQv4sKSY5eYAkeVIxrJrPWbm0uoeW0lmbwZF25Cdxg9j6UbcJapf6dKLPUXeaMfglG6sp6EjsfpmmsOfg99C2XD9RfsP8Vit0xJGrocgjIrUg1pJ30ZzVdngK2C1lRWakgwdh0zS64u1MySzXEiB4YfYgX+8w7n0P8qONYuxa2re2UZgQpG5z6etJDiTWWkmMQVig6djS/kSpUM+PHdlBe3bPI5YcpJ3aoUcTXJABySd2r08kKsGbmd+y52FFPDmkvNCs8i45txjypFjkVZW22i86oozzMwHx7URzaBjR7EE5aeSV98jKDlAOPiTVrFYpGV22XerUWT3UMMrHKKgSMDso2+uM0GdjMIoG7TQIRD4a+yCfaLdXFT34ZijjEsQJBHQ/veiL+z1CI3KSVxgbV0g0yZMuhkCn8rDIqjVoLGkcdLmddBks9lVImG++Mn18gPpWms2ii6hvFDcskMiEr25sHf3ED5V1liazXEq4ikJAdBsPQ+VXAhiurdrYjD74H1/nQU6ZMooFFtLbWQyzKpLICQPNQAT8OvuPyl6bb3EjG2fAvbYlkLfn7MvuP8AMVXQGWw1fwcK0iMMqW5eY9iCe+O3fcUQR3Mc0yXdpy5VcE43BA7/AKH0q/JtA5Rpl5o90n3yS3jz4TpzqpOeRh+IfUGrdhmgiPUEi4ps3jysF03Ky43STcHP77UcN1rV8OfLHXwZXlx4zv5OYNbCtVrfG1OCVgTxzIBKF8YJHGAZmY5CA5wAO7HfbyFJDWJTPdSyu7N7RyT1ps/aas9vK7Q55JlHKD0L9CR7gB8z5mlBrAEcqQj8oyfU0lmdyo0MK+wj2EJubyOMDPM1OfS7LwrOJANwo+Ape8Aad95vGuZF/hxdPLNFOr8T3FoTFYwK8Q/Pg70IYjpF46rLMsAYhM/xGA7eQ9TRbZ20JjTwyAuMY9KVum8axF1XUIlQ/wB5AdqJ7Tim3aIG3ckcwOCfpQpJMPGSDXwYskE99hU+3VXUDAwPIUIS60iC2nZgFdHZs9sEVwh+0TTLfm5uc439kdfd9KpSLMPbnTYby3aOVdmHUUPyaRcaXJG6c0sXMF2O48vnUWy+0fSpmIZJEPQAjP1FFtnfWeqwlY2Vs9VbY/KqSxxkQpyX8FhxXpv3rWUuF5sOoSRGQjmweuD361vYrEv8GOZll5cJJzbEjblbPf8AfrRZxpClpFHdSRCSNThm7jvn6ULavawyMkq48ObAkIGwJAww/flQqaey13tEa8SWAqVRDcI4JCr0PYj40y/xb0tbY6jEUhT+KgbKO6qfl60yLeTxIUbmBJUE/wDitHwX2jP85dMyK3rUCsSjMTAbbVoszkhb/ahqELC1ihkBcFuZM7D/ABfU0m74G41MjBbmJwB5dv0os4weWS7kjXmYJ7HOTknG1VWi2wlmvpiuTHbD6kCs+bvIaMFUKDXgzS/D0AIygNMN8jzqNrd9ZWTyW6LF7LFc4yzn0A/XYUV6VbmLSbeMAqSg/CNxVdd2k0QdI7GN8/mbBb4nOTQ9jFC3utTtp5Sv3Qgg4OExj9aseHRBLqkKDn5ZDjOe9Xb6NfSyZdI4U8hv/OrPSNEEFykjnmwc5xUOJZJrsIrvhtb3htrqEsLi1DMoG4cdxj4Ut4oLKeESuAS+4CnoPU9qfPDik6VyMoGR086U+r8KS6NetE9n4tupzFIgOQO1Aa2MR26McGLY22o7RwmQ/hWSUBj5Y5sD6019OMFwh8OIw3ERHOrR8rj/AE67jbypX6Homg3N8J7+1lZ9ssqSg/Q4pj6bbJavHJYzNNAOYMJZsmNT2HpnsenzzVtJ6IlF1tFnxFaf2jolxCQOdkyPfSgg1kCK1trlcGMNA+RnJUkDb3dvQU6U9qHw222xSW4+4cvU1GQ2iAofbQoQCWJ9e+c10lyYNOlRf27yIvi2xFxCw5nQHJ/zDHX4f6VZ6NqKu8jQluYDBLHPwoB0rU7rRWjXUg8aMzcrFSMHODgH8pIzjtnyori1qKaLni8IknJZH5c/I10JPHKzpRU0MACtwKwBXpCVjYqMkCtxmGL7jTQbWKC+n+7jlMZkzy5HQZx5H19aBuDLRjYXryjO4Qkjc7jG/wAqZw11JIb2G7BkZJmWWMEZCdV2P5cdxVBplxp96t//AGNEFTxRzcw7gDIG/uHxpbJFWmOYm6aYRW1ssdujN+RAF+W9Vl5dRxFixAFTdQvAjw2oPtlSxHoKXXE+thZTDGxLk7CgcqQ5Fe2EVvq337UDaWq+0FLFiKt7OUytPDLHyGLlxJjYhs/Xal5pF1LpuLiKXluWUj2umD+/pUkccSMFiuwI1zu6DZj69/1ruTq2TcbHroESpa4B5lAHSoXEGrLpfhNcWwe2mcpzr1U9gf32pfaX9o7Q2cUGn2j310GwEiOAAOpY9tqtOKuIL/UOGlt73TUt3umVl5JQxj5SG326nb4E0u96CxSU77QXabLb3ic9tLzL+lW6Qho/aUZ6YPlSc4S197W/WJ5OTmIBFN23vPFhVj1xUa9k5Yv0boAiBUzyjYA78vpVFrEPi28jzRiWMLymPGecZ/f091Xkm7OB+YAj31W6rK1vbxxckjCZuUNHsVJ6fCqp9sG1dITHEPD0T3hksrVlySJCcg5OMe4ADHxNXHD/AAeJbcTC5nSNxkKBy759f0oh129ew4jdYrfn5kjib+6rEAn4nP0q/wBHtjFbu9zdqxmcycqjAXONgKPhxrI9gc0/p9F2K2Fa4rYCtNmUCvG2m6H9zN7qtrzFTgOmzZ8vOhjhGDT7ZZYtPkVoklJKgk55guDv7sfOjnizR5da0aW2t5RFcD24XIyAwyMHzBBIPoaTy6br2ia1bTTWF4kEE6GVnKlFQsAfaBwR16jNLZlvocwSpBbqLuNbuG2ylmyr25Tt/rSpvrmIXs0hPNJzfjboPd6U1+IYFku5DzELMnKGU4wPP3dKWV1ohFyOZerYPlml0qGZbo5pONQlJR05icsoODjI+NSX0wNalWjUzjdWJ2G56jz6em/oKsNL4dax1KK7hhWePbnibbvviiEWtnPFJCdPuIrggBTkdd98591TUi0YX6IHCtxa6dZ8sq/7wOYKc9jv+gx8B0waLE12HULXwJ4RNbcvtse3kQR32qvPBglto3tPvRlKsCoJ/Ftgk5xjrQ7xHwpxNps7SWiyQ2i4/imVTnbuAT3oLuw3FJEjWOHHhvQ+n3ICgBlZ8+RJBwNzt+9qYvDV9P8A7NTteKUns1dXz35Rn9mktbTa1Dew3AnIaNlCsV9noBnHfbHyFNzRlk/2PMRGZbhViJIxzZAU/wDxzVMvRXG3dBjpk5uLO2lcAs0alsedSipYsAVABwpxmo2mR+HDGg/KMdKBTx3dG3vLW1tlil8aTwrqRsoRzNggAde4/nQ49Fmreil4j4kW04ov50yYy3J02YqMfGjThfx76xS6kzAJFyIsYI9/771V8IWCNpqSiJS6M+JZCCWO4z8yaM7OAW9vFGPyoAT5mn/GwtVOxLyMyrikdQDW1ZxWQKdsRPYqv1PTY76FkkUE9R5Z7GrECtgKiyVoXfEmm3UFhCkzF5V/Oo/EAaEhbF0fnBLZB5QD1937704OILWKfTZWZBzpghh1G9LpbcG9aN3XmeMnHTJB39+xFLOKUh2E3KFnFlYQLJF1/eK4xape238WIcxUgFcev0qztrFyvhOQqnYDuKs7XhaEIJI7vZiDhos7/A0KUuOhqK9omcP65czkxvCnN6Hb9/0q51SFL3T5EvcKmMtg5xivaXpi2cStJyMVGAyrgkeVTZ4DNZsJPZDYOCdgM5P0oDbZaToW0fDniXi3FwURFk51jA25RtgetFULrdGGJBhEA9kjGf3gV0uIPFueQBgi7ADqQf0qRp9kIY0j2BbcKp3HuoUrkzk0tnbUJpY9Gv5bbaZbdvC2z7RBA+tKqXSNWj00xx2TPzEF8rlk6qSB2P8AX0zTvhgjZUhZcqRg0K6brEFtxBPod6+bqE8qSFcc+RkFtsZII6Uzhw81QDJlcdnfha0kXToXuoLaJggCCEknA7scDerzAA22rpyeQr3ht5U/GkqM+VydmOXFZArbrXgK6zqMctZOACTsB1Jqs1jiTSNFU/2hfRRv2iB5nP8A0jelLxv9okmt+Jb6Z4kOmpsc7NOe5OPy+Q+PlVowcmQGXEHFqX3FOmcNaNOkgkLy3syHmARULBAfXG/w86gN4ZdC4AYbK2Nxnt7qBvsi5rrjC9uH9oxafM+fIkov6E0R6dqaX6MWIE0LtFJ6lSRn6fWgZtNOI948ftaZJvrm4tpPZBHZPZBDVpa6/cxFcBQehzge1uR328s58/fVnbgSoFfPKT1zgj+vuqovlhimaN0UkH2srjf4UB0+wyUlpBto2si5jDSAKwOwx6D+verO9naSIJH+IjPKd9vPHwNA3D9z/GjhR4oSSoHKpycdhnb1oujgC8zKGL9Hd2yze8/CguolmpNmY5WMQjgILHADsST+9qmWSFORS3M2N2I+nuqFA48YquMd8Vw1vXIdLDBCGuOQkDsvvoV2FUPQU2cqy3rxoc+EuX9Ceg+X6ilLx3KY+P7x1JBHh7j/ANtaZ3BtlPa6Mkt7zG7uT403N1BPY+4YHwpScaTifjjUmU+yJgu/+FQv8q0vEVMSzVbSGRw3xPb3kaW97IsdxjAcnaT/AF/WifbypFLP7a8rEHvRfwdxiLaOaz1NneKL/hP1ZRt7Pu/pTGTF7iKp12WfEHH2h6IGQz/ergbeFAc4Pq3QUrOJPtQ1rU+aK1k+5QNsEgPtH3t1+WKX810z5ya0RiNwcufpU3FdEcH7Js91LIWJdmkY+25PStJ5BDbLHnc9qj+Isew9pvpXCVi7czHJNdKZZRGf9g8Qk1TWZMdLRU+bZ/8AzUC5jk0Ti3UbY5CPMZY89w2/65Hwq8/9P8BxrtwR7J8CMH/vJ/lU/wC1HR3SW11eONuVX8GRsbYO4yfQ7f8AVQZxvH/BnA/9KJGmXPiKm/y86ia9DyXBkUDO2RUPR5WCqQaLbTw5Zba4YA+2FYEdDSUuh7jRR8Jgz6zbZBxzZ26Zo4M8dqsvjSBQAep9TVEJ49IvLy45edixEaL0+NUd7d3F7O0lw5PtZx2oXFstVlve62QpjtMgdpMY+VdeENIfWNS+93QL28D5yd+d+v06/L1qBo+ivqbO8rtFZw4M0uN/8qjuT9KLoLttPt1jsj4USbRxjBwPXz99HxYr2VnLXGPYWTypbW7yuQEjUsfcK+db2d73V7u7P/PleQe4nIps8Xa+knAuoTg8su0DhT+YnG1JOCV4ZcsRyNtk+fbNO4Vxi2zOmmnTLTm5N89OhxUNLwx3UhDfiFbXU5WLK5GfMd/nVVJIDhySGPc+VE5A6A8kmt4yw93nWiY3zWSxPWgFzOcnb51414Vhqkgdf2PXVvonBF3qF6SBcXzCNV3aTlRRgD381FFpxVY8QW9xo99ZNDDcDkWRmV+U/lYqRjY4Pel/w7EZdK0ixiYvHBZ+K2P78jsx+QwKuLO2EV2rMpKhvaAOCRnejrGpR2FjFLfsi2tpc6bdG01CFopVPcbMPNT3FXKStGpjU5DDJorv4oNYsjE4GMZilA3RvP8AqO4oMmSWGZon2eMlWwc9KQyYnBj2HIpo2mYyLgnPxrotuWYKgyzkADzNclkGw5dzV9wzCLnWrRWAIV+ff/CCf1AqiRebpNhTPYJp/D8dpFGBykcx/wAXc0N3bvjwoR/EbYHyoz1uQRWbADLOcCh+yslIluZ8hI0LEj3U3j/ERhOtsB+Obhbbh6209HH8a9Y7ndhGg5j/ANz0Dc3Kpzg5G/lUzim6luNf+7vJzLax45c9Hcl2/wDsPlUGUjl74xmrN1oFkfKTZHnkaNRyjnj8h1Xt8v361ykYGBZEIx/mx++laSylGDAZHeuvKlxGvgv4bDJJGMEe75/Oq2UBJe/urwrK1gVBJuK1ethWrVzOHh9llgY9NLSbl4VwfTFX33QR3LAjvUP7OyVsIk6gIBRDfxqsgYdc4rUpJ8QcJO2SVMGn2D3VztFGnMfX0HqelAZna4mknfAaRy5Ge5JJ/WrbjfUJgtlaDaHwRKQPzNnAz7v50OxFj3xWVnnylRpeNCo8vknRnJz60TcEoW1pCvSNHY/LH6kULK5CjzzjNGXAiBIdQnH4wEQHyBz/AKfKgpbL5nUGEt3/AL1PjqibCoOvOtpo0o2HiEL8O9WMKgLmg77V7uS20CURnH8EgHyLHlz9aah+SQg+hN+Ob28urxs/x5mcZ7AnYfAYr0m4PcetethyRBR5AVpcDA222BqjdsqQZonyTE/N3Kk7j51xjR2blxg4zXVzkkDbFdrGMSICThnyc4B6e+oOP//Z"
}
]
}
Code Explanation
Thumbnail extraction

Parsing thumbnails from img.d7ENZc CSS selector to grab src attribute will bring a 1x1 placeholder, instead of actual thumbnail.
Thumbnails are located in the <script> tags. In order to grab them, we need to:
- Locate image element via Dev Tools.
- Copy
idvalue.
- Open page source
CTRL+U, pressCTRL+Fand pasteidvalue to find it.
Most likely you'll see two occurrences, and the second one will be somewhere in the <script> tags. That's what we're looking for.
Now we need to match image id with extracted data:image from the <script> elements to extract the right image:
selector = Selector(text=html.text)
# grabs every script element
all_script_tags = selector.css("script::text").getall()
# list to temporary store thumbnails data
decoded_thumbnails = []
# iterating over each image ID
# using _id because id is a Python build-in name
for _id in selector.css("img.d7ENZc::attr(id)").getall():
# https://regex101.com/r/YGtoJn/1
thumbnails = re.findall(r"var\s?s=\'([^']+)\'\;var\s?ii\=\['{_id}'\];".format(_id=_id), str(all_script_tags))
thumbnail = [
bytes(bytes(img, "ascii").decode("unicode-escape"), "ascii").decode("unicode-escape") for img in thumbnails
]
decoded_thumbnails.append("".join(thumbnail))
| Code | Explanation |
|---|---|
css("img.d7ENZc::attr(id)") |
to grab every image id. |
getall() |
returns a list of matches. |
re.findall() |
to find all matches via regular expression. |
r"<expression>" |
a regular expression. |
([^']+) |
is a regex capture group. |
['{_id}'\] |
is a parsed image id that were passed to regular expression to match the correct image. |
format(_id=_id) |
is a string placeholder. String interpolation would look a bit awkward. |
bytes().deccode() |
to convert unicode characters to ascii characters. |
"".join(thumbnail) |
to join (convert) each element from a list to a string. |
Output from decoded_thumbnails:
# data:image is shortened on purpose,
# so the output would not cover the entire page
[
'data:image/jpeg;base64,/9j/4AAQSkZJRgABAQAAAQABAAD/2wCEAAkGBwgHBgkIBwgKCgkLDRYPDQwMDRsUFRAWIB0iIiAdHx8kKDQsJCYxJx8fLT0tMTU3Ojo6I//AABEIAL0AfgMBIgACEQEDEQH/xAAbAAACAgMBAAAAAAAAAAAAAAAEBQMGAAEHAv/',
"other images ..."
]
Title, link and extensions extraction
The next step is to iterate over CSS container with title, link, and extensions and over decoded_thumbnails:
for result, image in zip(selector.css('.QjXCXd.X8kvh'), decoded_thumbnails):
title = result.css(".JjtOHd::text").get()
link = f"https://www.google.com{result.css('.QjXCXd div a::attr(href)').get()}"
extensions = result.css(".ellip.AqEFvb::text").getall()
| Code | Explanation |
|---|---|
zip() |
allows to iterate over multiple iterables in a single for loop. |
::text |
a parsel pseudo-element to extract textual node data which is identical to XPath <node>/text()
|
::attr(<attribute>) |
a parsel pseudo-element grab attribute data from the node which is identical to XPath <node>/@href
|
get() |
to return first element of actual data. |
getall() |
to return list of all matches. |
The next step is to check if extracted title, link and extensions have some values and append to temporary list and print the data:
data = {f"{carousel_name}": []}
if title and link and extensions is not None:
data[carousel_name].append({
"title": title,
"link": link,
"extensions": extensions,
"thumbnail": image
})
print(json.dumps(data, indent=2, ensure_ascii=False))
Using Google Top Carousel API from SerpApi
SerpApi is a paid API with a free plan which allows end-user to forget about figuring out how to bypass blocks from search entities and focus on the which data to extract.
from serpapi import GoogleSearch
import os, json
def serpapi_get_top_carousel():
params = {
# https://docs.python.org/3/library/os.html#os.getenv
"api_key": os.getenv("API_KEY"), # your SerpApi key in the environment variable
"engine": "google", # search engine
"q": "dune actors", # search query
"hl": "en", # language
"gl": "us" # country
}
search = GoogleSearch(params)
results = search.get_dict()
for result in results['knowledge_graph']['cast']:
print(json.dumps(result, indent=2))
serpapi_get_top_carousel()
Part of the output:
{
"name": "Timothée Chalamet",
"extensions": [
"Paul Atreides"
],
"link": "https://www.google.com/search?hl=en&gl=us&q=Timoth%C3%A9e+Chalamet&stick=H4sIAAAAAAAAAONgFuLVT9c3NEzLqko2ii8xUOLSz9U3KDDKM0wr0BLKTrbST8vMyQUTVsmJxSWPGJcycgu8_HFPWGo246Q1J68xTmHkwqJOyJCLzTWvJLOkUkhQip8L1RIjEahAtll2hpFZXqHAwmWzGJWcjUx2XZp2jk1P8FkoA0Ndb4iDkiLnFCHrhswn7-wFXd__299ywsBBgkWBQYPB8JElq8P6KYwHtBgOMDI17VtxiI2Fg1GAwYpJg6mKiYOFZxGrUEhmbn5JxuGVqQrOGYk5ibmpJRPYGAHILgFT8gAAAA&sa=X&ved=2ahUKEwiMxLi-ksXzAhUAl2oFHf88AN0Q-BZ6BAgBEDQ",
"image": "https://serpapi.com/searches/6165a3dcfa86759a4fa42ba4/images/94afec67f82aa614bb572a123ec09cf051cf10bde8e0bc8025daf21915c49798.jpeg"
} ... other results
Links
Outro
If you have any questions or suggestions, or something isn't working correctly, reach out via Twitter at @dimitryzub or @serp_api.
Yours,
Dimitry, and the rest of SerpApi Team.
Join us on Reddit | Twitter | YouTube
Add a Feature Request💫 or a Bug🐞




Top comments (0)